 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodality-guided Image Style Transfer using Cross-modal GAN Inversion
Dec 04, 2023



Image Style Transfer (IST) is an interdisciplinary topic of computer vision and art that continuously attracts researchers' interests. Different from traditional Image-guided Image Style Transfer (IIST) methods that require a style reference image as input to define the desired style, recent works start to tackle the problem in a text-guided manner, i.e., Text-guided Image Style Transfer (TIST). Compared to IIST, such approaches provide more flexibility with text-specified styles, which are useful in scenarios where the style is hard to define with reference images. Unfortunately, many TIST approaches produce undesirable artifacts in the transferred images. To address this issue, we present a novel method to achieve much improved style transfer based on text guidance. Meanwhile, to offer more flexibility than IIST and TIST, our method allows style inputs from multiple sources and modalities, enabling MultiModality-guided Image Style Transfer (MMIST). Specifically, we realize MMIST with a novel cross-modal GAN inversion method, which generates style representations consistent with specified styles. Such style representations facilitate style transfer and in principle generalize any IIST methods to MMIST. Large-scale experiments and user studies demonstrate that our method achieves state-of-the-art performance on TIST task. Furthermore, comprehensive qualitative results confirm the effectiveness of our method on MMIST task and cross-modal style interpolation.
FORB: A Flat Object Retrieval Benchmark for Universal Image Embedding
Sep 28, 2023
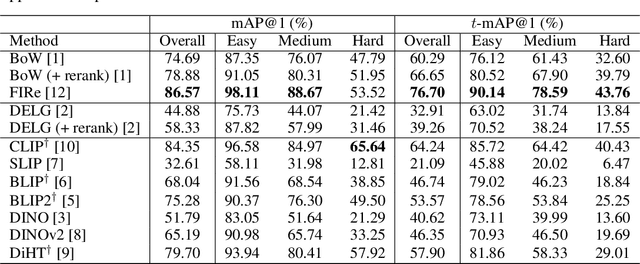

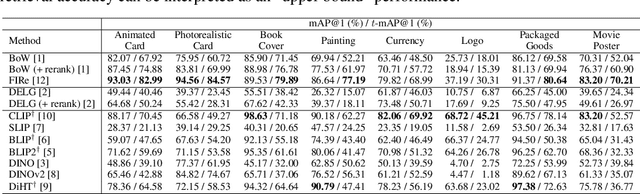
Image retrieval is a fundamental task in computer vision. Despite recent advances in this field, many techniques have been evaluated on a limited number of domains, with a small number of instance categories. Notably, most existing works only consider domains like 3D landmarks, making it difficult to generalize the conclusions made by these works to other domains, e.g., logo and other 2D flat objects. To bridge this gap, we introduce a new dataset for benchmarking visual search methods on flat images with diverse patterns. Our flat object retrieval benchmark (FORB) supplements the commonly adopted 3D object domain, and more importantly, it serves as a testbed for assessing the image embedding quality on out-of-distribution domains. In this benchmark we investigate the retrieval accuracy of representative methods in terms of candidate ranks, as well as matching score margin, a viewpoint which is largely ignored by many works. Our experiments not only highlight the challenges and rich heterogeneity of FORB, but also reveal the hidden properties of different retrieval strategies. The proposed benchmark is a growing project and we expect to expand in both quantity and variety of objects. The dataset and supporting codes are available at https://github.com/pxiangwu/FORB/.
Learning to Abstain From Uninformative Data
Sep 25, 2023Learning and decision-making in domains with naturally high noise-to-signal ratio, such as Finance or Healthcare, is often challenging, while the stakes are very high. In this paper, we study the problem of learning and acting under a general noisy generative process. In this problem, the data distribution has a significant proportion of uninformative samples with high noise in the label, while part of the data contains useful information represented by low label noise. This dichotomy is present during both training and inference, which requires the proper handling of uninformative data during both training and testing. We propose a novel approach to learning under these conditions via a loss inspired by the selective learning theory. By minimizing this loss, the model is guaranteed to make a near-optimal decision by distinguishing informative data from uninformative data and making predictions. We build upon the strength of our theoretical guarantees by describing an iterative algorithm, which jointly optimizes both a predictor and a selector, and evaluates its empirical performance in a variety of settings.
NIRVANA: Neural Implicit Representations of Videos with Adaptive Networks and Autoregressive Patch-wise Modeling
Dec 30, 2022Implicit Neural Representations (INR) have recently shown to be powerful tool for high-quality video compression. However, existing works are limiting as they do not explicitly exploit the temporal redundancy in videos, leading to a long encoding time. Additionally, these methods have fixed architectures which do not scale to longer videos or higher resolutions. To address these issues, we propose NIRVANA, which treats videos as groups of frames and fits separate networks to each group performing patch-wise prediction. This design shares computation within each group, in the spatial and temporal dimensions, resulting in reduced encoding time of the video. The video representation is modeled autoregressively, with networks fit on a current group initialized using weights from the previous group's model. To further enhance efficiency, we perform quantization of the network parameters during training, requiring no post-hoc pruning or quantization. When compared with previous works on the benchmark UVG dataset, NIRVANA improves encoding quality from 37.36 to 37.70 (in terms of PSNR) and the encoding speed by 12X, while maintaining the same compression rate. In contrast to prior video INR works which struggle with larger resolution and longer videos, we show that our algorithm is highly flexible and scales naturally due to its patch-wise and autoregressive designs. Moreover, our method achieves variable bitrate compression by adapting to videos with varying inter-frame motion. NIRVANA achieves 6X decoding speed and scales well with more GPUs, making it practical for various deployment scenarios.
Learning Distilled Collaboration Graph for Multi-Agent Perception
Nov 01, 2021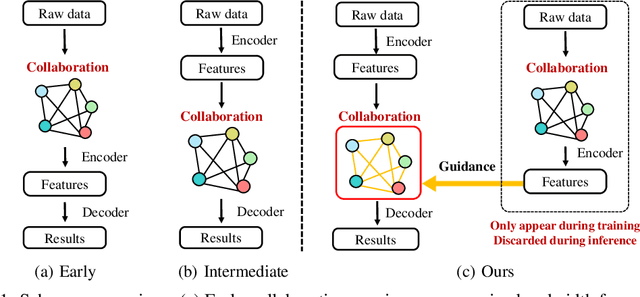
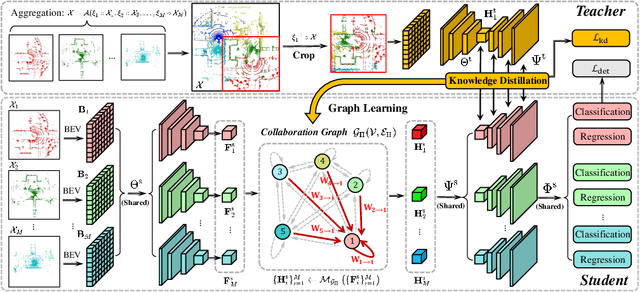


To promote better performance-bandwidth trade-off for multi-agent perception, we propose a novel distilled collaboration graph (DiscoGraph) to model trainable, pose-aware, and adaptive collaboration among agents. Our key novelties lie in two aspects. First, we propose a teacher-student framework to train DiscoGraph via knowledge distillation. The teacher model employs an early collaboration with holistic-view inputs; the student model is based on intermediate collaboration with single-view inputs. Our framework trains DiscoGraph by constraining post-collaboration feature maps in the student model to match the correspondences in the teacher model. Second, we propose a matrix-valued edge weight in DiscoGraph. In such a matrix, each element reflects the inter-agent attention at a specific spatial region, allowing an agent to adaptively highlight the informative regions. During inference, we only need to use the student model named as the distilled collaboration network (DiscoNet). Attributed to the teacher-student framework, multiple agents with the shared DiscoNet could collaboratively approach the performance of a hypothetical teacher model with a holistic view. Our approach is validated on V2X-Sim 1.0, a large-scale multi-agent perception dataset that we synthesized using CARLA and SUMO co-simulation. Our quantitative and qualitative experiments in multi-agent 3D object detection show that DiscoNet could not only achieve a better performance-bandwidth trade-off than the state-of-the-art collaborative perception methods, but also bring more straightforward design rationale. Our code is available on https://github.com/ai4ce/DiscoNet.
Object-Guided Instance Segmentation With Auxiliary Feature Refinement for Biological Images
Jun 14, 2021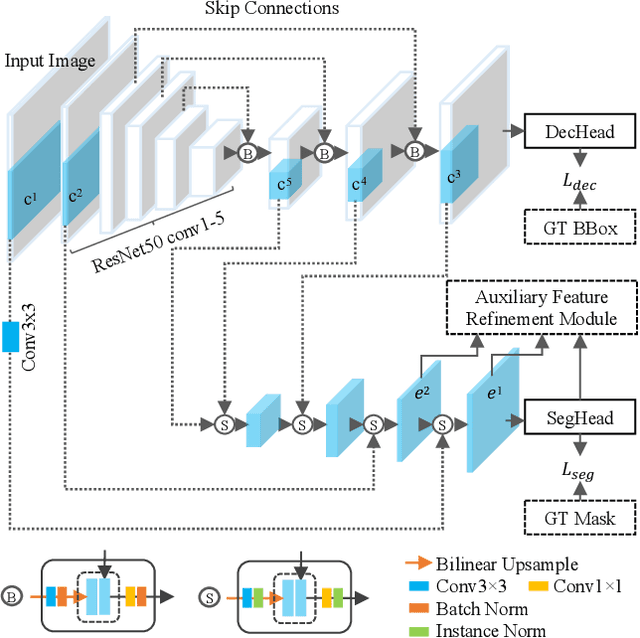
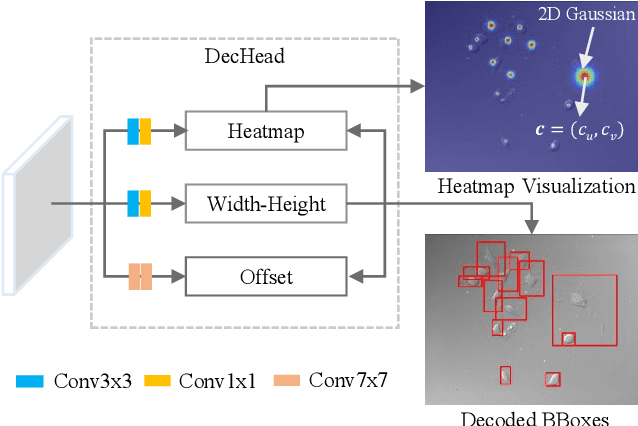
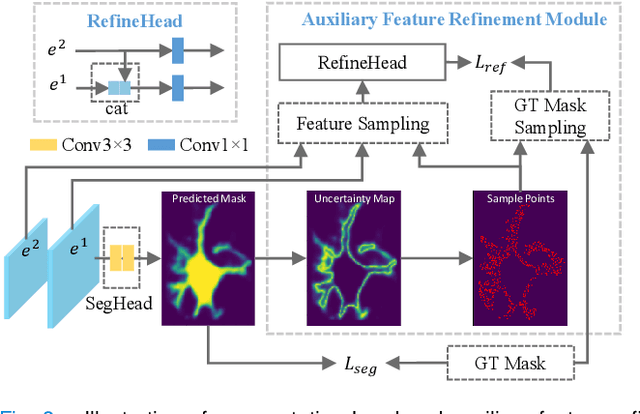

Instance segmentation is of great importance for many biological applications, such as study of neural cell interactions, plant phenotyping, and quantitatively measuring how cells react to drug treatment. In this paper, we propose a novel box-based instance segmentation method. Box-based instance segmentation methods capture objects via bounding boxes and then perform individual segmentation within each bounding box region. However, existing methods can hardly differentiate the target from its neighboring objects within the same bounding box region due to their similar textures and low-contrast boundaries. To deal with this problem, in this paper, we propose an object-guided instance segmentation method. Our method first detects the center points of the objects, from which the bounding box parameters are then predicted. To perform segmentation, an object-guided coarse-to-fine segmentation branch is built along with the detection branch. The segmentation branch reuses the object features as guidance to separate target object from the neighboring ones within the same bounding box region. To further improve the segmentation quality, we design an auxiliary feature refinement module that densely samples and refines point-wise features in the boundary regions. Experimental results on three biological image datasets demonstrate the advantages of our method. The code will be available at https://github.com/yijingru/ObjGuided-Instance-Segmentation.
Learning with Feature-Dependent Label Noise: A Progressive Approach
Mar 27, 2021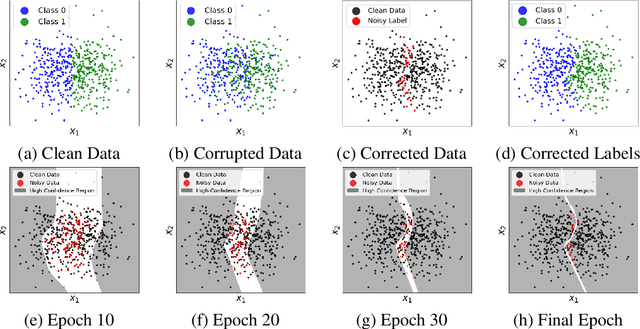
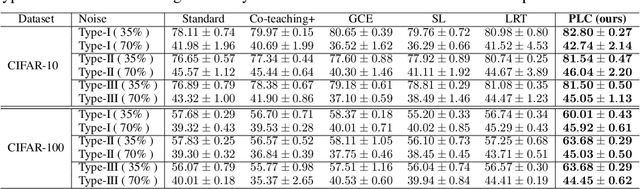
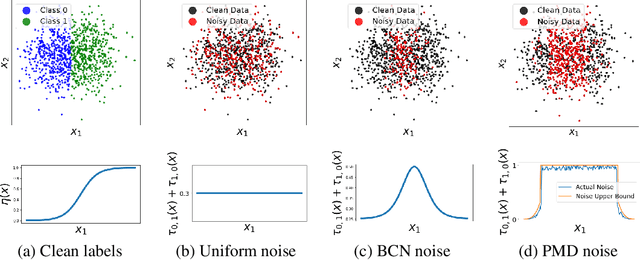
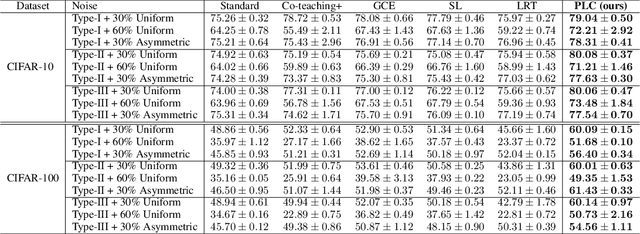
Label noise is frequently observed in real-world large-scale datasets. The noise is introduced due to a variety of reasons; it is heterogeneous and feature-dependent. Most existing approaches to handling noisy labels fall into two categories: they either assume an ideal feature-independent noise, or remain heuristic without theoretical guarantees. In this paper, we propose to target a new family of feature-dependent label noise, which is much more general than commonly used i.i.d. label noise and encompasses a broad spectrum of noise patterns. Focusing on this general noise family, we propose a progressive label correction algorithm that iteratively corrects labels and refines the model. We provide theoretical guarantees showing that for a wide variety of (unknown) noise patterns, a classifier trained with this strategy converges to be consistent with the Bayes classifier. In experiments, our method outperforms SOTA baselines and is robust to various noise types and levels.
A Topological Filter for Learning with Label Noise
Dec 09, 2020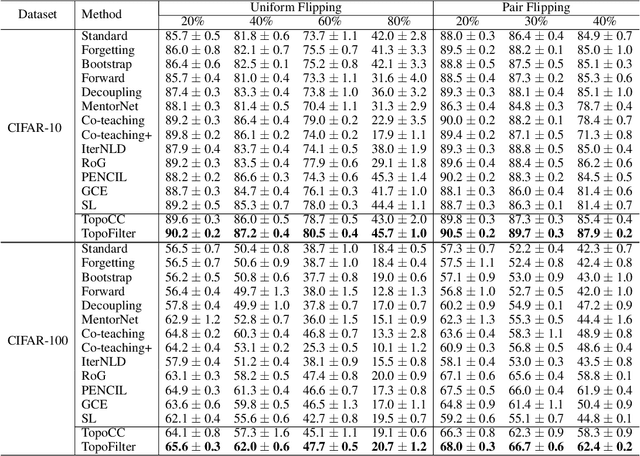
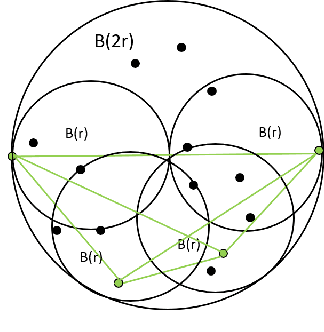
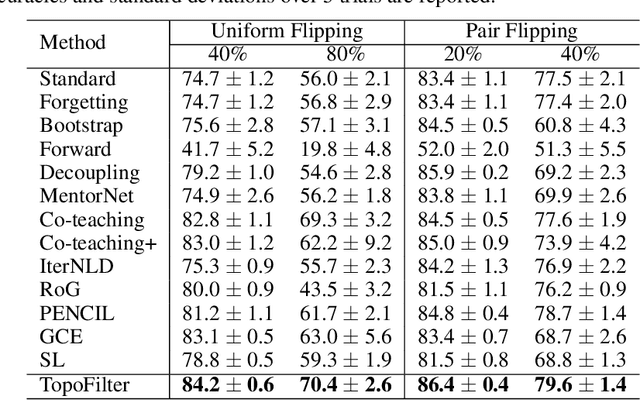

Noisy labels can impair the performance of deep neural networks. To tackle this problem, in this paper, we propose a new method for filtering label noise. Unlike most existing methods relying on the posterior probability of a noisy classifier, we focus on the much richer spatial behavior of data in the latent representational space. By leveraging the high-order topological information of data, we are able to collect most of the clean data and train a high-quality model. Theoretically we prove that this topological approach is guaranteed to collect the clean data with high probability. Empirical results show that our method outperforms the state-of-the-arts and is robust to a broad spectrum of noise types and levels.
Error-Bounded Correction of Noisy Labels
Nov 19, 2020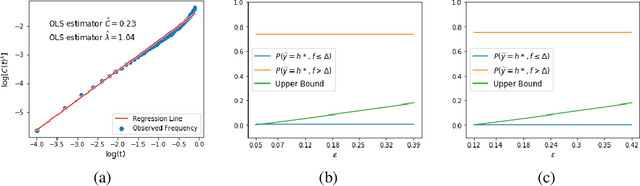
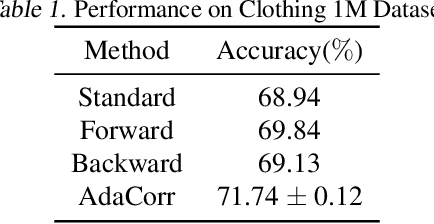
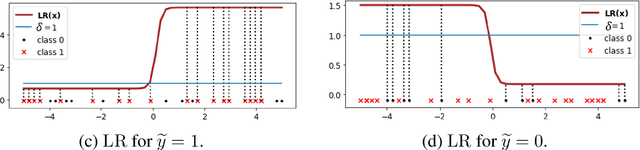
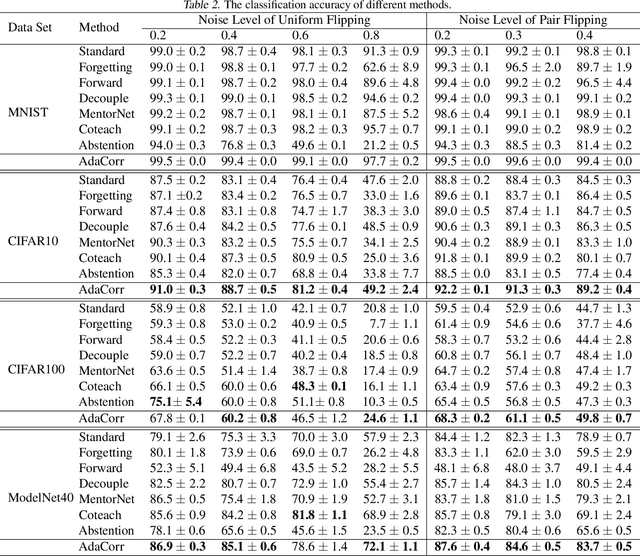
To collect large scale annotated data, it is inevitable to introduce label noise, i.e., incorrect class labels. To be robust against label noise, many successful methods rely on the noisy classifiers (i.e., models trained on the noisy training data) to determine whether a label is trustworthy. However, it remains unknown why this heuristic works well in practice. In this paper, we provide the first theoretical explanation for these methods. We prove that the prediction of a noisy classifier can indeed be a good indicator of whether the label of a training data is clean. Based on the theoretical result, we propose a novel algorithm that corrects the labels based on the noisy classifier prediction. The corrected labels are consistent with the true Bayesian optimal classifier with high probability. We incorporate our label correction algorithm into the training of deep neural networks and train models that achieve superior testing performance on multiple public datasets.
Oriented Object Detection in Aerial Images with Box Boundary-Aware Vectors
Aug 29, 2020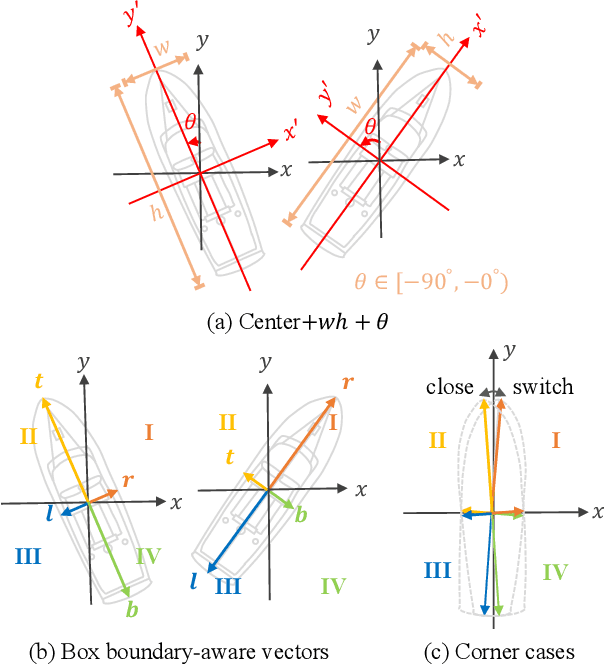
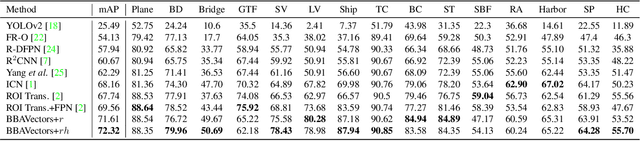
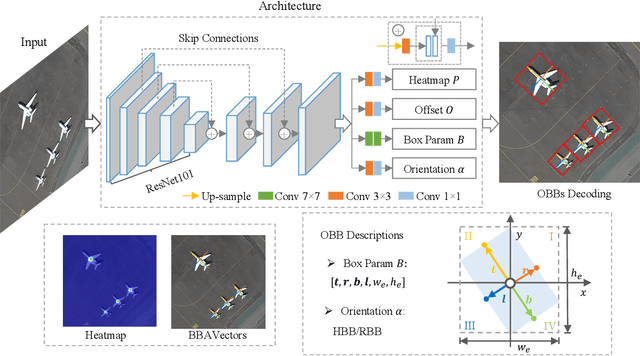
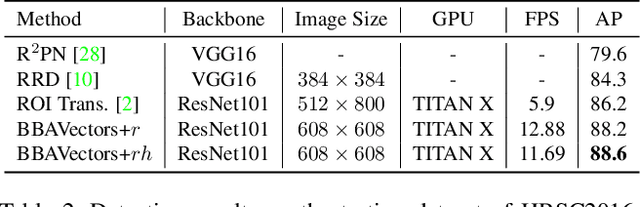
Oriented object detection in aerial images is a challenging task as the objects in aerial images are displayed in arbitrary directions and are usually densely packed. Current oriented object detection methods mainly rely on two-stage anchor-based detectors. However, the anchor-based detectors typically suffer from a severe imbalance issue between the positive and negative anchor boxes. To address this issue, in this work we extend the horizontal keypoint-based object detector to the oriented object detection task. In particular, we first detect the center keypoints of the objects, based on which we then regress the box boundary-aware vectors (BBAVectors) to capture the oriented bounding boxes. The box boundary-aware vectors are distributed in the four quadrants of a Cartesian coordinate system for all arbitrarily oriented objects. To relieve the difficulty of learning the vectors in the corner cases, we further classify the oriented bounding boxes into horizontal and rotational bounding boxes. In the experiment, we show that learning the box boundary-aware vectors is superior to directly predicting the width, height, and angle of an oriented bounding box, as adopted in the baseline method. Besides, the proposed method competes favorably with state-of-the-art methods. Code is available at https://github.com/yijingru/BBAVectors-Oriented-Object-Detection.