 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Accuracy: Ensuring Correct Predictions With Correct Rationales
Oct 31, 2024



Large pretrained foundation models demonstrate exceptional performance and, in some high-stakes applications, even surpass human experts. However, most of these models are currently evaluated primarily on prediction accuracy, overlooking the validity of the rationales behind their accurate predictions. For the safe deployment of foundation models, there is a pressing need to ensure double-correct predictions, i.e., correct prediction backed by correct rationales. To achieve this, we propose a two-phase scheme: First, we curate a new dataset that offers structured rationales for visual recognition tasks. Second, we propose a rationale-informed optimization method to guide the model in disentangling and localizing visual evidence for each rationale, without requiring manual annotations. Extensive experiments and ablation studies demonstrate that our model outperforms state-of-the-art models by up to 10.1% in prediction accuracy across a wide range of tasks. Furthermore, our method significantly improves the model's rationale correctness, improving localization by 7.5% and disentanglement by 36.5%. Our dataset, source code, and pretrained weights: https://github.com/deep-real/DCP
DEAL: Disentangle and Localize Concept-level Explanations for VLMs
Jul 19, 2024



Large pre-trained Vision-Language Models (VLMs) have become ubiquitous foundational components of other models and downstream tasks. Although powerful, our empirical results reveal that such models might not be able to identify fine-grained concepts. Specifically, the explanations of VLMs with respect to fine-grained concepts are entangled and mislocalized. To address this issue, we propose to DisEntAngle and Localize (DEAL) the concept-level explanations for VLMs without human annotations. The key idea is encouraging the concept-level explanations to be distinct while maintaining consistency with category-level explanations. We conduct extensive experiments and ablation studies on a wide range of benchmark datasets and vision-language models. Our empirical results demonstrate that the proposed method significantly improves the concept-level explanations of the model in terms of disentanglability and localizability. Surprisingly, the improved explainability alleviates the model's reliance on spurious correlations, which further benefits the prediction accuracy.
Beyond the Federation: Topology-aware Federated Learning for Generalization to Unseen Clients
Jul 06, 2024Federated Learning is widely employed to tackle distributed sensitive data. Existing methods primarily focus on addressing in-federation data heterogeneity. However, we observed that they suffer from significant performance degradation when applied to unseen clients for out-of-federation (OOF) generalization. The recent attempts to address generalization to unseen clients generally struggle to scale up to large-scale distributed settings due to high communication or computation costs. Moreover, methods that scale well often demonstrate poor generalization capability. To achieve OOF-resiliency in a scalable manner, we propose Topology-aware Federated Learning (TFL) that leverages client topology - a graph representing client relationships - to effectively train robust models against OOF data. We formulate a novel optimization problem for TFL, consisting of two key modules: Client Topology Learning, which infers the client relationships in a privacy-preserving manner, and Learning on Client Topology, which leverages the learned topology to identify influential clients and harness this information into the FL optimization process to efficiently build robust models. Empirical evaluation on a variety of real-world datasets verifies TFL's superior OOF robustness and scalability.
Are Data-driven Explanations Robust against Out-of-distribution Data?
Mar 29, 2023As black-box models increasingly power high-stakes applications, a variety of data-driven explanation methods have been introduced. Meanwhile, machine learning models are constantly challenged by distributional shifts. A question naturally arises: Are data-driven explanations robust against out-of-distribution data? Our empirical results show that even though predict correctly, the model might still yield unreliable explanations under distributional shifts. How to develop robust explanations against out-of-distribution data? To address this problem, we propose an end-to-end model-agnostic learning framework Distributionally Robust Explanations (DRE). The key idea is, inspired by self-supervised learning, to fully utilizes the inter-distribution information to provide supervisory signals for the learning of explanations without human annotation. Can robust explanations benefit the model's generalization capability? We conduct extensive experiments on a wide range of tasks and data types, including classification and regression on image and scientific tabular data. Our results demonstrate that the proposed method significantly improves the model's performance in terms of explanation and prediction robustness against distributional shifts.
Are Multimodal Transformers Robust to Missing Modality?
Apr 12, 2022



Multimodal data collected from the real world are often imperfect due to missing modalities. Therefore multimodal models that are robust against modal-incomplete data are highly preferred. Recently, Transformer models have shown great success in processing multimodal data. However, existing work has been limited to either architecture designs or pre-training strategies; whether Transformer models are naturally robust against missing-modal data has rarely been investigated. In this paper, we present the first-of-its-kind work to comprehensively investigate the behavior of Transformers in the presence of modal-incomplete data. Unsurprising, we find Transformer models are sensitive to missing modalities while different modal fusion strategies will significantly affect the robustness. What surprised us is that the optimal fusion strategy is dataset dependent even for the same Transformer model; there does not exist a universal strategy that works in general cases. Based on these findings, we propose a principle method to improve the robustness of Transformer models by automatically searching for an optimal fusion strategy regarding input data. Experimental validations on three benchmarks support the superior performance of the proposed method.
SMIL: Multimodal Learning with Severely Missing Modality
Mar 09, 2021

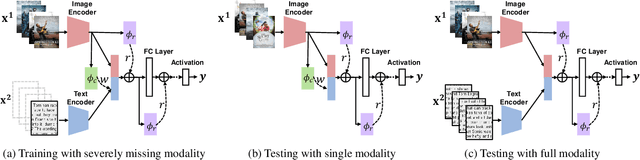

A common assumption in multimodal learning is the completeness of training data, i.e., full modalities are available in all training examples. Although there exists research endeavor in developing novel methods to tackle the incompleteness of testing data, e.g., modalities are partially missing in testing examples, few of them can handle incomplete training modalities. The problem becomes even more challenging if considering the case of severely missing, e.g., 90% training examples may have incomplete modalities. For the first time in the literature, this paper formally studies multimodal learning with missing modality in terms of flexibility (missing modalities in training, testing, or both) and efficiency (most training data have incomplete modality). Technically, we propose a new method named SMIL that leverages Bayesian meta-learning in uniformly achieving both objectives. To validate our idea, we conduct a series of experiments on three popular benchmarks: MM-IMDb, CMU-MOSI, and avMNIST. The results prove the state-of-the-art performance of SMIL over existing methods and generative baselines including autoencoders and generative adversarial networks. Our code is available at https://github.com/mengmenm/SMIL.
HSR: L1/2 Regularized Sparse Representation for Fast Face Recognition using Hierarchical Feature Selection
Sep 23, 2014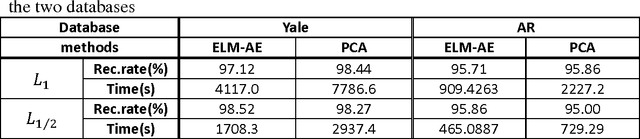


In this paper, we propose a novel method for fast face recognition called L1/2 Regularized Sparse Representation using Hierarchical Feature Selection (HSR). By employing hierarchical feature selection, we can compress the scale and dimension of global dictionary, which directly contributes to the decrease of computational cost in sparse representation that our approach is strongly rooted in. It consists of Gabor wavelets and Extreme Learning Machine Auto-Encoder (ELM-AE) hierarchically. For Gabor wavelets part, local features can be extracted at multiple scales and orientations to form Gabor-feature based image, which in turn improves the recognition rate. Besides, in the presence of occluded face image, the scale of Gabor-feature based global dictionary can be compressed accordingly because redundancies exist in Gabor-feature based occlusion dictionary. For ELM-AE part, the dimension of Gabor-feature based global dictionary can be compressed because high-dimensional face images can be rapidly represented by low-dimensional feature. By introducing L1/2 regularization, our approach can produce sparser and more robust representation compared to regularized Sparse Representation based Classification (SRC), which also contributes to the decrease of the computational cost in sparse representation. In comparison with related work such as SRC and Gabor-feature based SRC (GSRC), experimental results on a variety of face databases demonstrate the great advantage of our method for computational cost. Moreover, we also achieve approximate or even better recognition rate.
RMSE-ELM: Recursive Model based Selective Ensemble of Extreme Learning Machines for Robustness Improvement
Sep 23, 2014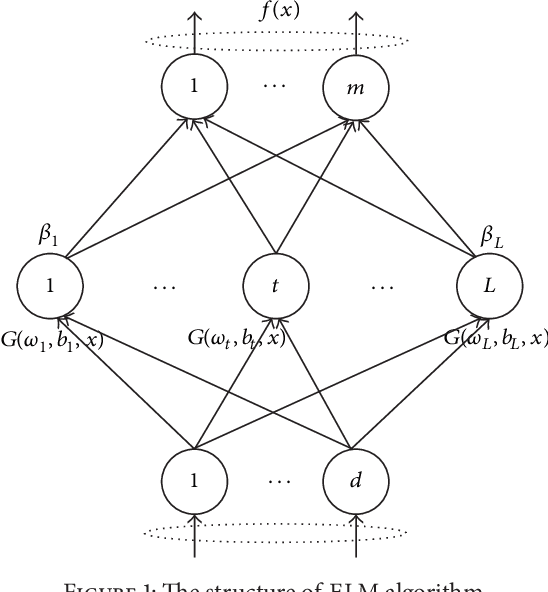



Extreme learning machine (ELM) as an emerging branch of shallow networks has shown its excellent generalization and fast learning speed. However, for blended data, the robustness of ELM is weak because its weights and biases of hidden nodes are set randomly. Moreover, the noisy data exert a negative effect. To solve this problem, a new framework called RMSE-ELM is proposed in this paper. It is a two-layer recursive model. In the first layer, the framework trains lots of ELMs in different groups concurrently, then employs selective ensemble to pick out an optimal set of ELMs in each group, which can be merged into a large group of ELMs called candidate pool. In the second layer, selective ensemble is recursively used on candidate pool to acquire the final ensemble. In the experiments, we apply UCI blended datasets to confirm the robustness of our new approach in two key aspects (mean square error and standard deviation). The space complexity of our method is increased to some degree, but the results have shown that RMSE-ELM significantly improves robustness with slightly computational time compared with representative methods (ELM, OP-ELM, GASEN-ELM, GASEN-BP and E-GASEN). It becomes a potential framework to solve robustness issue of ELM for high-dimensional blended data in the future.
LARSEN-ELM: Selective Ensemble of Extreme Learning Machines using LARS for Blended Data
Aug 27, 2014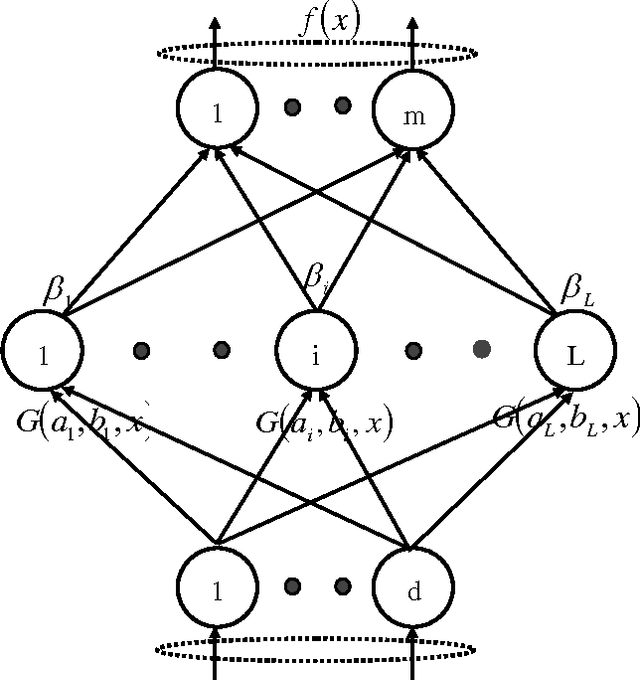
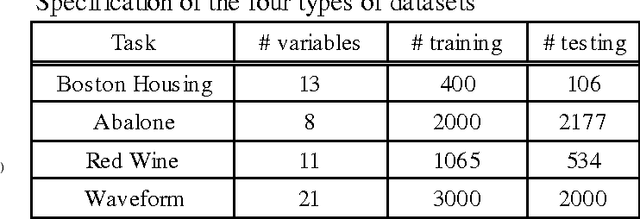
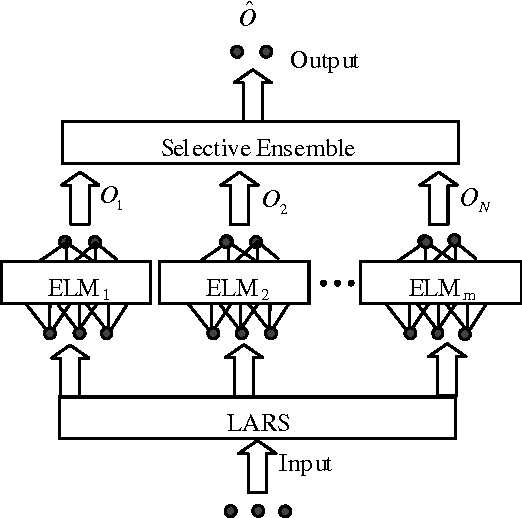

Extreme learning machine (ELM) as a neural network algorithm has shown its good performance, such as fast speed, simple structure etc, but also, weak robustness is an unavoidable defect in original ELM for blended data. We present a new machine learning framework called LARSEN-ELM for overcoming this problem. In our paper, we would like to show two key steps in LARSEN-ELM. In the first step, preprocessing, we select the input variables highly related to the output using least angle regression (LARS). In the second step, training, we employ Genetic Algorithm (GA) based selective ensemble and original ELM. In the experiments, we apply a sum of two sines and four datasets from UCI repository to verify the robustness of our approach. The experimental results show that compared with original ELM and other methods such as OP-ELM, GASEN-ELM and LSBoost, LARSEN-ELM significantly improve robustness performance while keeping a relatively high speed.
* Accepted for publication in Neurocomputing, 01/19/2014