 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Children: Improving Image-Caption Pretraining via Curriculum
May 30, 2023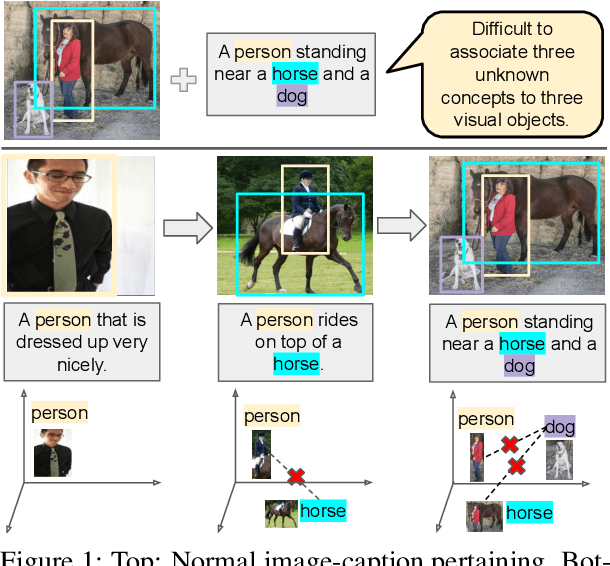
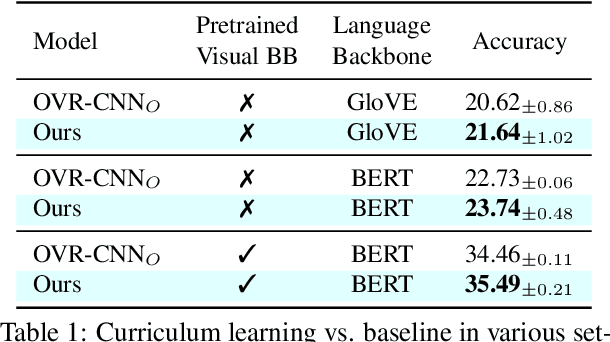
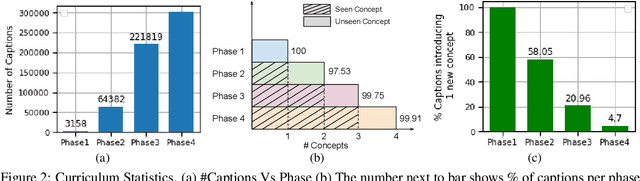

Image-caption pretraining has been quite successfully used for downstream vision tasks like zero-shot image classification and object detection. However, image-caption pretraining is still a hard problem -- it requires multiple concepts (nouns) from captions to be aligned to several objects in images. To tackle this problem, we go to the roots -- the best learner, children. We take inspiration from cognitive science studies dealing with children's language learning to propose a curriculum learning framework. The learning begins with easy-to-align image caption pairs containing one concept per caption. The difficulty is progressively increased with each new phase by adding one more concept per caption. Correspondingly, the knowledge acquired in each learning phase is utilized in subsequent phases to effectively constrain the learning problem to aligning one new concept-object pair in each phase. We show that this learning strategy improves over vanilla image-caption training in various settings -- pretraining from scratch, using a pretrained image or/and pretrained text encoder, low data regime etc.
GOCA: Guided Online Cluster Assignment for Self-Supervised Video Representation Learning
Jul 20, 2022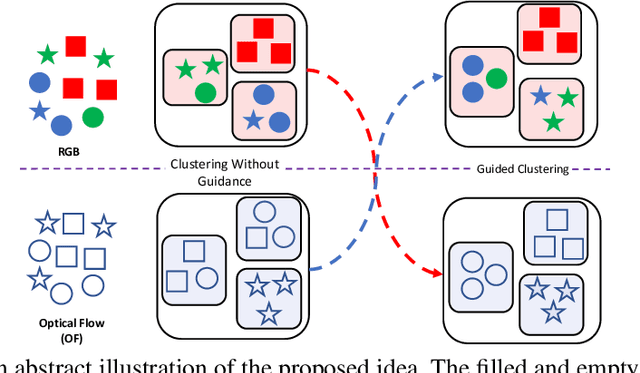
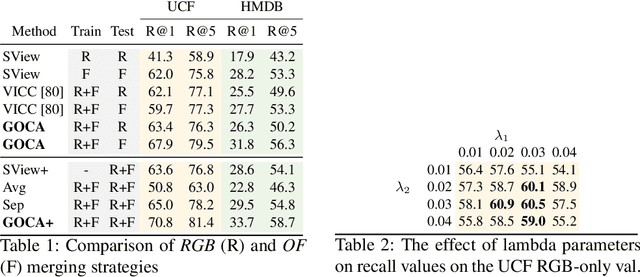

Clustering is a ubiquitous tool in unsupervised learning. Most of the existing self-supervised representation learning methods typically cluster samples based on visually dominant features. While this works well for image-based self-supervision, it often fails for videos, which require understanding motion rather than focusing on background. Using optical flow as complementary information to RGB can alleviate this problem. However, we observe that a naive combination of the two views does not provide meaningful gains. In this paper, we propose a principled way to combine two views. Specifically, we propose a novel clustering strategy where we use the initial cluster assignment of each view as prior to guide the final cluster assignment of the other view. This idea will enforce similar cluster structures for both views, and the formed clusters will be semantically abstract and robust to noisy inputs coming from each individual view. Additionally, we propose a novel regularization strategy to address the feature collapse problem, which is common in cluster-based self-supervised learning methods. Our extensive evaluation shows the effectiveness of our learned representations on downstream tasks, e.g., video retrieval and action recognition. Specifically, we outperform the state of the art by 7% on UCF and 4% on HMDB for video retrieval, and 5% on UCF and 6% on HMDB for video classification
SGEITL: Scene Graph Enhanced Image-Text Learning for Visual Commonsense Reasoning
Dec 16, 2021


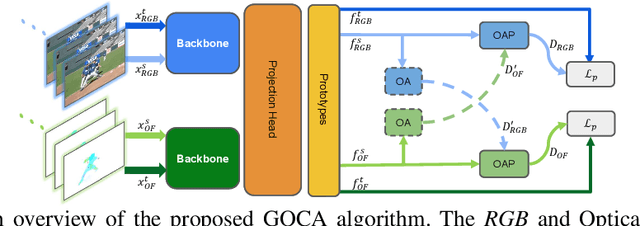
Answering complex questions about images is an ambitious goal for machine intelligence, which requires a joint understanding of images, text, and commonsense knowledge, as well as a strong reasoning ability. Recently, multimodal Transformers have made great progress in the task of Visual Commonsense Reasoning (VCR), by jointly understanding visual objects and text tokens through layers of cross-modality attention. However, these approaches do not utilize the rich structure of the scene and the interactions between objects which are essential in answering complex commonsense questions. We propose a Scene Graph Enhanced Image-Text Learning (SGEITL) framework to incorporate visual scene graphs in commonsense reasoning. To exploit the scene graph structure, at the model structure level, we propose a multihop graph transformer for regularizing attention interaction among hops. As for pre-training, a scene-graph-aware pre-training method is proposed to leverage structure knowledge extracted in the visual scene graph. Moreover, we introduce a method to train and generate domain-relevant visual scene graphs using textual annotations in a weakly-supervised manner. Extensive experiments on VCR and other tasks show a significant performance boost compared with the state-of-the-art methods and prove the efficacy of each proposed component.
* AAAI 2022
Open-Vocabulary Object Detection Using Captions
Nov 20, 2020
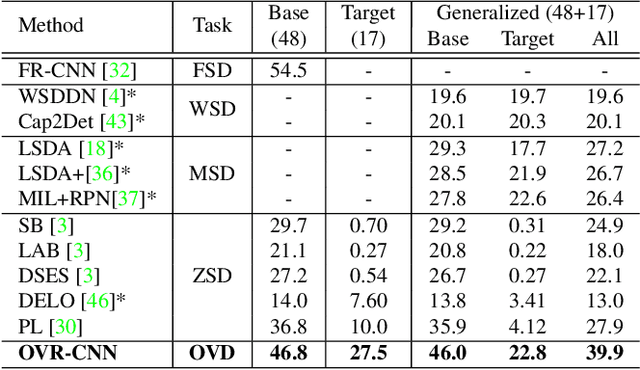
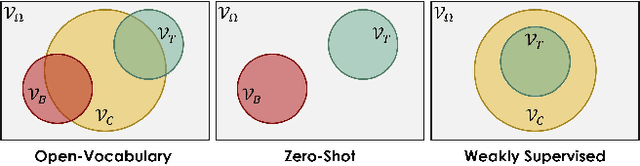
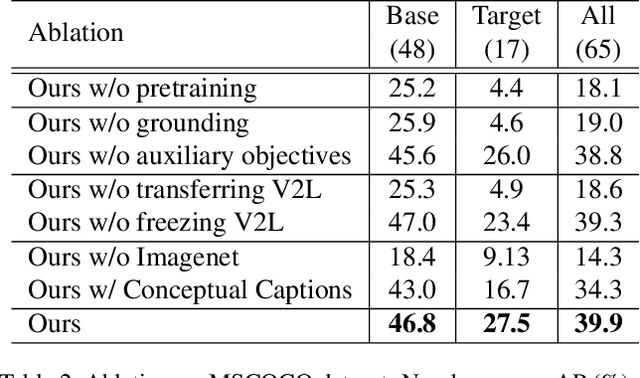
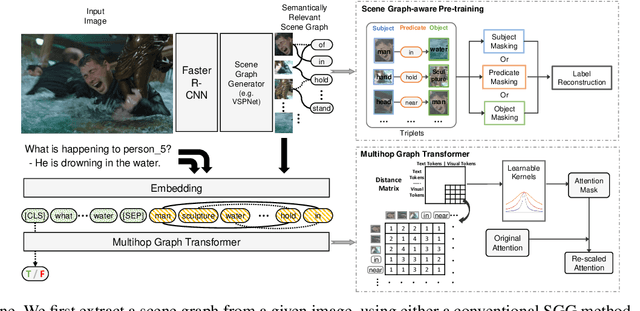
Despite the remarkable accuracy of deep neural networks in object detection, they are costly to train and scale due to supervision requirements. Particularly, learning more object categories typically requires proportionally more bounding box annotations. Weakly supervised and zero-shot learning techniques have been explored to scale object detectors to more categories with less supervision, but they have not been as successful and widely adopted as supervised models. In this paper, we put forth a novel formulation of the object detection problem, namely open-vocabulary object detection, which is more general, more practical, and more effective than weakly supervised and zero-shot approaches. We propose a new method to train object detectors using bounding box annotations for a limited set of object categories, as well as image-caption pairs that cover a larger variety of objects at a significantly lower cost. We show that the proposed method can detect and localize objects for which no bounding box annotation is provided during training, at a significantly higher accuracy than zero-shot approaches. Meanwhile, objects with bounding box annotation can be detected almost as accurately as supervised methods, which is significantly better than weakly supervised baselines. Accordingly, we establish a new state of the art for scalable object detection.
Weakly-supervised VisualBERT: Pre-training without Parallel Images and Captions
Oct 24, 2020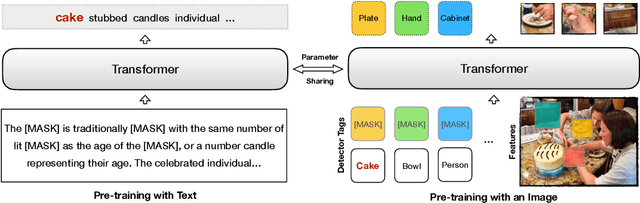
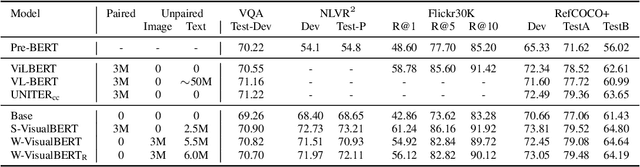

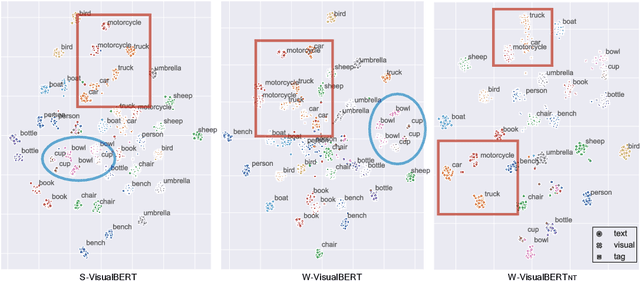
Pre-trained contextual vision-and-language (V&L) models have brought impressive performance improvement on various benchmarks. However, the paired text-image data required for pre-training are hard to collect and scale up. We investigate if a strong V&L representation model can be learned without text-image pairs. We propose Weakly-supervised VisualBERT with the key idea of conducting "mask-and-predict" pre-training on language-only and image-only corpora. Additionally, we introduce the object tags detected by an object recognition model as anchor points to bridge two modalities. Evaluation on four V&L benchmarks shows that Weakly-supervised VisualBERT achieves similar performance with a model pre-trained with paired data. Besides, pre-training on more image-only data further improves a model that already has access to aligned data, suggesting the possibility of utilizing billions of raw images available to enhance V&L models.
Analogical Reasoning for Visually Grounded Language Acquisition
Jul 22, 2020
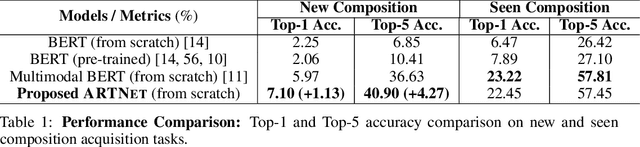
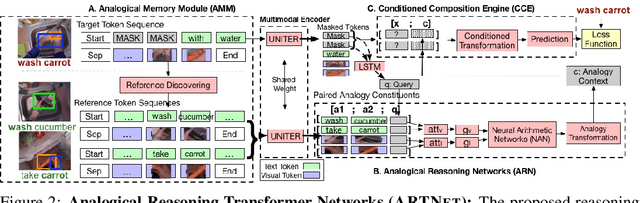

Children acquire language subconsciously by observing the surrounding world and listening to descriptions. They can discover the meaning of words even without explicit language knowledge, and generalize to novel compositions effortlessly. In this paper, we bring this ability to AI, by studying the task of Visually grounded Language Acquisition (VLA). We propose a multimodal transformer model augmented with a novel mechanism for analogical reasoning, which approximates novel compositions by learning semantic mapping and reasoning operations from previously seen compositions. Our proposed method, Analogical Reasoning Transformer Networks (ARTNet), is trained on raw multimedia data (video frames and transcripts), and after observing a set of compositions such as "washing apple" or "cutting carrot", it can generalize and recognize new compositions in new video frames, such as "washing carrot" or "cutting apple". To this end, ARTNet refers to relevant instances in the training data and uses their visual features and captions to establish analogies with the query image. Then it chooses the suitable verb and noun to create a new composition that describes the new image best. Extensive experiments on an instructional video dataset demonstrate that the proposed method achieves significantly better generalization capability and recognition accuracy compared to state-of-the-art transformer models.
Learning Visual Commonsense for Robust Scene Graph Generation
Jun 17, 2020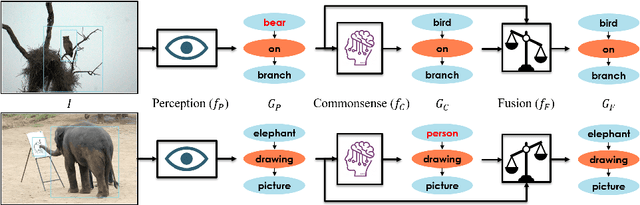

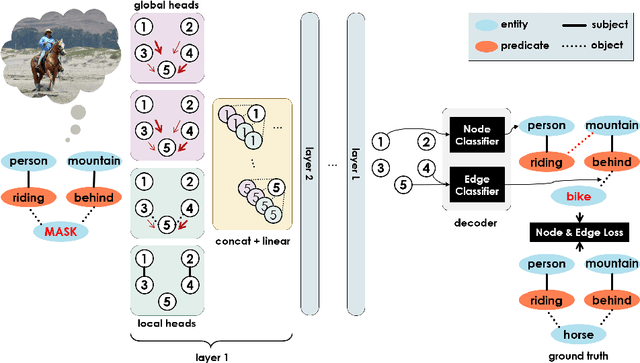
Scene graph generation models understand the scene through object and predicate recognition, but are prone to mistakes due to the challenges of perception in the wild. Perception errors often lead to nonsensical compositions in the output scene graph, which do not follow real-world rules and patterns, and can be corrected using commonsense knowledge. We propose the first method to acquire visual commonsense such as affordance and intuitive physics automatically from data, and use that to enhance scene graph generation. To this end, we extend transformers to incorporate the structure of scene graphs, and train our Global-Local Attention Transformer on a scene graph corpus. Once trained, our commonsense model can be applied on any perception model and correct its obvious mistakes, resulting in a more commonsensical scene graph. We show the proposed model learns commonsense better than any alternative, and improves the accuracy of any scene graph generation model. Nevertheless, strong disproportions in real-world datasets could bias commonsense to miscorrect already confident perceptions. We address this problem by devising a fusion module that compares predictions made by the perception and commonsense models, and the confidence of each, to make a hybrid decision. Our full model learns commonsense and knows when to use it, which is shown effective through experiments, resulting in a new state of the art.
Cross-media Structured Common Space for Multimedia Event Extraction
May 05, 2020
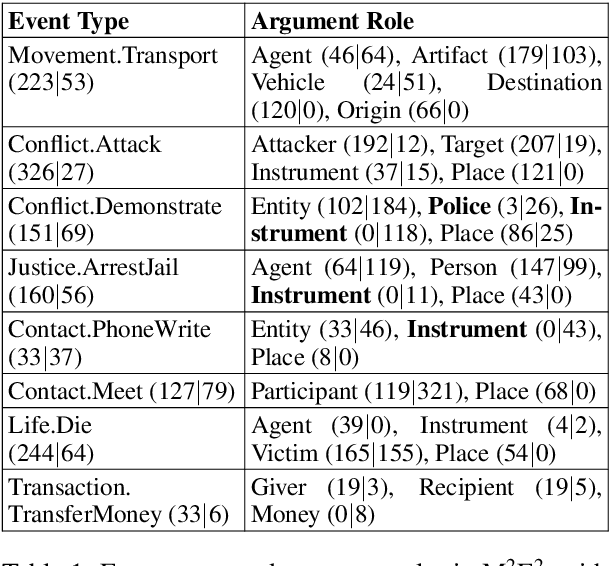

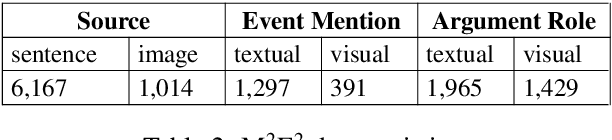
We introduce a new task, MultiMedia Event Extraction (M2E2), which aims to extract events and their arguments from multimedia documents. We develop the first benchmark and collect a dataset of 245 multimedia news articles with extensively annotated events and arguments. We propose a novel method, Weakly Aligned Structured Embedding (WASE), that encodes structured representations of semantic information from textual and visual data into a common embedding space. The structures are aligned across modalities by employing a weakly supervised training strategy, which enables exploiting available resources without explicit cross-media annotation. Compared to uni-modal state-of-the-art methods, our approach achieves 4.0% and 9.8% absolute F-score gains on text event argument role labeling and visual event extraction. Compared to state-of-the-art multimedia unstructured representations, we achieve 8.3% and 5.0% absolute F-score gains on multimedia event extraction and argument role labeling, respectively. By utilizing images, we extract 21.4% more event mentions than traditional text-only methods.
Weakly Supervised Visual Semantic Parsing
Jan 08, 2020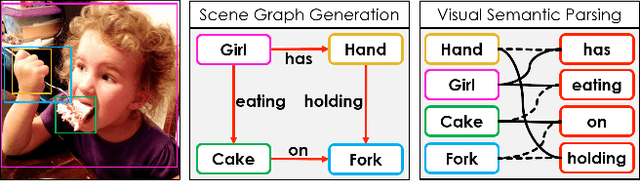
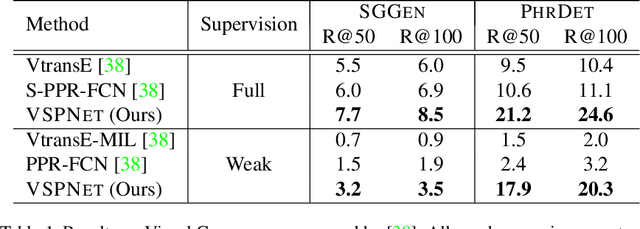
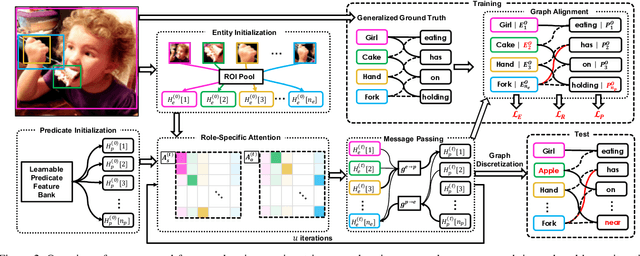
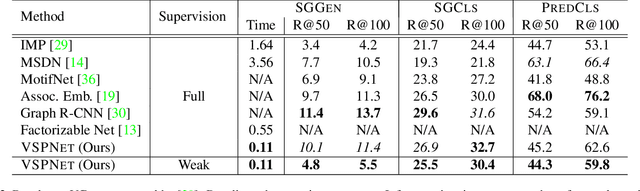
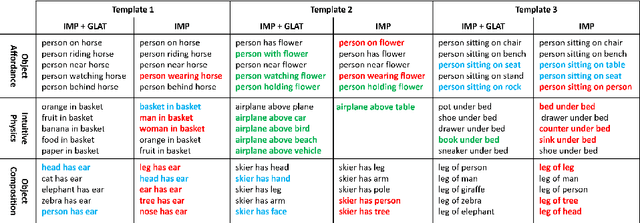
Scene Graph Generation (SGG) aims to extract entities, predicates and their intrinsic structure from images, leading to a deep understanding of visual content, with many potential applications such as visual reasoning and image retrieval. Nevertheless, computer vision is still far from a practical solution for this task. Existing SGG methods require millions of manually annotated bounding boxes for scene graph entities in a large set of images. Moreover, they are computationally inefficient, as they exhaustively process all pairs of object proposals to predict their relationships. In this paper, we address those two limitations by first proposing a generalized formulation of SGG, namely Visual Semantic Parsing, which disentangles entity and predicate prediction, and enables sub-quadratic performance. Then we propose the Visual Semantic Parsing Network, \textsc{VSPNet}, based on a novel three-stage message propagation network, as well as a role-driven attention mechanism to route messages efficiently without a quadratic cost. Finally, we propose the first graph-based weakly supervised learning framework based on a novel graph alignment algorithm, which enables training without bounding box annotations. Through extensive experiments on the Visual Genome dataset, we show \textsc{VSPNet} outperforms weakly supervised baselines significantly and approaches fully supervised performance, while being five times faster.
Bridging Knowledge Graphs to Generate Scene Graphs
Jan 07, 2020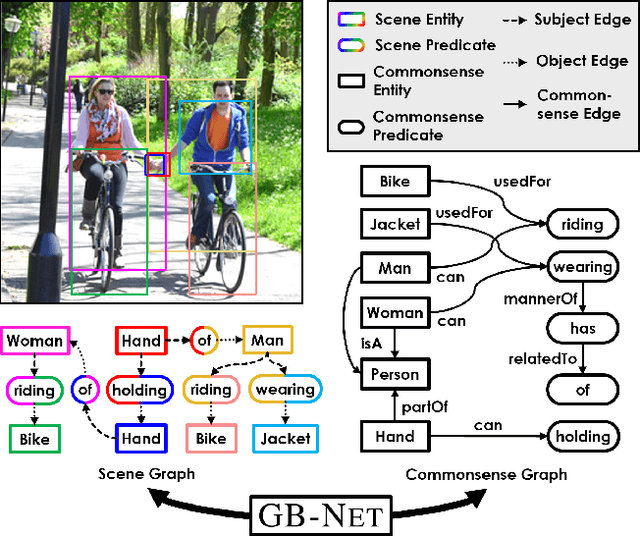
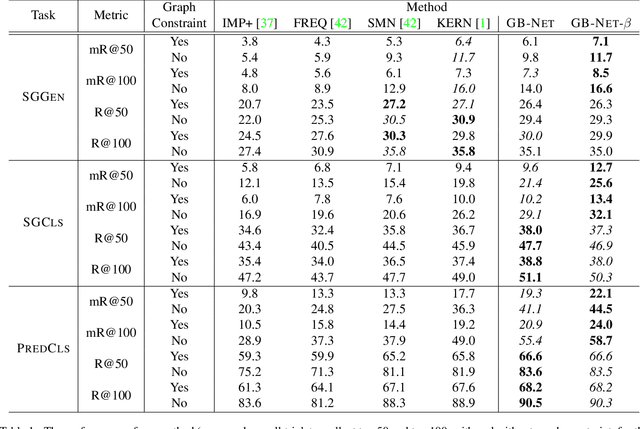

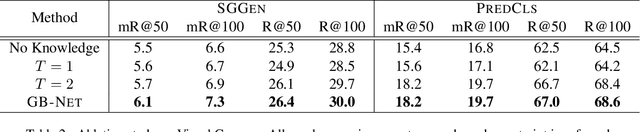
Scene graphs are powerful representations that encode images into their abstract semantic elements, i.e, objects and their interactions, which facilitates visual comprehension and explainable reasoning. On the other hand, commonsense knowledge graphs are rich repositories that encode how the world is structured, and how general concepts interact. In this paper, we present a unified formulation of these two constructs, where a scene graph is seen as an image-conditioned instantiation of a commonsense knowledge graph. Based on this new perspective, we re-formulate scene graph generation as the inference of a bridge between the scene and commonsense graphs, where each entity or predicate instance in the scene graph has to be linked to its corresponding entity or predicate class in the commonsense graph. To this end, we propose a heterogeneous graph inference framework allowing to exploit the rich structure within the scene and commonsense at the same time. Through extensive experiments, we show the proposed method achieves significant improvement over the state of the art.