 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLeW: Facet-Level and Adaptive Weighted Representation Learning of Scientific Documents
Sep 09, 2025Scientific document representation learning provides powerful embeddings for various tasks, while current methods face challenges across three approaches. 1) Contrastive training with citation-structural signals underutilizes citation information and still generates single-vector representations. 2) Fine-grained representation learning, which generates multiple vectors at the sentence or aspect level, requires costly integration and lacks domain generalization. 3) Task-aware learning depends on manually predefined task categorization, overlooking nuanced task distinctions and requiring extra training data for task-specific modules. To address these problems, we propose a new method that unifies the three approaches for better representations, namely FLeW. Specifically, we introduce a novel triplet sampling method that leverages citation intent and frequency to enhance citation-structural signals for training. Citation intents (background, method, result), aligned with the general structure of scientific writing, facilitate a domain-generalized facet partition for fine-grained representation learning. Then, we adopt a simple weight search to adaptively integrate three facet-level embeddings into a task-specific document embedding without task-aware fine-tuning. Experiments show the applicability and robustness of FLeW across multiple scientific tasks and fields, compared to prior models.
AI-Assisted NLOS Sensing for RIS-Based Indoor Localization in Smart Factories
May 21, 2025In the era of Industry 4.0, precise indoor localization is vital for automation and efficiency in smart factories. Reconfigurable Intelligent Surfaces (RIS) are emerging as key enablers in 6G networks for joint sensing and communication. However, RIS faces significant challenges in Non-Line-of-Sight (NLOS) and multipath propagation, particularly in localization scenarios, where detecting NLOS conditions is crucial for ensuring not only reliable results and increased connectivity but also the safety of smart factory personnel. This study introduces an AI-assisted framework employing a Convolutional Neural Network (CNN) customized for accurate Line-of-Sight (LOS) and Non-Line-of-Sight (NLOS) classification to enhance RIS-based localization using measured, synthetic, mixed-measured, and mixed-synthetic experimental data, that is, original, augmented, slightly noisy, and highly noisy data, respectively. Validated through such data from three different environments, the proposed customized-CNN (cCNN) model achieves {95.0\%-99.0\%} accuracy, outperforming standard pre-trained models like Visual Geometry Group 16 (VGG-16) with an accuracy of {85.5\%-88.0\%}. By addressing RIS limitations in NLOS scenarios, this framework offers scalable and high-precision localization solutions for 6G-enabled smart factories.
Towards Physical Understanding in Video Generation: A 3D Point Regularization Approach
Feb 05, 2025We present a novel video generation framework that integrates 3-dimensional geometry and dynamic awareness. To achieve this, we augment 2D videos with 3D point trajectories and align them in pixel space. The resulting 3D-aware video dataset, PointVid, is then used to fine-tune a latent diffusion model, enabling it to track 2D objects with 3D Cartesian coordinates. Building on this, we regularize the shape and motion of objects in the video to eliminate undesired artifacts, \eg, nonphysical deformation. Consequently, we enhance the quality of generated RGB videos and alleviate common issues like object morphing, which are prevalent in current video models due to a lack of shape awareness. With our 3D augmentation and regularization, our model is capable of handling contact-rich scenarios such as task-oriented videos. These videos involve complex interactions of solids, where 3D information is essential for perceiving deformation and contact. Furthermore, our model improves the overall quality of video generation by promoting the 3D consistency of moving objects and reducing abrupt changes in shape and motion.
Wonderland: Navigating 3D Scenes from a Single Image
Dec 16, 2024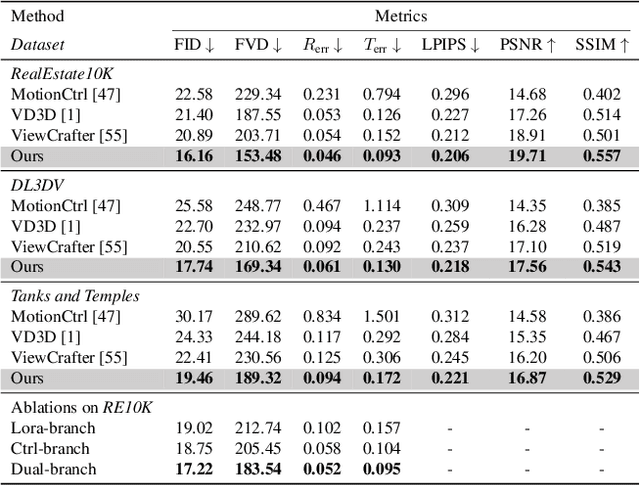
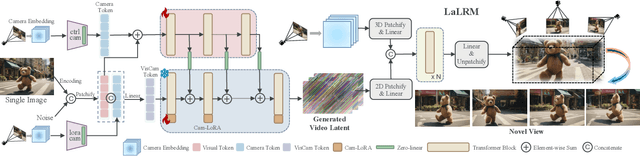
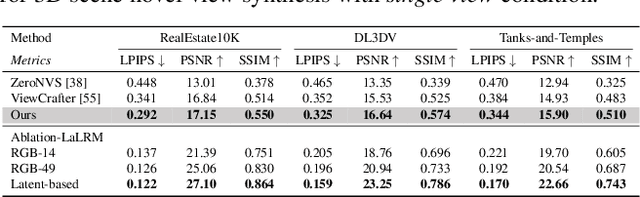

This paper addresses a challenging question: How can we efficiently create high-quality, wide-scope 3D scenes from a single arbitrary image? Existing methods face several constraints, such as requiring multi-view data, time-consuming per-scene optimization, low visual quality in backgrounds, and distorted reconstructions in unseen areas. We propose a novel pipeline to overcome these limitations. Specifically, we introduce a large-scale reconstruction model that uses latents from a video diffusion model to predict 3D Gaussian Splattings for the scenes in a feed-forward manner. The video diffusion model is designed to create videos precisely following specified camera trajectories, allowing it to generate compressed video latents that contain multi-view information while maintaining 3D consistency. We train the 3D reconstruction model to operate on the video latent space with a progressive training strategy, enabling the efficient generation of high-quality, wide-scope, and generic 3D scenes. Extensive evaluations across various datasets demonstrate that our model significantly outperforms existing methods for single-view 3D scene generation, particularly with out-of-domain images. For the first time, we demonstrate that a 3D reconstruction model can be effectively built upon the latent space of a diffusion model to realize efficient 3D scene generation.
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
Dec 13, 2024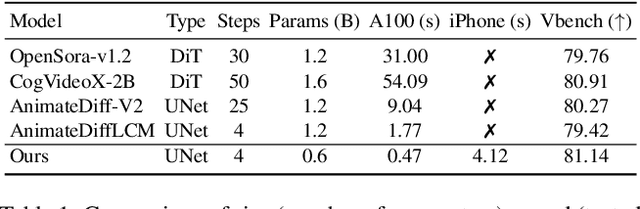
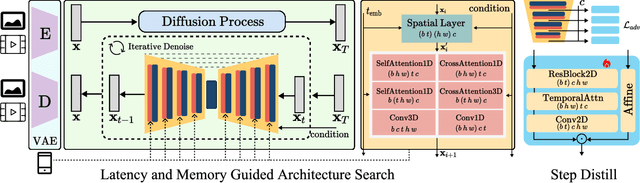
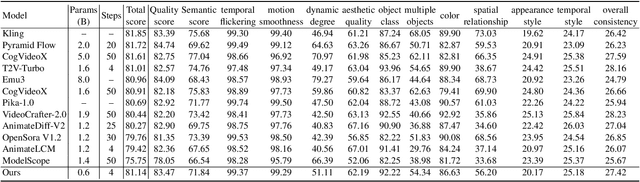
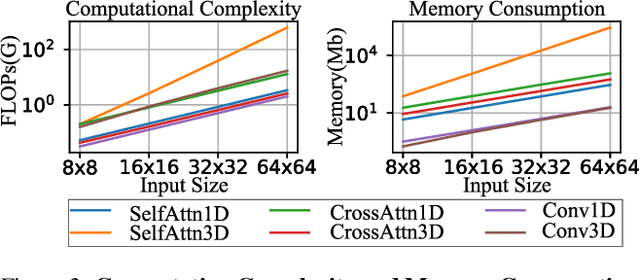
We have witnessed the unprecedented success of diffusion-based video generation over the past year. Recently proposed models from the community have wielded the power to generate cinematic and high-resolution videos with smooth motions from arbitrary input prompts. However, as a supertask of image generation, video generation models require more computation and are thus hosted mostly on cloud servers, limiting broader adoption among content creators. In this work, we propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. From the network architecture scope, we initialize from a compact image backbone and search out the design and arrangement of temporal layers to maximize hardware efficiency. In addition, we propose a dedicated adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. Compared to server-side models that take minutes on powerful GPUs to generate a single video, we accelerate the generation by magnitudes while delivering on-par quality.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
AsCAN: Asymmetric Convolution-Attention Networks for Efficient Recognition and Generation
Nov 07, 2024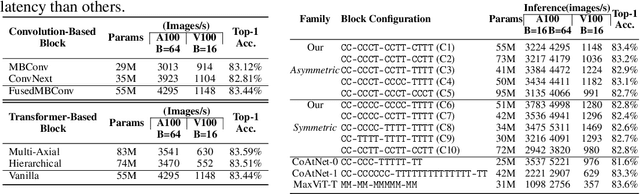
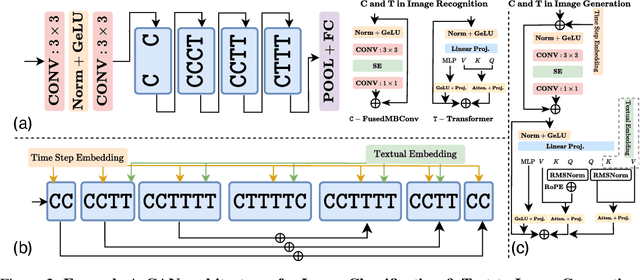
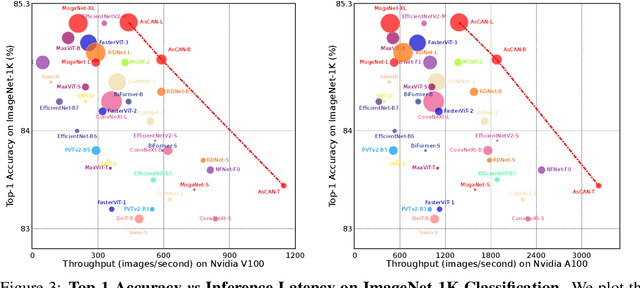
Neural network architecture design requires making many crucial decisions. The common desiderata is that similar decisions, with little modifications, can be reused in a variety of tasks and applications. To satisfy that, architectures must provide promising latency and performance trade-offs, support a variety of tasks, scale efficiently with respect to the amounts of data and compute, leverage available data from other tasks, and efficiently support various hardware. To this end, we introduce AsCAN -- a hybrid architecture, combining both convolutional and transformer blocks. We revisit the key design principles of hybrid architectures and propose a simple and effective \emph{asymmetric} architecture, where the distribution of convolutional and transformer blocks is \emph{asymmetric}, containing more convolutional blocks in the earlier stages, followed by more transformer blocks in later stages. AsCAN supports a variety of tasks: recognition, segmentation, class-conditional image generation, and features a superior trade-off between performance and latency. We then scale the same architecture to solve a large-scale text-to-image task and show state-of-the-art performance compared to the most recent public and commercial models. Notably, even without any computation optimization for transformer blocks, our models still yield faster inference speed than existing works featuring efficient attention mechanisms, highlighting the advantages and the value of our approach.
Scalable Ranked Preference Optimization for Text-to-Image Generation
Oct 23, 2024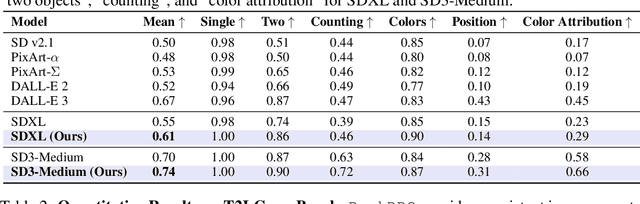
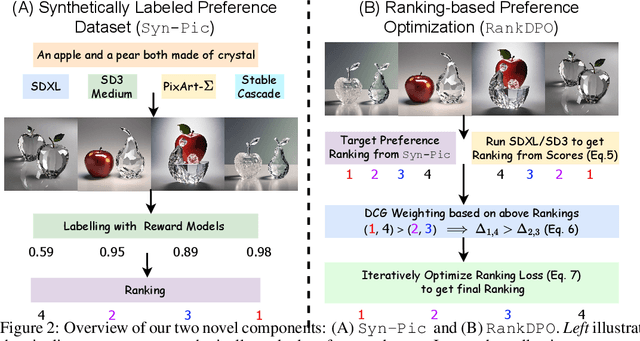

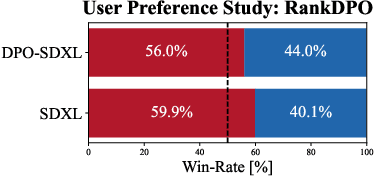
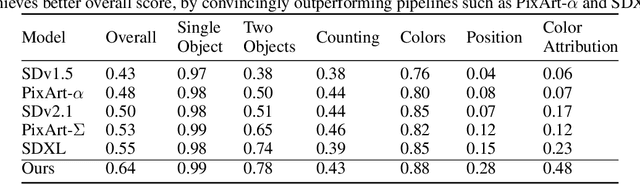
Direct Preference Optimization (DPO) has emerged as a powerful approach to align text-to-image (T2I) models with human feedback. Unfortunately, successful application of DPO to T2I models requires a huge amount of resources to collect and label large-scale datasets, e.g., millions of generated paired images annotated with human preferences. In addition, these human preference datasets can get outdated quickly as the rapid improvements of T2I models lead to higher quality images. In this work, we investigate a scalable approach for collecting large-scale and fully synthetic datasets for DPO training. Specifically, the preferences for paired images are generated using a pre-trained reward function, eliminating the need for involving humans in the annotation process, greatly improving the dataset collection efficiency. Moreover, we demonstrate that such datasets allow averaging predictions across multiple models and collecting ranked preferences as opposed to pairwise preferences. Furthermore, we introduce RankDPO to enhance DPO-based methods using the ranking feedback. Applying RankDPO on SDXL and SD3-Medium models with our synthetically generated preference dataset ``Syn-Pic'' improves both prompt-following (on benchmarks like T2I-Compbench, GenEval, and DPG-Bench) and visual quality (through user studies). This pipeline presents a practical and scalable solution to develop better preference datasets to enhance the performance of text-to-image models.
ControlMM: Controllable Masked Motion Generation
Oct 14, 2024Recent advances in motion diffusion models have enabled spatially controllable text-to-motion generation. However, despite achieving acceptable control precision, these models suffer from generation speed and fidelity limitations. To address these challenges, we propose ControlMM, a novel approach incorporating spatial control signals into the generative masked motion model. ControlMM achieves real-time, high-fidelity, and high-precision controllable motion generation simultaneously. Our approach introduces two key innovations. First, we propose masked consistency modeling, which ensures high-fidelity motion generation via random masking and reconstruction, while minimizing the inconsistency between the input control signals and the extracted control signals from the generated motion. To further enhance control precision, we introduce inference-time logit editing, which manipulates the predicted conditional motion distribution so that the generated motion, sampled from the adjusted distribution, closely adheres to the input control signals. During inference, ControlMM enables parallel and iterative decoding of multiple motion tokens, allowing for high-speed motion generation. Extensive experiments show that, compared to the state of the art, ControlMM delivers superior results in motion quality, with better FID scores (0.061 vs 0.271), and higher control precision (average error 0.0091 vs 0.0108). ControlMM generates motions 20 times faster than diffusion-based methods. Additionally, ControlMM unlocks diverse applications such as any joint any frame control, body part timeline control, and obstacle avoidance. Video visualization can be found at https://exitudio.github.io/ControlMM-page
Efficient Training with Denoised Neural Weights
Jul 16, 2024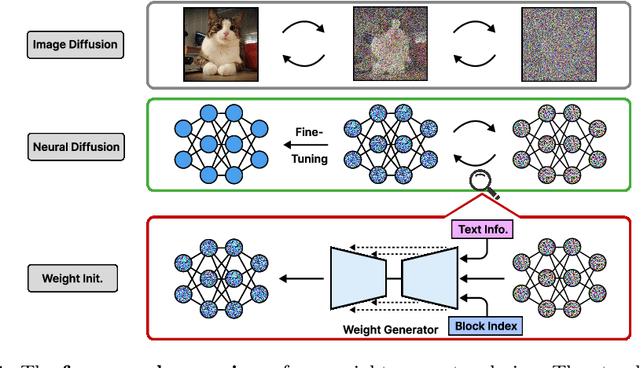
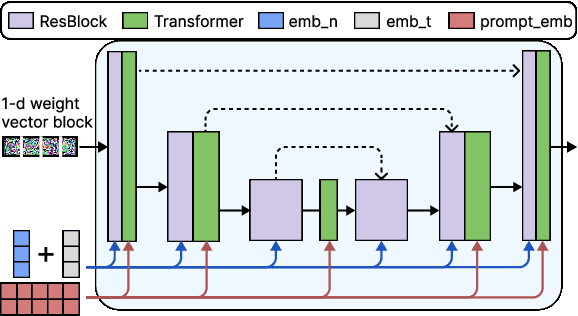
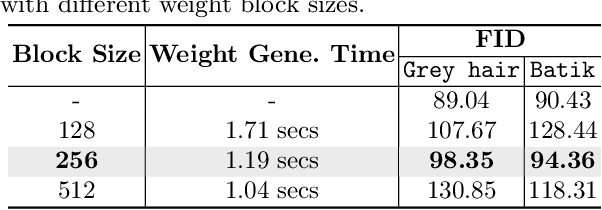
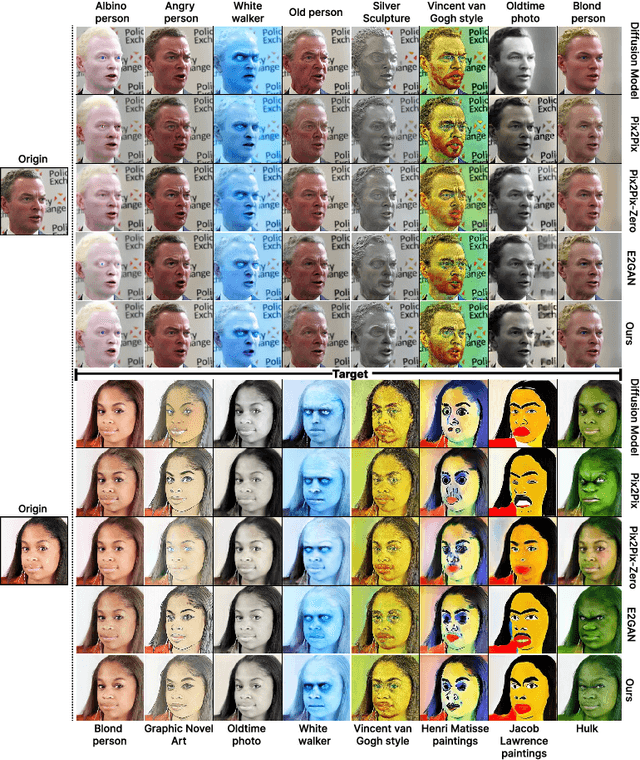
Good weight initialization serves as an effective measure to reduce the training cost of a deep neural network (DNN) model. The choice of how to initialize parameters is challenging and may require manual tuning, which can be time-consuming and prone to human error. To overcome such limitations, this work takes a novel step towards building a weight generator to synthesize the neural weights for initialization. We use the image-to-image translation task with generative adversarial networks (GANs) as an example due to the ease of collecting model weights spanning a wide range. Specifically, we first collect a dataset with various image editing concepts and their corresponding trained weights, which are later used for the training of the weight generator. To address the different characteristics among layers and the substantial number of weights to be predicted, we divide the weights into equal-sized blocks and assign each block an index. Subsequently, a diffusion model is trained with such a dataset using both text conditions of the concept and the block indexes. By initializing the image translation model with the denoised weights predicted by our diffusion model, the training requires only 43.3 seconds. Compared to training from scratch (i.e., Pix2pix), we achieve a 15x training time acceleration for a new concept while obtaining even better image generation quality.