 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production
Mar 02, 2026This report presents CharacterFlywheel, an iterative flywheel process for improving large language models (LLMs) in production social chat applications across Instagram, WhatsApp, and Messenger. Starting from LLaMA 3.1, we refined models across 15 generations using data from both internal and external real-user traffic. Through continuous deployments from July 2024 to April 2025, we conducted controlled 7-day A/B tests showing consistent engagement improvements: 7 of 8 newly deployed models demonstrated positive lift over the baseline, with the strongest performers achieving up to 8.8% improvement in engagement breadth and 19.4% in engagement depth. We also observed substantial gains in steerability, with instruction following increasing from 59.2% to 84.8% and instruction violations decreasing from 26.6% to 5.8%. We detail the CharacterFlywheel process which integrates data curation, reward modeling to estimate and interpolate the landscape of engagement metrics, supervised fine-tuning (SFT), reinforcement learning (RL), and both offline and online evaluation to ensure reliable progress at each optimization step. We also discuss our methods for overfitting prevention and navigating production dynamics at scale. These contributions advance the scientific rigor and understanding of LLMs in social applications serving millions of users.
Slicing Vision Transformer for Flexible Inference
Dec 06, 2024Vision Transformers (ViT) is known for its scalability. In this work, we target to scale down a ViT to fit in an environment with dynamic-changing resource constraints. We observe that smaller ViTs are intrinsically the sub-networks of a larger ViT with different widths. Thus, we propose a general framework, named Scala, to enable a single network to represent multiple smaller ViTs with flexible inference capability, which aligns with the inherent design of ViT to vary from widths. Concretely, Scala activates several subnets during training, introduces Isolated Activation to disentangle the smallest sub-network from other subnets, and leverages Scale Coordination to ensure each sub-network receives simplified, steady, and accurate learning objectives. Comprehensive empirical validations on different tasks demonstrate that with only one-shot training, Scala learns slimmable representation without modifying the original ViT structure and matches the performance of Separate Training. Compared with the prior art, Scala achieves an average improvement of 1.6% on ImageNet-1K with fewer parameters.
FORB: A Flat Object Retrieval Benchmark for Universal Image Embedding
Sep 28, 2023
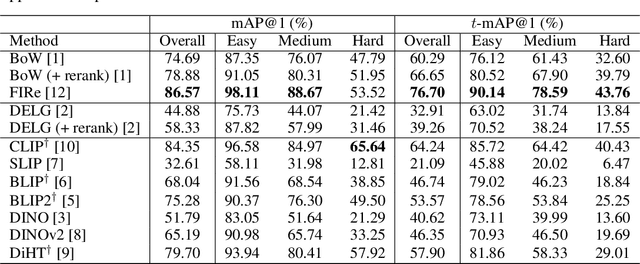

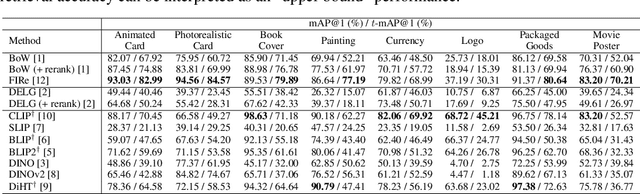
Image retrieval is a fundamental task in computer vision. Despite recent advances in this field, many techniques have been evaluated on a limited number of domains, with a small number of instance categories. Notably, most existing works only consider domains like 3D landmarks, making it difficult to generalize the conclusions made by these works to other domains, e.g., logo and other 2D flat objects. To bridge this gap, we introduce a new dataset for benchmarking visual search methods on flat images with diverse patterns. Our flat object retrieval benchmark (FORB) supplements the commonly adopted 3D object domain, and more importantly, it serves as a testbed for assessing the image embedding quality on out-of-distribution domains. In this benchmark we investigate the retrieval accuracy of representative methods in terms of candidate ranks, as well as matching score margin, a viewpoint which is largely ignored by many works. Our experiments not only highlight the challenges and rich heterogeneity of FORB, but also reveal the hidden properties of different retrieval strategies. The proposed benchmark is a growing project and we expect to expand in both quantity and variety of objects. The dataset and supporting codes are available at https://github.com/pxiangwu/FORB/.
Open-Vocabulary Object Detection Using Captions
Nov 20, 2020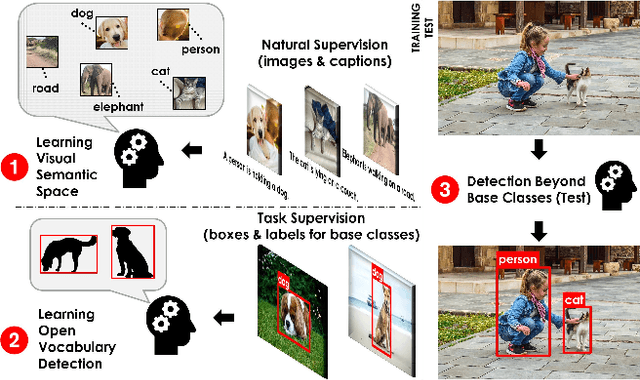
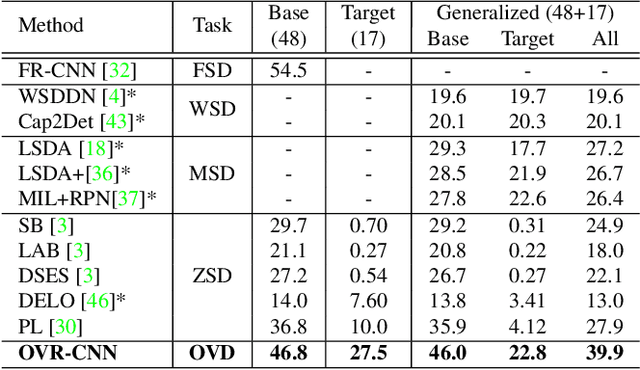
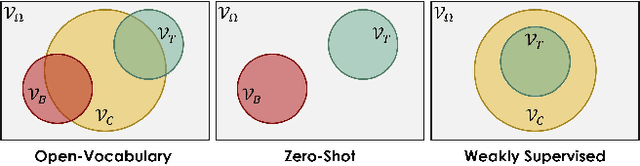
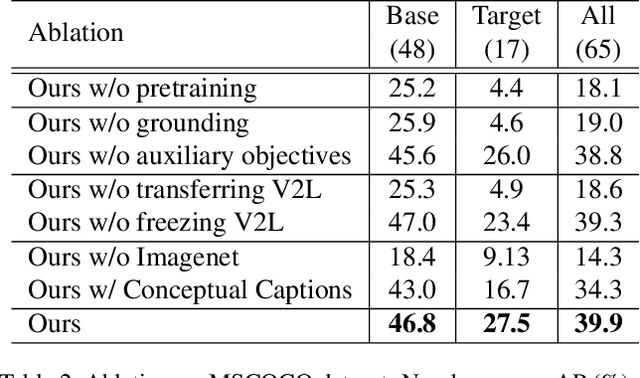
Despite the remarkable accuracy of deep neural networks in object detection, they are costly to train and scale due to supervision requirements. Particularly, learning more object categories typically requires proportionally more bounding box annotations. Weakly supervised and zero-shot learning techniques have been explored to scale object detectors to more categories with less supervision, but they have not been as successful and widely adopted as supervised models. In this paper, we put forth a novel formulation of the object detection problem, namely open-vocabulary object detection, which is more general, more practical, and more effective than weakly supervised and zero-shot approaches. We propose a new method to train object detectors using bounding box annotations for a limited set of object categories, as well as image-caption pairs that cover a larger variety of objects at a significantly lower cost. We show that the proposed method can detect and localize objects for which no bounding box annotation is provided during training, at a significantly higher accuracy than zero-shot approaches. Meanwhile, objects with bounding box annotation can be detected almost as accurately as supervised methods, which is significantly better than weakly supervised baselines. Accordingly, we establish a new state of the art for scalable object detection.