 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Attribute: Open-vocabulary Attribute Encoder for Visual Concept Personalization
Dec 11, 2025Visual concept personalization aims to transfer only specific image attributes, such as identity, expression, lighting, and style, into unseen contexts. However, existing methods rely on holistic embeddings from general-purpose image encoders, which entangle multiple visual factors and make it difficult to isolate a single attribute. This often leads to information leakage and incoherent synthesis. To address this limitation, we introduce Omni-Attribute, the first open-vocabulary image attribute encoder designed to learn high-fidelity, attribute-specific representations. Our approach jointly designs the data and model: (i) we curate semantically linked image pairs annotated with positive and negative attributes to explicitly teach the encoder what to preserve or suppress; and (ii) we adopt a dual-objective training paradigm that balances generative fidelity with contrastive disentanglement. The resulting embeddings prove effective for open-vocabulary attribute retrieval, personalization, and compositional generation, achieving state-of-the-art performance across multiple benchmarks.
NoiseShift: Resolution-Aware Noise Recalibration for Better Low-Resolution Image Generation
Oct 02, 2025Text-to-image diffusion models trained on a fixed set of resolutions often fail to generalize, even when asked to generate images at lower resolutions than those seen during training. High-resolution text-to-image generators are currently unable to easily offer an out-of-the-box budget-efficient alternative to their users who might not need high-resolution images. We identify a key technical insight in diffusion models that when addressed can help tackle this limitation: Noise schedulers have unequal perceptual effects across resolutions. The same level of noise removes disproportionately more signal from lower-resolution images than from high-resolution images, leading to a train-test mismatch. We propose NoiseShift, a training-free method that recalibrates the noise level of the denoiser conditioned on resolution size. NoiseShift requires no changes to model architecture or sampling schedule and is compatible with existing models. When applied to Stable Diffusion 3, Stable Diffusion 3.5, and Flux-Dev, quality at low resolutions is significantly improved. On LAION-COCO, NoiseShift improves SD3.5 by 15.89%, SD3 by 8.56%, and Flux-Dev by 2.44% in FID on average. On CelebA, NoiseShift improves SD3.5 by 10.36%, SD3 by 5.19%, and Flux-Dev by 3.02% in FID on average. These results demonstrate the effectiveness of NoiseShift in mitigating resolution-dependent artifacts and enhancing the quality of low-resolution image generation.
Improving Progressive Generation with Decomposable Flow Matching
Jun 24, 2025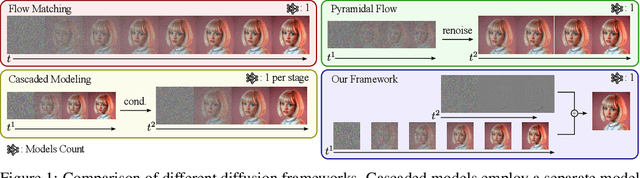
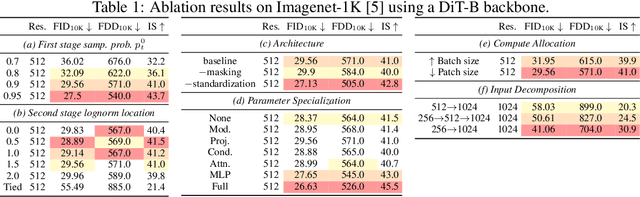
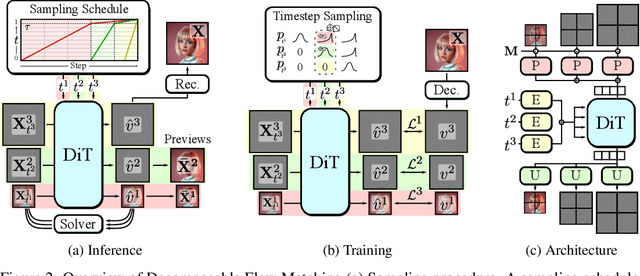
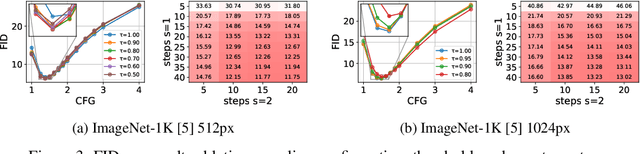
Generating high-dimensional visual modalities is a computationally intensive task. A common solution is progressive generation, where the outputs are synthesized in a coarse-to-fine spectral autoregressive manner. While diffusion models benefit from the coarse-to-fine nature of denoising, explicit multi-stage architectures are rarely adopted. These architectures have increased the complexity of the overall approach, introducing the need for a custom diffusion formulation, decomposition-dependent stage transitions, add-hoc samplers, or a model cascade. Our contribution, Decomposable Flow Matching (DFM), is a simple and effective framework for the progressive generation of visual media. DFM applies Flow Matching independently at each level of a user-defined multi-scale representation (such as Laplacian pyramid). As shown by our experiments, our approach improves visual quality for both images and videos, featuring superior results compared to prior multistage frameworks. On Imagenet-1k 512px, DFM achieves 35.2% improvements in FDD scores over the base architecture and 26.4% over the best-performing baseline, under the same training compute. When applied to finetuning of large models, such as FLUX, DFM shows faster convergence speed to the training distribution. Crucially, all these advantages are achieved with a single model, architectural simplicity, and minimal modifications to existing training pipelines.
Evaluating Text-to-Image Synthesis with a Conditional Fréchet Distance
Mar 27, 2025



Evaluating text-to-image synthesis is challenging due to misalignment between established metrics and human preferences. We propose cFreD, a metric based on the notion of Conditional Fr\'echet Distance that explicitly accounts for both visual fidelity and text-prompt alignment. Existing metrics such as Inception Score (IS), Fr\'echet Inception Distance (FID) and CLIPScore assess either image quality or image-text alignment but not both which limits their correlation with human preferences. Scoring models explicitly trained to replicate human preferences require constant updates and may not generalize to novel generation techniques or out-of-domain inputs. Through extensive experiments across multiple recently proposed text-to-image models and diverse prompt datasets, we demonstrate that cFreD exhibits a higher correlation with human judgments compared to statistical metrics, including metrics trained with human preferences. Our findings validate cFreD as a robust, future-proof metric for the systematic evaluation of text-to-image models, standardizing benchmarking in this rapidly evolving field. We release our evaluation toolkit and benchmark in the appendix.
AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Dec 19, 2024



We propose AV-Link, a unified framework for Video-to-Audio and Audio-to-Video generation that leverages the activations of frozen video and audio diffusion models for temporally-aligned cross-modal conditioning. The key to our framework is a Fusion Block that enables bidirectional information exchange between our backbone video and audio diffusion models through a temporally-aligned self attention operation. Unlike prior work that uses feature extractors pretrained for other tasks for the conditioning signal, AV-Link can directly leverage features obtained by the complementary modality in a single framework i.e. video features to generate audio, or audio features to generate video. We extensively evaluate our design choices and demonstrate the ability of our method to achieve synchronized and high-quality audiovisual content, showcasing its potential for applications in immersive media generation. Project Page: snap-research.github.io/AVLink/
Taming Data and Transformers for Audio Generation
Jun 27, 2024



Generating ambient sounds and effects is a challenging problem due to data scarcity and often insufficient caption quality, making it difficult to employ large-scale generative models for the task. In this work, we tackle the problem by introducing two new models. First, we propose AutoCap, a high-quality and efficient automatic audio captioning model. We show that by leveraging metadata available with the audio modality, we can substantially improve the quality of captions. AutoCap reaches CIDEr score of 83.2, marking a 3.2% improvement from the best available captioning model at four times faster inference speed. We then use AutoCap to caption clips from existing datasets, obtaining 761,000 audio clips with high-quality captions, forming the largest available audio-text dataset. Second, we propose GenAu, a scalable transformer-based audio generation architecture that we scale up to 1.25B parameters and train with our new dataset. When compared to state-of-the-art audio generators, GenAu obtains significant improvements of 15.7% in FAD score, 22.7% in IS, and 13.5% in CLAP score, indicating significantly improved quality of generated audio compared to previous works. This shows that the quality of data is often as important as its quantity. Besides, since AutoCap is fully automatic, new audio samples can be added to the training dataset, unlocking the training of even larger generative models for audio synthesis.
ElasticDiffusion: Training-free Arbitrary Size Image Generation
Nov 30, 2023



Diffusion models have revolutionized image generation in recent years, yet they are still limited to a few sizes and aspect ratios. We propose ElasticDiffusion, a novel training-free decoding method that enables pretrained text-to-image diffusion models to generate images with various sizes. ElasticDiffusion attempts to decouple the generation trajectory of a pretrained model into local and global signals. The local signal controls low-level pixel information and can be estimated on local patches, while the global signal is used to maintain overall structural consistency and is estimated with a reference image. We test our method on CelebA-HQ (faces) and LAION-COCO (objects/indoor/outdoor scenes). Our experiments and qualitative results show superior image coherence quality across aspect ratios compared to MultiDiffusion and the standard decoding strategy of Stable Diffusion. Code: https://github.com/MoayedHajiAli/ElasticDiffusion-official.git