 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoStream: Toward Precise Camera Controlled Streaming Video Generation
Jun 13, 2026Accurate interactive camera control is essential for video-based world models, but most existing approaches learn camera motion implicitly, leading to inaccurate control under out-of-distribution trajectories. Explicit geometric conditioning improves controllability, but existing methods are non-autoregressive and rely on a static 3D cache built from an initial frame, which becomes ineffective once the viewpoint moves beyond the original frustum. We propose GeoStream, a framework that enables precise metric-scale camera control in autoregressive streaming video generation. Our method maintains a self-refreshing 3D cache that is periodically updated online from the model's own outputs: we estimate depth from the most recently generated frame, unproject to 3D, and reproject into the target view to produce point reprojections as geometric conditioning for subsequent synthesis. By the same principle, the conditioning seen during training is also rendered from the student's own generated frames, yielding a fully on-policy distillation that naturally aligns the train and inference conditioning distributions. Unlike prior work that uses off-policy condition noising, our approach trains the model against the exact error distribution it encounters at inference, mitigating both standard autoregressive drift and the second-order geometric feedback loop that arises when the cache itself is derived from generated outputs. Quantitative and qualitative results show that our approach substantially improves camera controllability.
One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
Mar 12, 2026Diffusion transformers (DiTs) achieve high generative quality but lock FLOPs to image resolution, limiting principled latency-quality trade-offs, and allocate computation uniformly across input spatial tokens, wasting resource allocation to unimportant regions. We introduce Elastic Latent Interface Transformer (ELIT), a drop-in, DiT-compatible mechanism that decouples input image size from compute. Our approach inserts a latent interface, a learnable variable-length token sequence on which standard transformer blocks can operate. Lightweight Read and Write cross-attention layers move information between spatial tokens and latents and prioritize important input regions. By training with random dropping of tail latents, ELIT learns to produce importance-ordered representations with earlier latents capturing global structure while later ones contain information to refine details. At inference, the number of latents can be dynamically adjusted to match compute constraints. ELIT is deliberately minimal, adding two cross-attention layers while leaving the rectified flow objective and the DiT stack unchanged. Across datasets and architectures (DiT, U-ViT, HDiT, MM-DiT), ELIT delivers consistent gains. On ImageNet-1K 512px, ELIT delivers an average gain of $35.3\%$ and $39.6\%$ in FID and FDD scores. Project page: https://snap-research.github.io/elit/
EasyV2V: A High-quality Instruction-based Video Editing Framework
Dec 18, 2025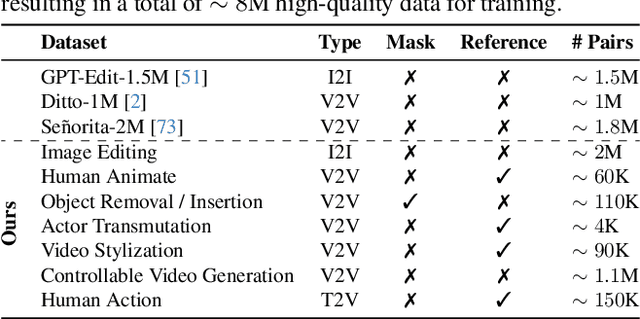

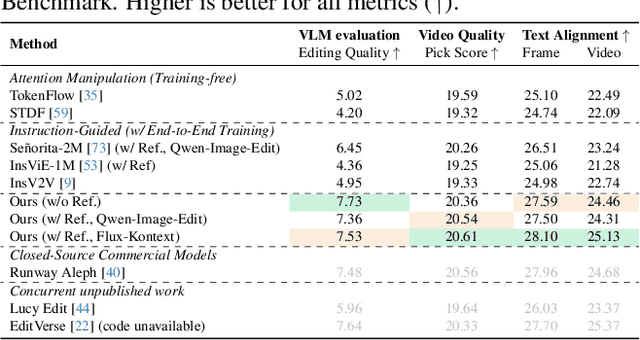
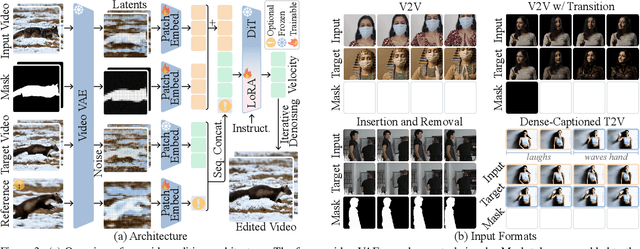
While image editing has advanced rapidly, video editing remains less explored, facing challenges in consistency, control, and generalization. We study the design space of data, architecture, and control, and introduce \emph{EasyV2V}, a simple and effective framework for instruction-based video editing. On the data side, we compose existing experts with fast inverses to build diverse video pairs, lift image edit pairs into videos via single-frame supervision and pseudo pairs with shared affine motion, mine dense-captioned clips for video pairs, and add transition supervision to teach how edits unfold. On the model side, we observe that pretrained text-to-video models possess editing capability, motivating a simplified design. Simple sequence concatenation for conditioning with light LoRA fine-tuning suffices to train a strong model. For control, we unify spatiotemporal control via a single mask mechanism and support optional reference images. Overall, EasyV2V works with flexible inputs, e.g., video+text, video+mask+text, video+mask+reference+text, and achieves state-of-the-art video editing results, surpassing concurrent and commercial systems. Project page: https://snap-research.github.io/easyv2v/
Omni-Attribute: Open-vocabulary Attribute Encoder for Visual Concept Personalization
Dec 11, 2025Visual concept personalization aims to transfer only specific image attributes, such as identity, expression, lighting, and style, into unseen contexts. However, existing methods rely on holistic embeddings from general-purpose image encoders, which entangle multiple visual factors and make it difficult to isolate a single attribute. This often leads to information leakage and incoherent synthesis. To address this limitation, we introduce Omni-Attribute, the first open-vocabulary image attribute encoder designed to learn high-fidelity, attribute-specific representations. Our approach jointly designs the data and model: (i) we curate semantically linked image pairs annotated with positive and negative attributes to explicitly teach the encoder what to preserve or suppress; and (ii) we adopt a dual-objective training paradigm that balances generative fidelity with contrastive disentanglement. The resulting embeddings prove effective for open-vocabulary attribute retrieval, personalization, and compositional generation, achieving state-of-the-art performance across multiple benchmarks.
AlphaFlow: Understanding and Improving MeanFlow Models
Oct 23, 2025MeanFlow has recently emerged as a powerful framework for few-step generative modeling trained from scratch, but its success is not yet fully understood. In this work, we show that the MeanFlow objective naturally decomposes into two parts: trajectory flow matching and trajectory consistency. Through gradient analysis, we find that these terms are strongly negatively correlated, causing optimization conflict and slow convergence. Motivated by these insights, we introduce $\alpha$-Flow, a broad family of objectives that unifies trajectory flow matching, Shortcut Model, and MeanFlow under one formulation. By adopting a curriculum strategy that smoothly anneals from trajectory flow matching to MeanFlow, $\alpha$-Flow disentangles the conflicting objectives, and achieves better convergence. When trained from scratch on class-conditional ImageNet-1K 256x256 with vanilla DiT backbones, $\alpha$-Flow consistently outperforms MeanFlow across scales and settings. Our largest $\alpha$-Flow-XL/2+ model achieves new state-of-the-art results using vanilla DiT backbones, with FID scores of 2.58 (1-NFE) and 2.15 (2-NFE).
LayerComposer: Interactive Personalized T2I via Spatially-Aware Layered Canvas
Oct 23, 2025Despite their impressive visual fidelity, existing personalized generative models lack interactive control over spatial composition and scale poorly to multiple subjects. To address these limitations, we present LayerComposer, an interactive framework for personalized, multi-subject text-to-image generation. Our approach introduces two main contributions: (1) a layered canvas, a novel representation in which each subject is placed on a distinct layer, enabling occlusion-free composition; and (2) a locking mechanism that preserves selected layers with high fidelity while allowing the remaining layers to adapt flexibly to the surrounding context. Similar to professional image-editing software, the proposed layered canvas allows users to place, resize, or lock input subjects through intuitive layer manipulation. Our versatile locking mechanism requires no architectural changes, relying instead on inherent positional embeddings combined with a new complementary data sampling strategy. Extensive experiments demonstrate that LayerComposer achieves superior spatial control and identity preservation compared to the state-of-the-art methods in multi-subject personalized image generation.
Taming Diffusion Transformer for Real-Time Mobile Video Generation
Jul 17, 2025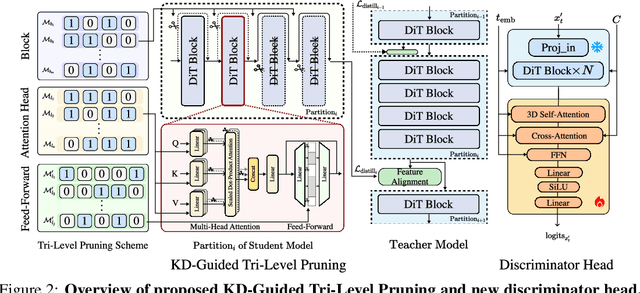
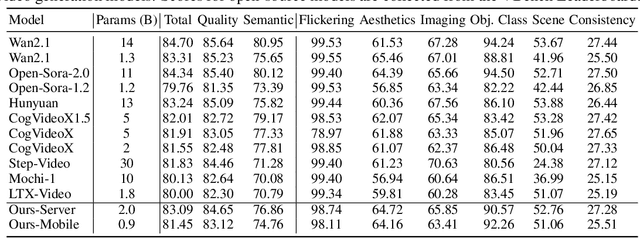

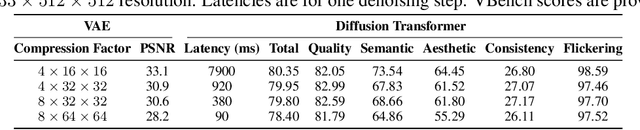
Diffusion Transformers (DiT) have shown strong performance in video generation tasks, but their high computational cost makes them impractical for resource-constrained devices like smartphones, and real-time generation is even more challenging. In this work, we propose a series of novel optimizations to significantly accelerate video generation and enable real-time performance on mobile platforms. First, we employ a highly compressed variational autoencoder (VAE) to reduce the dimensionality of the input data without sacrificing visual quality. Second, we introduce a KD-guided, sensitivity-aware tri-level pruning strategy to shrink the model size to suit mobile platform while preserving critical performance characteristics. Third, we develop an adversarial step distillation technique tailored for DiT, which allows us to reduce the number of inference steps to four. Combined, these optimizations enable our model to achieve over 10 frames per second (FPS) generation on an iPhone 16 Pro Max, demonstrating the feasibility of real-time, high-quality video generation on mobile devices.
Improving Progressive Generation with Decomposable Flow Matching
Jun 24, 2025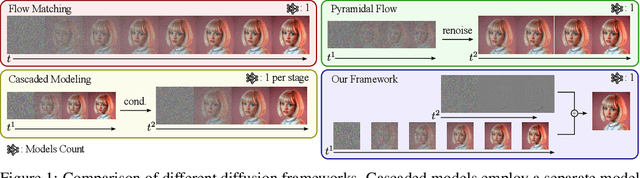
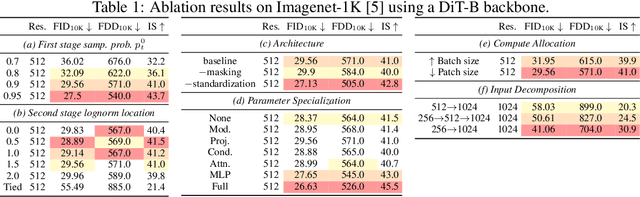
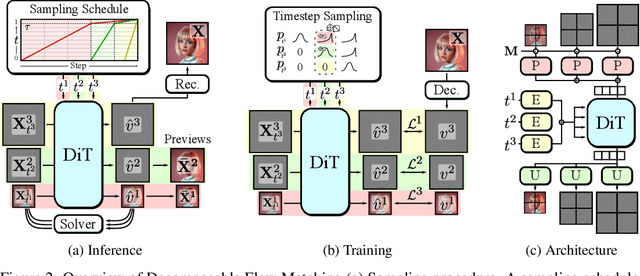
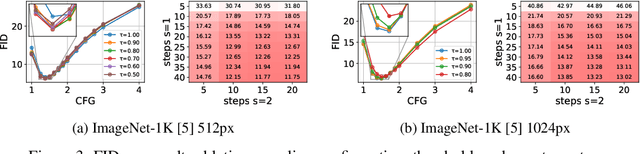
Generating high-dimensional visual modalities is a computationally intensive task. A common solution is progressive generation, where the outputs are synthesized in a coarse-to-fine spectral autoregressive manner. While diffusion models benefit from the coarse-to-fine nature of denoising, explicit multi-stage architectures are rarely adopted. These architectures have increased the complexity of the overall approach, introducing the need for a custom diffusion formulation, decomposition-dependent stage transitions, add-hoc samplers, or a model cascade. Our contribution, Decomposable Flow Matching (DFM), is a simple and effective framework for the progressive generation of visual media. DFM applies Flow Matching independently at each level of a user-defined multi-scale representation (such as Laplacian pyramid). As shown by our experiments, our approach improves visual quality for both images and videos, featuring superior results compared to prior multistage frameworks. On Imagenet-1k 512px, DFM achieves 35.2% improvements in FDD scores over the base architecture and 26.4% over the best-performing baseline, under the same training compute. When applied to finetuning of large models, such as FLUX, DFM shows faster convergence speed to the training distribution. Crucially, all these advantages are achieved with a single model, architectural simplicity, and minimal modifications to existing training pipelines.
H3AE: High Compression, High Speed, and High Quality AutoEncoder for Video Diffusion Models
Apr 14, 2025Autoencoder (AE) is the key to the success of latent diffusion models for image and video generation, reducing the denoising resolution and improving efficiency. However, the power of AE has long been underexplored in terms of network design, compression ratio, and training strategy. In this work, we systematically examine the architecture design choices and optimize the computation distribution to obtain a series of efficient and high-compression video AEs that can decode in real time on mobile devices. We also unify the design of plain Autoencoder and image-conditioned I2V VAE, achieving multifunctionality in a single network. In addition, we find that the widely adopted discriminative losses, i.e., GAN, LPIPS, and DWT losses, provide no significant improvements when training AEs at scale. We propose a novel latent consistency loss that does not require complicated discriminator design or hyperparameter tuning, but provides stable improvements in reconstruction quality. Our AE achieves an ultra-high compression ratio and real-time decoding speed on mobile while outperforming prior art in terms of reconstruction metrics by a large margin. We finally validate our AE by training a DiT on its latent space and demonstrate fast, high-quality text-to-video generation capability.
Improving the Diffusability of Autoencoders
Feb 20, 2025Latent diffusion models have emerged as the leading approach for generating high-quality images and videos, utilizing compressed latent representations to reduce the computational burden of the diffusion process. While recent advancements have primarily focused on scaling diffusion backbones and improving autoencoder reconstruction quality, the interaction between these components has received comparatively less attention. In this work, we perform a spectral analysis of modern autoencoders and identify inordinate high-frequency components in their latent spaces, which are especially pronounced in the autoencoders with a large bottleneck channel size. We hypothesize that this high-frequency component interferes with the coarse-to-fine nature of the diffusion synthesis process and hinders the generation quality. To mitigate the issue, we propose scale equivariance: a simple regularization strategy that aligns latent and RGB spaces across frequencies by enforcing scale equivariance in the decoder. It requires minimal code changes and only up to 20K autoencoder fine-tuning steps, yet significantly improves generation quality, reducing FID by 19% for image generation on ImageNet-1K 256x256 and FVD by at least 44% for video generation on Kinetics-700 17x256x256.