 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Enriched Retrieval Augmented Generation Using Aligned Video Captions
May 27, 2024



In this work, we propose the use of "aligned visual captions" as a mechanism for integrating information contained within videos into retrieval augmented generation (RAG) based chat assistant systems. These captions are able to describe the visual and audio content of videos in a large corpus while having the advantage of being in a textual format that is both easy to reason about & incorporate into large language model (LLM) prompts, but also typically require less multimedia content to be inserted into the multimodal LLM context window, where typical configurations can aggressively fill up the context window by sampling video frames from the source video. Furthermore, visual captions can be adapted to specific use cases by prompting the original foundational model / captioner for particular visual details or fine tuning. In hopes of helping advancing progress in this area, we curate a dataset and describe automatic evaluation procedures on common RAG tasks.
Multimodality-guided Image Style Transfer using Cross-modal GAN Inversion
Dec 04, 2023



Image Style Transfer (IST) is an interdisciplinary topic of computer vision and art that continuously attracts researchers' interests. Different from traditional Image-guided Image Style Transfer (IIST) methods that require a style reference image as input to define the desired style, recent works start to tackle the problem in a text-guided manner, i.e., Text-guided Image Style Transfer (TIST). Compared to IIST, such approaches provide more flexibility with text-specified styles, which are useful in scenarios where the style is hard to define with reference images. Unfortunately, many TIST approaches produce undesirable artifacts in the transferred images. To address this issue, we present a novel method to achieve much improved style transfer based on text guidance. Meanwhile, to offer more flexibility than IIST and TIST, our method allows style inputs from multiple sources and modalities, enabling MultiModality-guided Image Style Transfer (MMIST). Specifically, we realize MMIST with a novel cross-modal GAN inversion method, which generates style representations consistent with specified styles. Such style representations facilitate style transfer and in principle generalize any IIST methods to MMIST. Large-scale experiments and user studies demonstrate that our method achieves state-of-the-art performance on TIST task. Furthermore, comprehensive qualitative results confirm the effectiveness of our method on MMIST task and cross-modal style interpolation.
FORB: A Flat Object Retrieval Benchmark for Universal Image Embedding
Sep 28, 2023
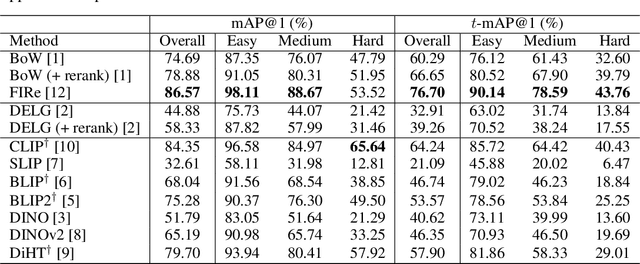

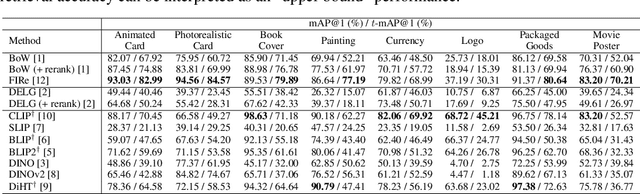
Image retrieval is a fundamental task in computer vision. Despite recent advances in this field, many techniques have been evaluated on a limited number of domains, with a small number of instance categories. Notably, most existing works only consider domains like 3D landmarks, making it difficult to generalize the conclusions made by these works to other domains, e.g., logo and other 2D flat objects. To bridge this gap, we introduce a new dataset for benchmarking visual search methods on flat images with diverse patterns. Our flat object retrieval benchmark (FORB) supplements the commonly adopted 3D object domain, and more importantly, it serves as a testbed for assessing the image embedding quality on out-of-distribution domains. In this benchmark we investigate the retrieval accuracy of representative methods in terms of candidate ranks, as well as matching score margin, a viewpoint which is largely ignored by many works. Our experiments not only highlight the challenges and rich heterogeneity of FORB, but also reveal the hidden properties of different retrieval strategies. The proposed benchmark is a growing project and we expect to expand in both quantity and variety of objects. The dataset and supporting codes are available at https://github.com/pxiangwu/FORB/.
Open-Vocabulary Object Detection Using Captions
Nov 20, 2020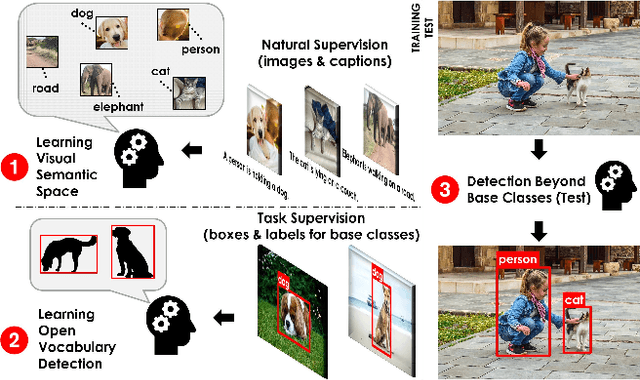
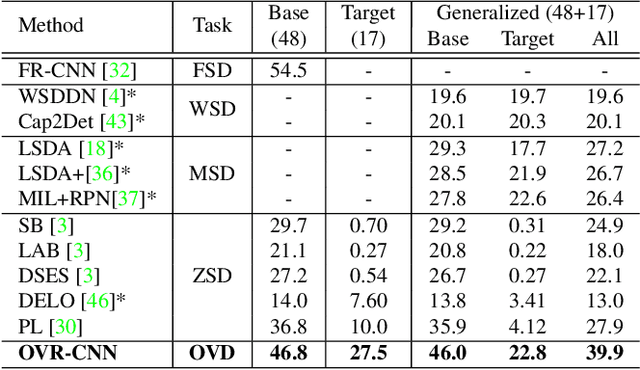
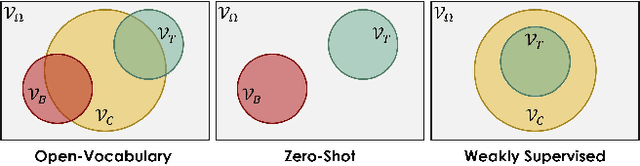
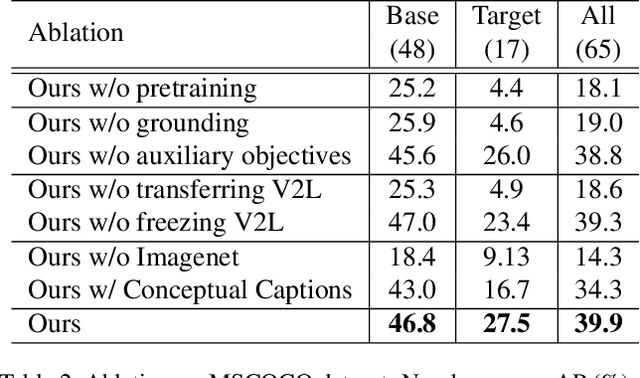
Despite the remarkable accuracy of deep neural networks in object detection, they are costly to train and scale due to supervision requirements. Particularly, learning more object categories typically requires proportionally more bounding box annotations. Weakly supervised and zero-shot learning techniques have been explored to scale object detectors to more categories with less supervision, but they have not been as successful and widely adopted as supervised models. In this paper, we put forth a novel formulation of the object detection problem, namely open-vocabulary object detection, which is more general, more practical, and more effective than weakly supervised and zero-shot approaches. We propose a new method to train object detectors using bounding box annotations for a limited set of object categories, as well as image-caption pairs that cover a larger variety of objects at a significantly lower cost. We show that the proposed method can detect and localize objects for which no bounding box annotation is provided during training, at a significantly higher accuracy than zero-shot approaches. Meanwhile, objects with bounding box annotation can be detected almost as accurately as supervised methods, which is significantly better than weakly supervised baselines. Accordingly, we establish a new state of the art for scalable object detection.