 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2DiT: Sandwich Diffusion Transformer for Mobile Streaming Video Generation
Jan 19, 2026Diffusion Transformers (DiTs) have recently improved video generation quality. However, their heavy computational cost makes real-time or on-device generation infeasible. In this work, we introduce S2DiT, a Streaming Sandwich Diffusion Transformer designed for efficient, high-fidelity, and streaming video generation on mobile hardware. S2DiT generates more tokens but maintains efficiency with novel efficient attentions: a mixture of LinConv Hybrid Attention (LCHA) and Stride Self-Attention (SSA). Based on this, we uncover the sandwich design via a budget-aware dynamic programming search, achieving superior quality and efficiency. We further propose a 2-in-1 distillation framework that transfers the capacity of large teacher models (e.g., Wan 2.2-14B) to the compact few-step sandwich model. Together, S2DiT achieves quality on par with state-of-the-art server video models, while streaming at over 10 FPS on an iPhone.
SnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices
Jan 13, 2026Recent advances in diffusion transformers (DiTs) have set new standards in image generation, yet remain impractical for on-device deployment due to their high computational and memory costs. In this work, we present an efficient DiT framework tailored for mobile and edge devices that achieves transformer-level generation quality under strict resource constraints. Our design combines three key components. First, we propose a compact DiT architecture with an adaptive global-local sparse attention mechanism that balances global context modeling and local detail preservation. Second, we propose an elastic training framework that jointly optimizes sub-DiTs of varying capacities within a unified supernetwork, allowing a single model to dynamically adjust for efficient inference across different hardware. Finally, we develop Knowledge-Guided Distribution Matching Distillation, a step-distillation pipeline that integrates the DMD objective with knowledge transfer from few-step teacher models, producing high-fidelity and low-latency generation (e.g., 4-step) suitable for real-time on-device use. Together, these contributions enable scalable, efficient, and high-quality diffusion models for deployment on diverse hardware.
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
Dec 13, 2024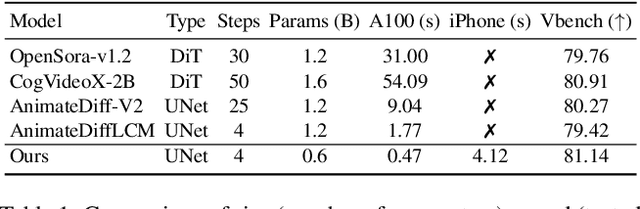
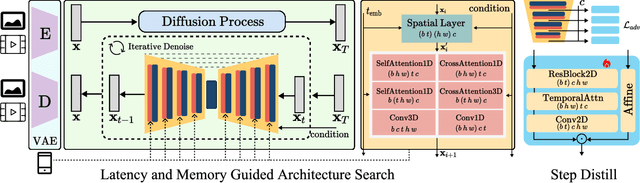
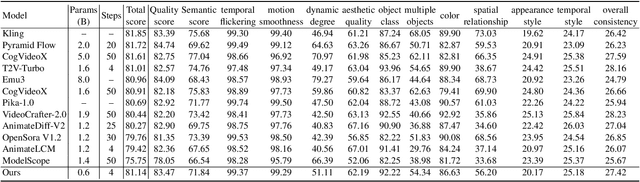
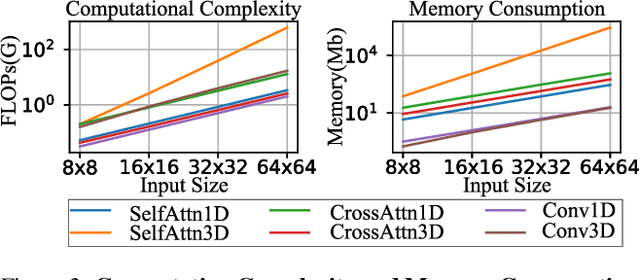
We have witnessed the unprecedented success of diffusion-based video generation over the past year. Recently proposed models from the community have wielded the power to generate cinematic and high-resolution videos with smooth motions from arbitrary input prompts. However, as a supertask of image generation, video generation models require more computation and are thus hosted mostly on cloud servers, limiting broader adoption among content creators. In this work, we propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. From the network architecture scope, we initialize from a compact image backbone and search out the design and arrangement of temporal layers to maximize hardware efficiency. In addition, we propose a dedicated adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. Compared to server-side models that take minutes on powerful GPUs to generate a single video, we accelerate the generation by magnitudes while delivering on-par quality.
FaSTExt: Fast and Small Text Extractor
Aug 14, 2019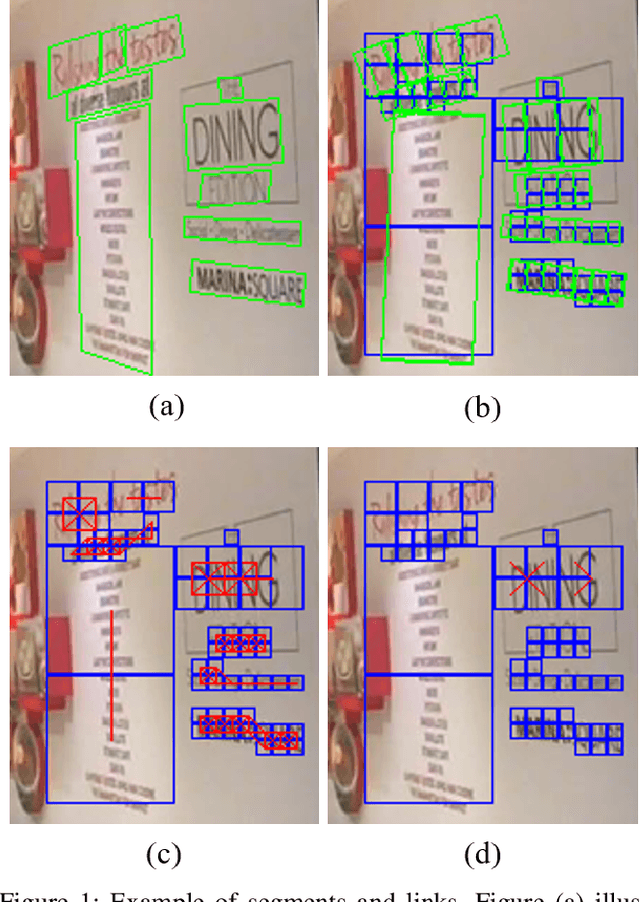

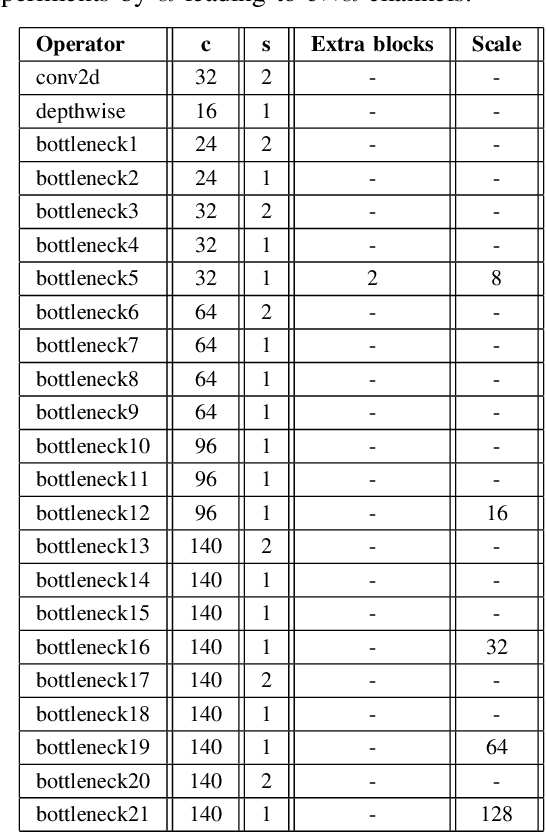
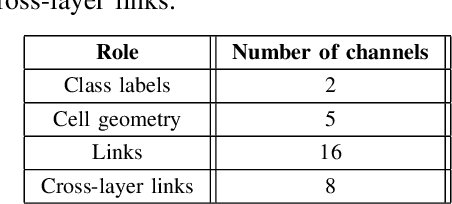
Text detection in natural images is a challenging but necessary task for many applications. Existing approaches utilize large deep convolutional neural networks making it difficult to use them in real-world tasks. We propose a small yet relatively precise text extraction method. The basic component of it is a convolutional neural network which works in a fully-convolutional manner and produces results at multiple scales. Each scale output predicts whether a pixel is a part of some word, its geometry, and its relation to neighbors at the same scale and between scales. The key factor of reducing the complexity of the model was the utilization of depthwise separable convolution, linear bottlenecks, and inverted residuals. Experiments on public datasets show that the proposed network can effectively detect text while keeping the number of parameters in the range of 1.58 to 10.59 million in different configurations.