 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices
Jan 13, 2026Recent advances in diffusion transformers (DiTs) have set new standards in image generation, yet remain impractical for on-device deployment due to their high computational and memory costs. In this work, we present an efficient DiT framework tailored for mobile and edge devices that achieves transformer-level generation quality under strict resource constraints. Our design combines three key components. First, we propose a compact DiT architecture with an adaptive global-local sparse attention mechanism that balances global context modeling and local detail preservation. Second, we propose an elastic training framework that jointly optimizes sub-DiTs of varying capacities within a unified supernetwork, allowing a single model to dynamically adjust for efficient inference across different hardware. Finally, we develop Knowledge-Guided Distribution Matching Distillation, a step-distillation pipeline that integrates the DMD objective with knowledge transfer from few-step teacher models, producing high-fidelity and low-latency generation (e.g., 4-step) suitable for real-time on-device use. Together, these contributions enable scalable, efficient, and high-quality diffusion models for deployment on diverse hardware.
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
Dec 13, 2024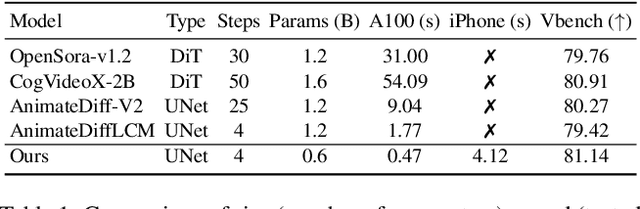
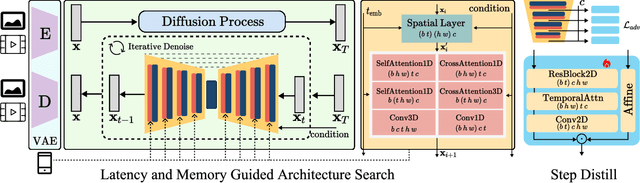
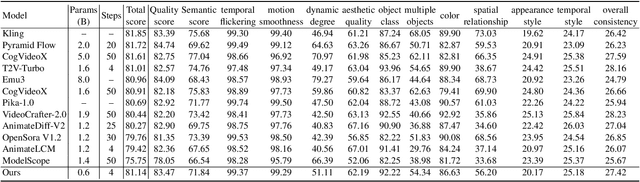
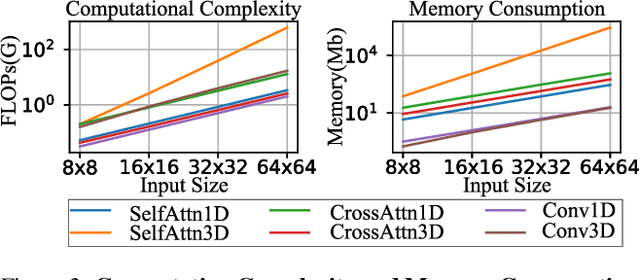
We have witnessed the unprecedented success of diffusion-based video generation over the past year. Recently proposed models from the community have wielded the power to generate cinematic and high-resolution videos with smooth motions from arbitrary input prompts. However, as a supertask of image generation, video generation models require more computation and are thus hosted mostly on cloud servers, limiting broader adoption among content creators. In this work, we propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. From the network architecture scope, we initialize from a compact image backbone and search out the design and arrangement of temporal layers to maximize hardware efficiency. In addition, we propose a dedicated adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. Compared to server-side models that take minutes on powerful GPUs to generate a single video, we accelerate the generation by magnitudes while delivering on-par quality.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
Slicing Vision Transformer for Flexible Inference
Dec 06, 2024Vision Transformers (ViT) is known for its scalability. In this work, we target to scale down a ViT to fit in an environment with dynamic-changing resource constraints. We observe that smaller ViTs are intrinsically the sub-networks of a larger ViT with different widths. Thus, we propose a general framework, named Scala, to enable a single network to represent multiple smaller ViTs with flexible inference capability, which aligns with the inherent design of ViT to vary from widths. Concretely, Scala activates several subnets during training, introduces Isolated Activation to disentangle the smallest sub-network from other subnets, and leverages Scale Coordination to ensure each sub-network receives simplified, steady, and accurate learning objectives. Comprehensive empirical validations on different tasks demonstrate that with only one-shot training, Scala learns slimmable representation without modifying the original ViT structure and matches the performance of Separate Training. Compared with the prior art, Scala achieves an average improvement of 1.6% on ImageNet-1K with fewer parameters.
AsCAN: Asymmetric Convolution-Attention Networks for Efficient Recognition and Generation
Nov 07, 2024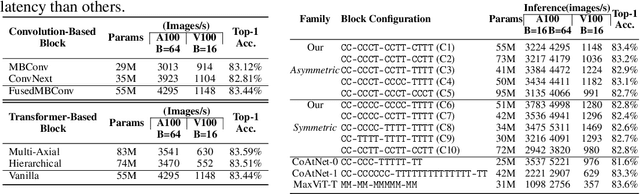
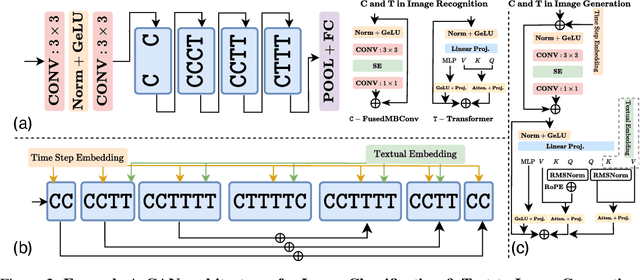
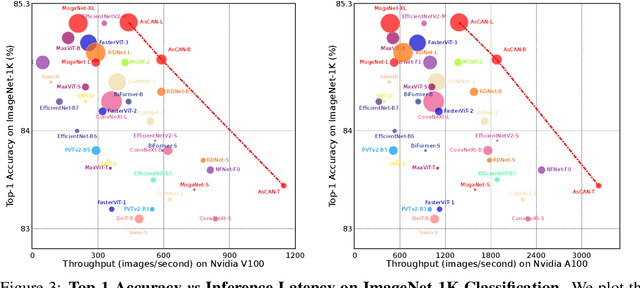
Neural network architecture design requires making many crucial decisions. The common desiderata is that similar decisions, with little modifications, can be reused in a variety of tasks and applications. To satisfy that, architectures must provide promising latency and performance trade-offs, support a variety of tasks, scale efficiently with respect to the amounts of data and compute, leverage available data from other tasks, and efficiently support various hardware. To this end, we introduce AsCAN -- a hybrid architecture, combining both convolutional and transformer blocks. We revisit the key design principles of hybrid architectures and propose a simple and effective \emph{asymmetric} architecture, where the distribution of convolutional and transformer blocks is \emph{asymmetric}, containing more convolutional blocks in the earlier stages, followed by more transformer blocks in later stages. AsCAN supports a variety of tasks: recognition, segmentation, class-conditional image generation, and features a superior trade-off between performance and latency. We then scale the same architecture to solve a large-scale text-to-image task and show state-of-the-art performance compared to the most recent public and commercial models. Notably, even without any computation optimization for transformer blocks, our models still yield faster inference speed than existing works featuring efficient attention mechanisms, highlighting the advantages and the value of our approach.
Scalable Ranked Preference Optimization for Text-to-Image Generation
Oct 23, 2024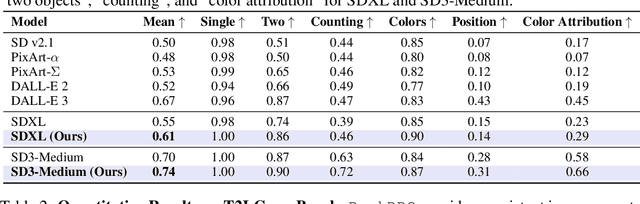
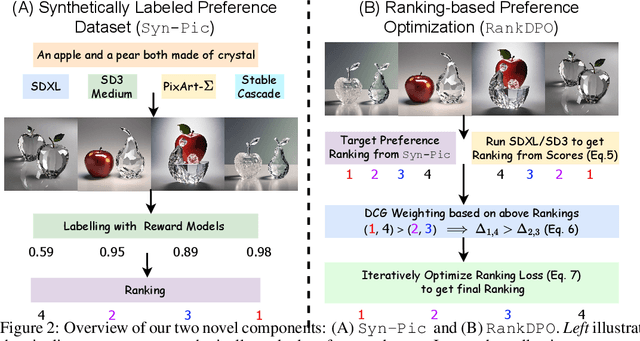

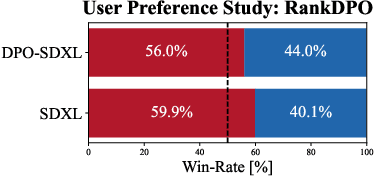
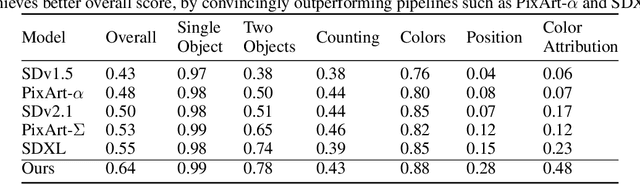
Direct Preference Optimization (DPO) has emerged as a powerful approach to align text-to-image (T2I) models with human feedback. Unfortunately, successful application of DPO to T2I models requires a huge amount of resources to collect and label large-scale datasets, e.g., millions of generated paired images annotated with human preferences. In addition, these human preference datasets can get outdated quickly as the rapid improvements of T2I models lead to higher quality images. In this work, we investigate a scalable approach for collecting large-scale and fully synthetic datasets for DPO training. Specifically, the preferences for paired images are generated using a pre-trained reward function, eliminating the need for involving humans in the annotation process, greatly improving the dataset collection efficiency. Moreover, we demonstrate that such datasets allow averaging predictions across multiple models and collecting ranked preferences as opposed to pairwise preferences. Furthermore, we introduce RankDPO to enhance DPO-based methods using the ranking feedback. Applying RankDPO on SDXL and SD3-Medium models with our synthetically generated preference dataset ``Syn-Pic'' improves both prompt-following (on benchmarks like T2I-Compbench, GenEval, and DPG-Bench) and visual quality (through user studies). This pipeline presents a practical and scalable solution to develop better preference datasets to enhance the performance of text-to-image models.
GOCA: Guided Online Cluster Assignment for Self-Supervised Video Representation Learning
Jul 20, 2022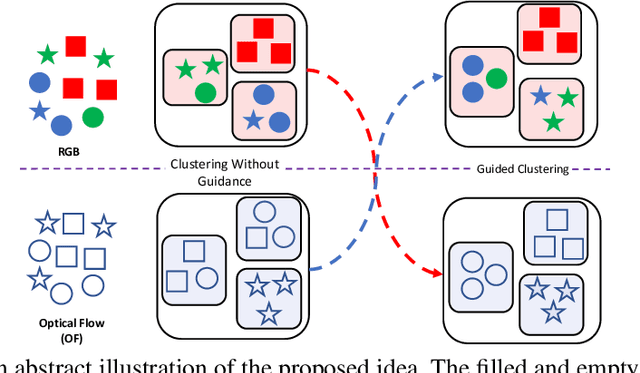
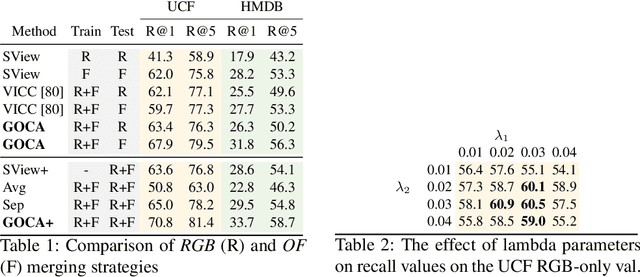
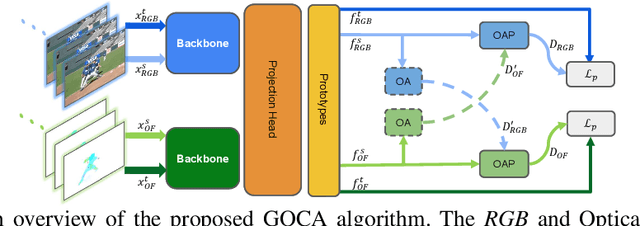

Clustering is a ubiquitous tool in unsupervised learning. Most of the existing self-supervised representation learning methods typically cluster samples based on visually dominant features. While this works well for image-based self-supervision, it often fails for videos, which require understanding motion rather than focusing on background. Using optical flow as complementary information to RGB can alleviate this problem. However, we observe that a naive combination of the two views does not provide meaningful gains. In this paper, we propose a principled way to combine two views. Specifically, we propose a novel clustering strategy where we use the initial cluster assignment of each view as prior to guide the final cluster assignment of the other view. This idea will enforce similar cluster structures for both views, and the formed clusters will be semantically abstract and robust to noisy inputs coming from each individual view. Additionally, we propose a novel regularization strategy to address the feature collapse problem, which is common in cluster-based self-supervised learning methods. Our extensive evaluation shows the effectiveness of our learned representations on downstream tasks, e.g., video retrieval and action recognition. Specifically, we outperform the state of the art by 7% on UCF and 4% on HMDB for video retrieval, and 5% on UCF and 6% on HMDB for video classification
Transformers in Action: Weakly Supervised Action Segmentation
Jan 20, 2022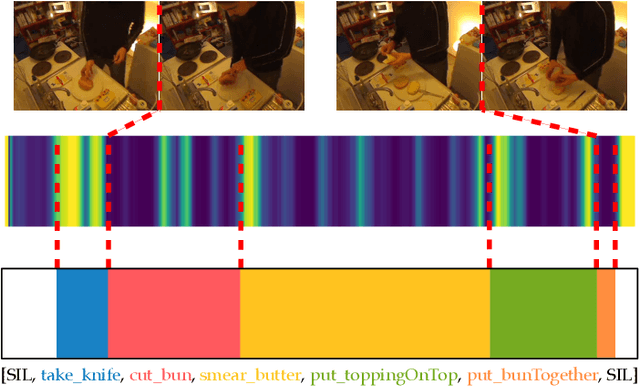
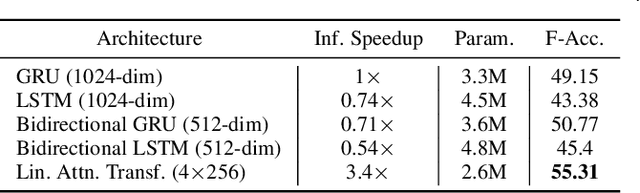
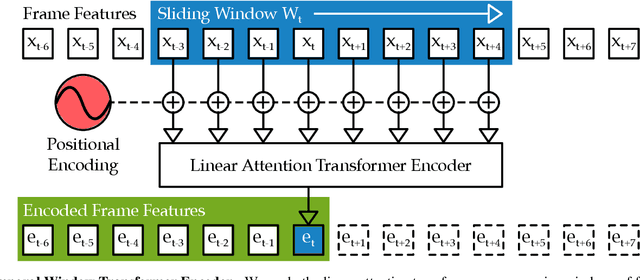
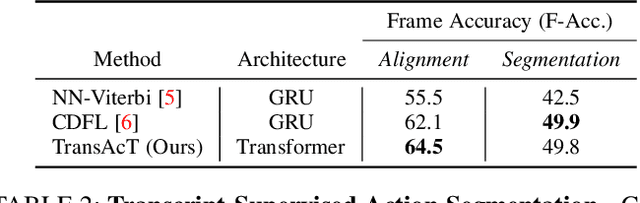
The video action segmentation task is regularly explored under weaker forms of supervision, such as transcript supervision, where a list of actions is easier to obtain than dense frame-wise labels. In this formulation, the task presents various challenges for sequence modeling approaches due to the emphasis on action transition points, long sequence lengths, and frame contextualization, making the task well-posed for transformers. Given developments enabling transformers to scale linearly, we demonstrate through our architecture how they can be applied to improve action alignment accuracy over the equivalent RNN-based models with the attention mechanism focusing around salient action transition regions. Additionally, given the recent focus on inference-time transcript selection, we propose a supplemental transcript embedding approach to select transcripts more quickly at inference-time. Furthermore, we subsequently demonstrate how this approach can also improve the overall segmentation performance. Finally, we evaluate our proposed methods across the benchmark datasets to better understand the applicability of transformers and the importance of transcript selection on this video-driven weakly-supervised task.
Learning to Align Sequential Actions in the Wild
Nov 17, 2021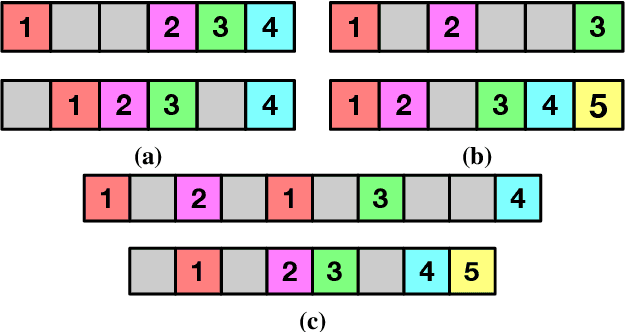
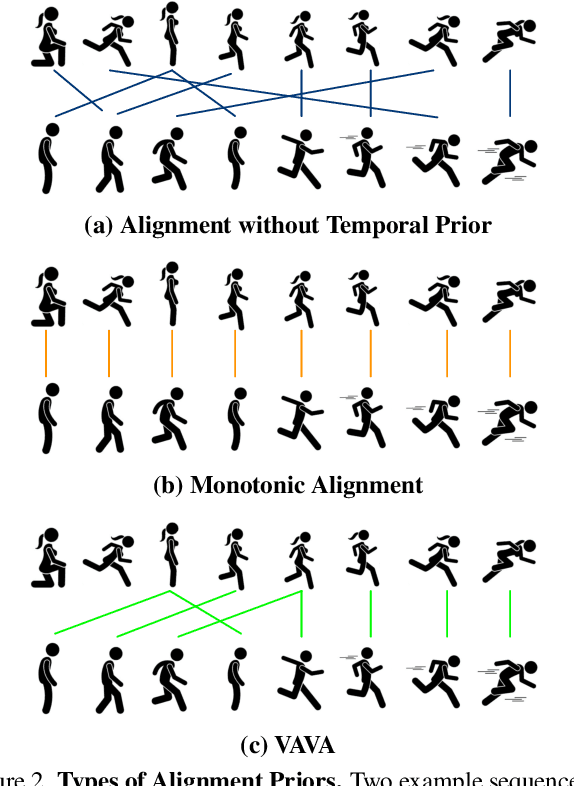
State-of-the-art methods for self-supervised sequential action alignment rely on deep networks that find correspondences across videos in time. They either learn frame-to-frame mapping across sequences, which does not leverage temporal information, or assume monotonic alignment between each video pair, which ignores variations in the order of actions. As such, these methods are not able to deal with common real-world scenarios that involve background frames or videos that contain non-monotonic sequence of actions. In this paper, we propose an approach to align sequential actions in the wild that involve diverse temporal variations. To this end, we propose an approach to enforce temporal priors on the optimal transport matrix, which leverages temporal consistency, while allowing for variations in the order of actions. Our model accounts for both monotonic and non-monotonic sequences and handles background frames that should not be aligned. We demonstrate that our approach consistently outperforms the state-of-the-art in self-supervised sequential action representation learning on four different benchmark datasets.
Learning by Aligning Videos in Time
Mar 31, 2021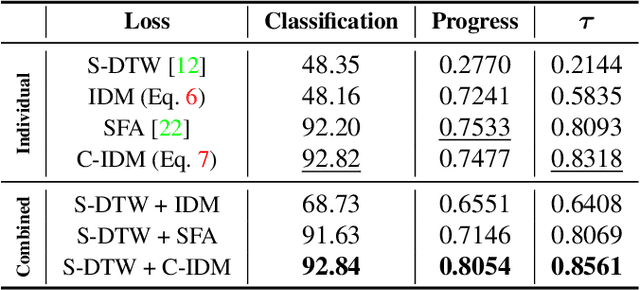
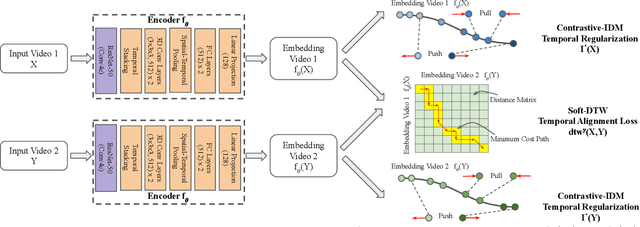
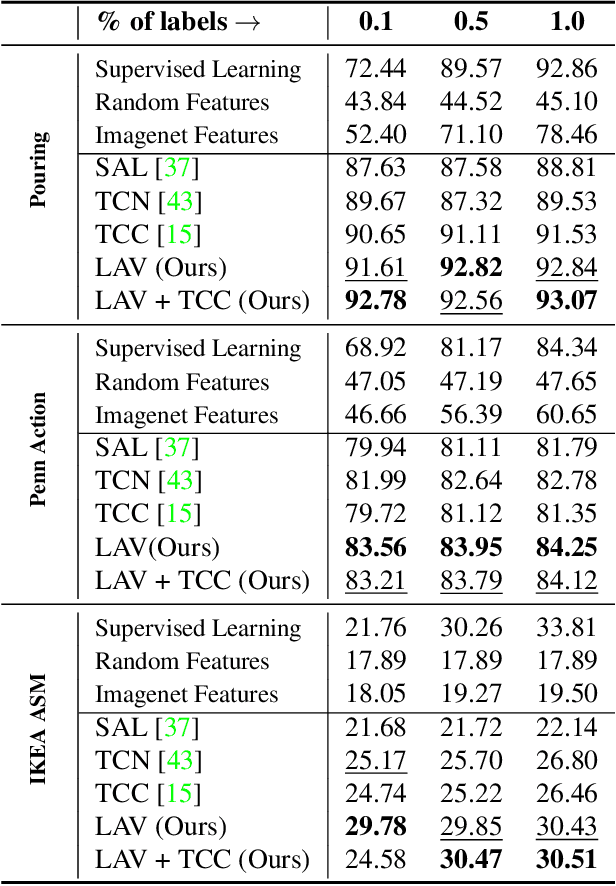
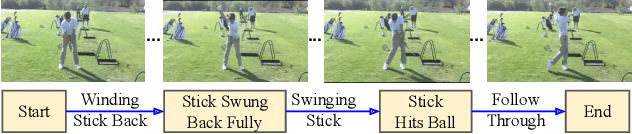
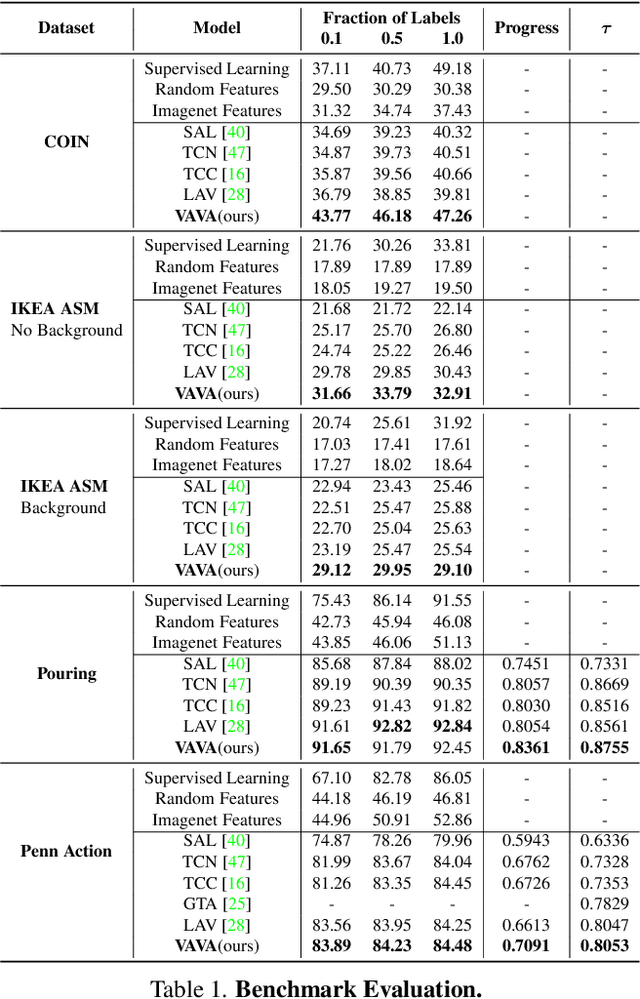
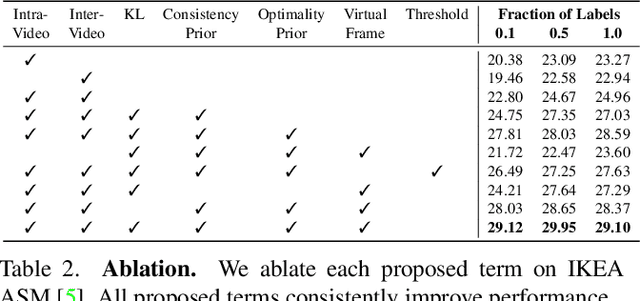
We present a self-supervised approach for learning video representations using temporal video alignment as a pretext task, while exploiting both frame-level and video-level information. We leverage a novel combination of temporal alignment loss and temporal regularization terms, which can be used as supervision signals for training an encoder network. Specifically, the temporal alignment loss (i.e., Soft-DTW) aims for the minimum cost for temporally aligning videos in the embedding space. However, optimizing solely for this term leads to trivial solutions, particularly, one where all frames get mapped to a small cluster in the embedding space. To overcome this problem, we propose a temporal regularization term (i.e., Contrastive-IDM) which encourages different frames to be mapped to different points in the embedding space. Extensive evaluations on various tasks, including action phase classification, action phase progression, and fine-grained frame retrieval, on three datasets, namely Pouring, Penn Action, and IKEA ASM, show superior performance of our approach over state-of-the-art methods for self-supervised representation learning from videos. In addition, our method provides significant performance gain where labeled data is lacking.