 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-subject Open-set Personalization in Video Generation
Jan 10, 2025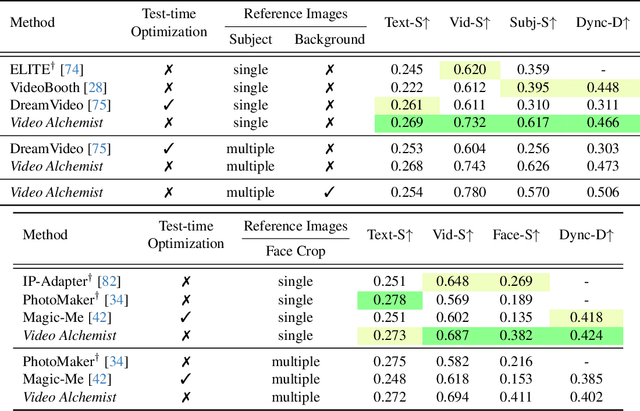
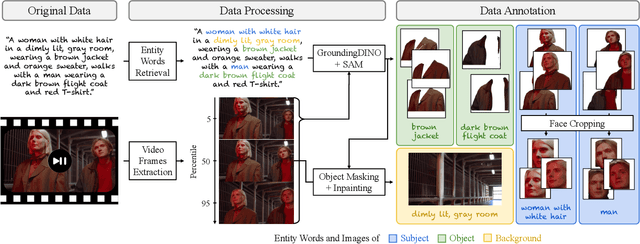
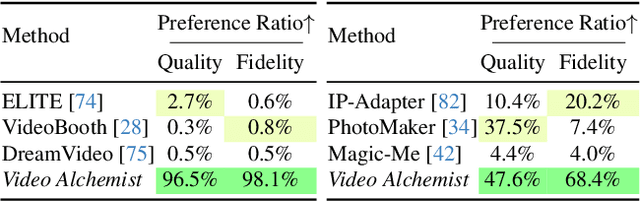
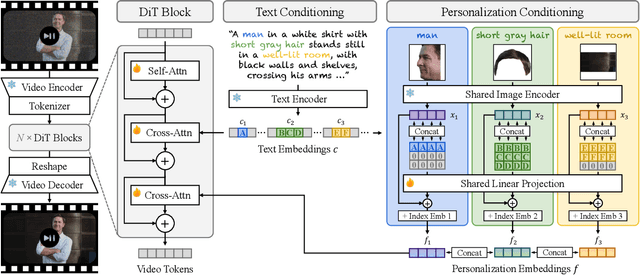
Video personalization methods allow us to synthesize videos with specific concepts such as people, pets, and places. However, existing methods often focus on limited domains, require time-consuming optimization per subject, or support only a single subject. We present Video Alchemist $-$ a video model with built-in multi-subject, open-set personalization capabilities for both foreground objects and background, eliminating the need for time-consuming test-time optimization. Our model is built on a new Diffusion Transformer module that fuses each conditional reference image and its corresponding subject-level text prompt with cross-attention layers. Developing such a large model presents two main challenges: dataset and evaluation. First, as paired datasets of reference images and videos are extremely hard to collect, we sample selected video frames as reference images and synthesize a clip of the target video. However, while models can easily denoise training videos given reference frames, they fail to generalize to new contexts. To mitigate this issue, we design a new automatic data construction pipeline with extensive image augmentations. Second, evaluating open-set video personalization is a challenge in itself. To address this, we introduce a personalization benchmark that focuses on accurate subject fidelity and supports diverse personalization scenarios. Finally, our extensive experiments show that our method significantly outperforms existing personalization methods in both quantitative and qualitative evaluations.
AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Dec 19, 2024



We propose AV-Link, a unified framework for Video-to-Audio and Audio-to-Video generation that leverages the activations of frozen video and audio diffusion models for temporally-aligned cross-modal conditioning. The key to our framework is a Fusion Block that enables bidirectional information exchange between our backbone video and audio diffusion models through a temporally-aligned self attention operation. Unlike prior work that uses feature extractors pretrained for other tasks for the conditioning signal, AV-Link can directly leverage features obtained by the complementary modality in a single framework i.e. video features to generate audio, or audio features to generate video. We extensively evaluate our design choices and demonstrate the ability of our method to achieve synchronized and high-quality audiovisual content, showcasing its potential for applications in immersive media generation. Project Page: snap-research.github.io/AVLink/
NIRVANA: Neural Implicit Representations of Videos with Adaptive Networks and Autoregressive Patch-wise Modeling
Dec 30, 2022Implicit Neural Representations (INR) have recently shown to be powerful tool for high-quality video compression. However, existing works are limiting as they do not explicitly exploit the temporal redundancy in videos, leading to a long encoding time. Additionally, these methods have fixed architectures which do not scale to longer videos or higher resolutions. To address these issues, we propose NIRVANA, which treats videos as groups of frames and fits separate networks to each group performing patch-wise prediction. This design shares computation within each group, in the spatial and temporal dimensions, resulting in reduced encoding time of the video. The video representation is modeled autoregressively, with networks fit on a current group initialized using weights from the previous group's model. To further enhance efficiency, we perform quantization of the network parameters during training, requiring no post-hoc pruning or quantization. When compared with previous works on the benchmark UVG dataset, NIRVANA improves encoding quality from 37.36 to 37.70 (in terms of PSNR) and the encoding speed by 12X, while maintaining the same compression rate. In contrast to prior video INR works which struggle with larger resolution and longer videos, we show that our algorithm is highly flexible and scales naturally due to its patch-wise and autoregressive designs. Moreover, our method achieves variable bitrate compression by adapting to videos with varying inter-frame motion. NIRVANA achieves 6X decoding speed and scales well with more GPUs, making it practical for various deployment scenarios.
Revisiting Neighborhood-based Link Prediction for Collaborative Filtering
Mar 29, 2022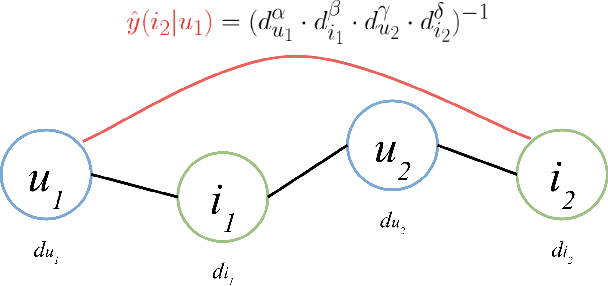
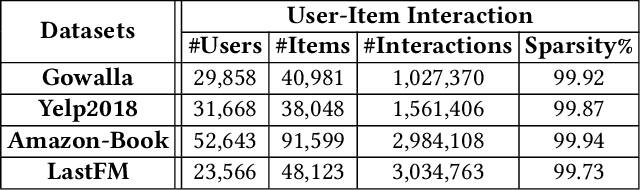
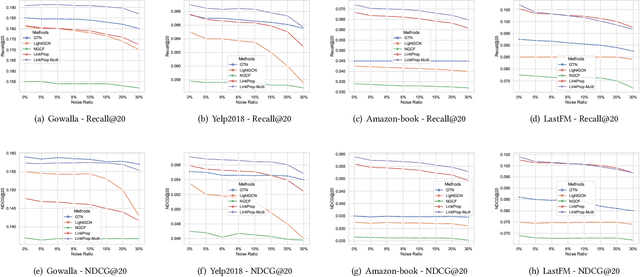
Collaborative filtering (CF) is one of the most successful and fundamental techniques in recommendation systems. In recent years, Graph Neural Network (GNN)-based CF models, such as NGCF [31], LightGCN [10] and GTN [9] have achieved tremendous success and significantly advanced the state-of-the-art. While there is a rich literature of such works using advanced models for learning user and item representations separately, item recommendation is essentially a link prediction problem between users and items. Furthermore, while there have been early works employing link prediction for collaborative filtering [5, 6], this trend has largely given way to works focused on aggregating information from user and item nodes, rather than modeling links directly. In this paper, we propose a new linkage (connectivity) score for bipartite graphs, generalizing multiple standard link prediction methods. We combine this new score with an iterative degree update process in the user-item interaction bipartite graph to exploit local graph structures without any node modeling. The result is a simple, non-deep learning model with only six learnable parameters. Despite its simplicity, we demonstrate our approach significantly outperforms existing state-of-the-art GNN-based CF approaches on four widely used benchmarks. In particular, on Amazon-Book, we demonstrate an over 60% improvement for both Recall and NDCG. We hope our work would invite the community to revisit the link prediction aspect of collaborative filtering, where significant performance gains could be achieved through aligning link prediction with item recommendations.
InfoMax-GAN: Improved Adversarial Image Generation via Information Maximization and Contrastive Learning
Jul 09, 2020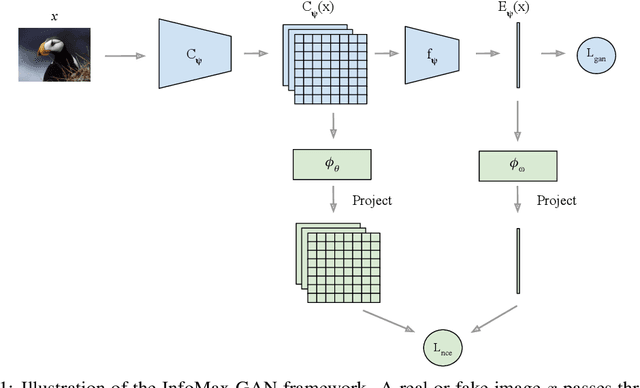

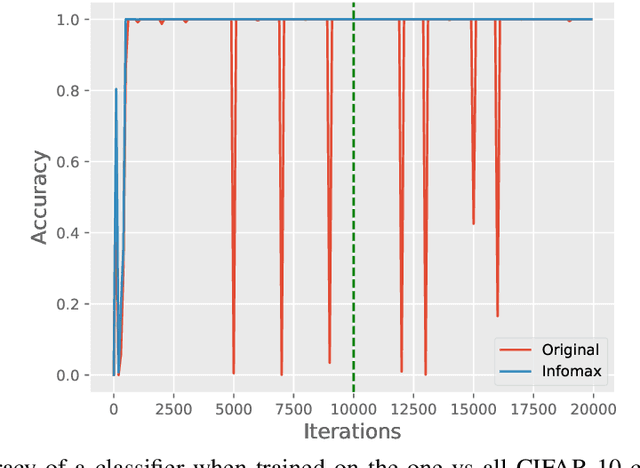
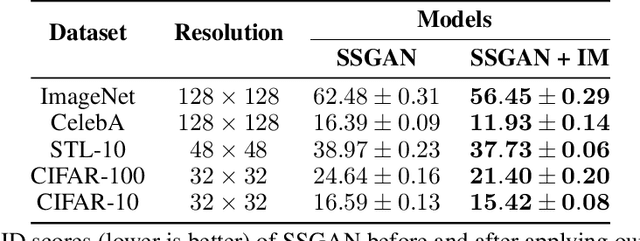
While Generative Adversarial Networks (GANs) are fundamental to many generative modelling applications, they suffer from numerous issues. In this work, we propose a principled framework to simultaneously address two fundamental issues in GANs: catastrophic forgetting of the discriminator and mode collapse of the generator. We achieve this by employing for GANs a contrastive learning and mutual information maximization approach, and perform extensive analyses to understand sources of improvements. Our approach significantly stabilises GAN training and improves GAN performance for image synthesis across five datasets under the same training and evaluation conditions against state-of-the-art works. Our approach is simple to implement and practical: it involves only one objective, is computationally inexpensive, and is robust across a wide range of hyperparameters without any tuning. For reproducibility, our code is available at https://github.com/kwotsin/mimicry.
Mimicry: Towards the Reproducibility of GAN Research
May 05, 2020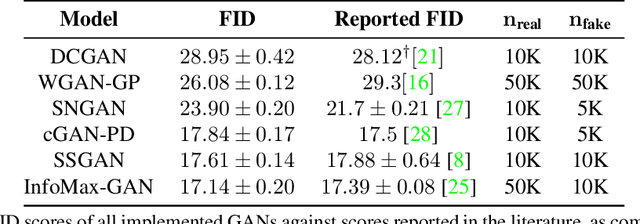
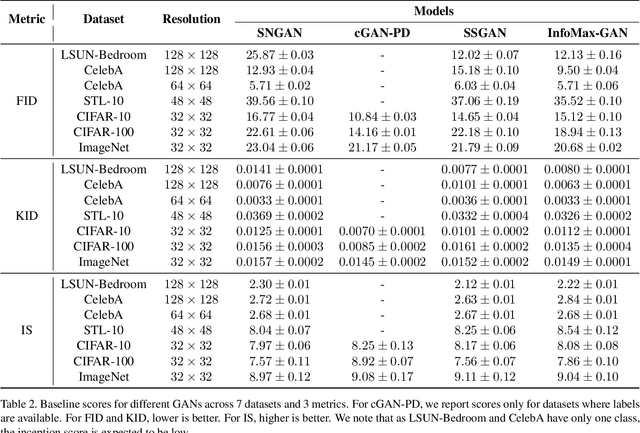
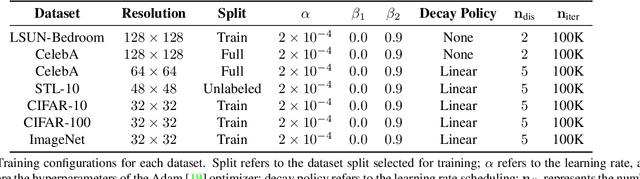

Advancing the state of Generative Adversarial Networks (GANs) research requires one to make careful and accurate comparisons with existing works. Yet, this is often difficult to achieve in practice when models are often implemented differently using varying frameworks, and evaluated using different procedures even when the same metric is used. To mitigate these issues, we introduce Mimicry, a lightweight PyTorch library that provides implementations of popular state-of-the-art GANs and evaluation metrics to closely reproduce reported scores in the literature. We provide comprehensive baseline performances of different GANs on seven widely-used datasets by training these GANs under the same conditions, and evaluating them across three popular GAN metrics using the same procedures. The library can be found at https://github.com/kwotsin/mimicry.