 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Attribute: Open-vocabulary Attribute Encoder for Visual Concept Personalization
Dec 11, 2025Visual concept personalization aims to transfer only specific image attributes, such as identity, expression, lighting, and style, into unseen contexts. However, existing methods rely on holistic embeddings from general-purpose image encoders, which entangle multiple visual factors and make it difficult to isolate a single attribute. This often leads to information leakage and incoherent synthesis. To address this limitation, we introduce Omni-Attribute, the first open-vocabulary image attribute encoder designed to learn high-fidelity, attribute-specific representations. Our approach jointly designs the data and model: (i) we curate semantically linked image pairs annotated with positive and negative attributes to explicitly teach the encoder what to preserve or suppress; and (ii) we adopt a dual-objective training paradigm that balances generative fidelity with contrastive disentanglement. The resulting embeddings prove effective for open-vocabulary attribute retrieval, personalization, and compositional generation, achieving state-of-the-art performance across multiple benchmarks.
AlcheMinT: Fine-grained Temporal Control for Multi-Reference Consistent Video Generation
Dec 11, 2025Recent advances in subject-driven video generation with large diffusion models have enabled personalized content synthesis conditioned on user-provided subjects. However, existing methods lack fine-grained temporal control over subject appearance and disappearance, which are essential for applications such as compositional video synthesis, storyboarding, and controllable animation. We propose AlcheMinT, a unified framework that introduces explicit timestamps conditioning for subject-driven video generation. Our approach introduces a novel positional encoding mechanism that unlocks the encoding of temporal intervals, associated in our case with subject identities, while seamlessly integrating with the pretrained video generation model positional embeddings. Additionally, we incorporate subject-descriptive text tokens to strengthen binding between visual identity and video captions, mitigating ambiguity during generation. Through token-wise concatenation, AlcheMinT avoids any additional cross-attention modules and incurs negligible parameter overhead. We establish a benchmark evaluating multiple subject identity preservation, video fidelity, and temporal adherence. Experimental results demonstrate that AlcheMinT achieves visual quality matching state-of-the-art video personalization methods, while, for the first time, enabling precise temporal control over multi-subject generation within videos. Project page is at https://snap-research.github.io/Video-AlcheMinT
LayerComposer: Interactive Personalized T2I via Spatially-Aware Layered Canvas
Oct 23, 2025Despite their impressive visual fidelity, existing personalized generative models lack interactive control over spatial composition and scale poorly to multiple subjects. To address these limitations, we present LayerComposer, an interactive framework for personalized, multi-subject text-to-image generation. Our approach introduces two main contributions: (1) a layered canvas, a novel representation in which each subject is placed on a distinct layer, enabling occlusion-free composition; and (2) a locking mechanism that preserves selected layers with high fidelity while allowing the remaining layers to adapt flexibly to the surrounding context. Similar to professional image-editing software, the proposed layered canvas allows users to place, resize, or lock input subjects through intuitive layer manipulation. Our versatile locking mechanism requires no architectural changes, relying instead on inherent positional embeddings combined with a new complementary data sampling strategy. Extensive experiments demonstrate that LayerComposer achieves superior spatial control and identity preservation compared to the state-of-the-art methods in multi-subject personalized image generation.
Multi-subject Open-set Personalization in Video Generation
Jan 10, 2025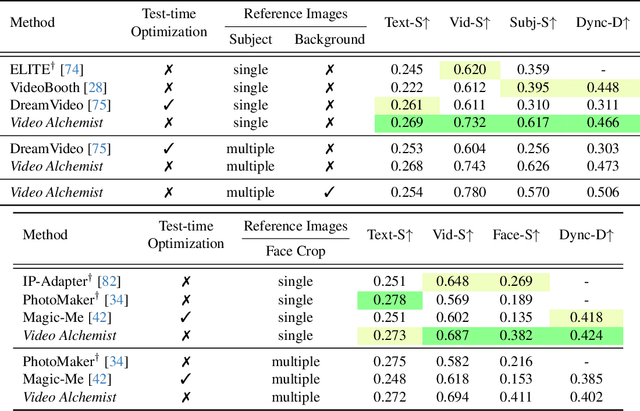
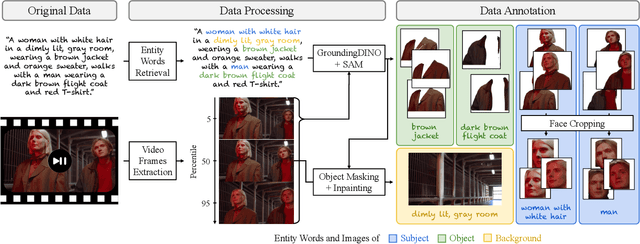
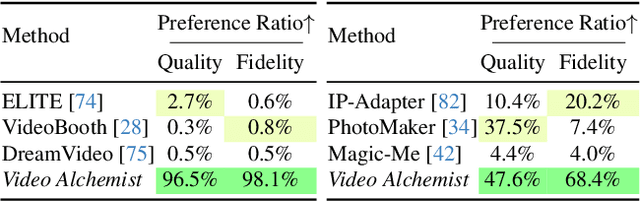
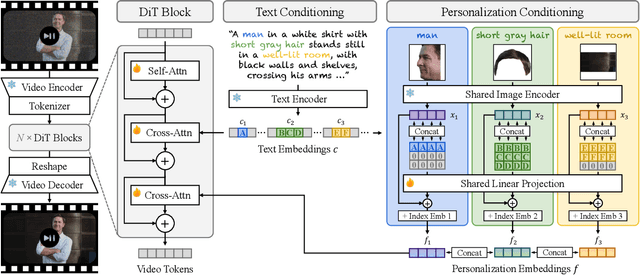
Video personalization methods allow us to synthesize videos with specific concepts such as people, pets, and places. However, existing methods often focus on limited domains, require time-consuming optimization per subject, or support only a single subject. We present Video Alchemist $-$ a video model with built-in multi-subject, open-set personalization capabilities for both foreground objects and background, eliminating the need for time-consuming test-time optimization. Our model is built on a new Diffusion Transformer module that fuses each conditional reference image and its corresponding subject-level text prompt with cross-attention layers. Developing such a large model presents two main challenges: dataset and evaluation. First, as paired datasets of reference images and videos are extremely hard to collect, we sample selected video frames as reference images and synthesize a clip of the target video. However, while models can easily denoise training videos given reference frames, they fail to generalize to new contexts. To mitigate this issue, we design a new automatic data construction pipeline with extensive image augmentations. Second, evaluating open-set video personalization is a challenge in itself. To address this, we introduce a personalization benchmark that focuses on accurate subject fidelity and supports diverse personalization scenarios. Finally, our extensive experiments show that our method significantly outperforms existing personalization methods in both quantitative and qualitative evaluations.
VIMI: Grounding Video Generation through Multi-modal Instruction
Jul 08, 2024



Existing text-to-video diffusion models rely solely on text-only encoders for their pretraining. This limitation stems from the absence of large-scale multimodal prompt video datasets, resulting in a lack of visual grounding and restricting their versatility and application in multimodal integration. To address this, we construct a large-scale multimodal prompt dataset by employing retrieval methods to pair in-context examples with the given text prompts and then utilize a two-stage training strategy to enable diverse video generation tasks within the same model. In the first stage, we propose a multimodal conditional video generation framework for pretraining on these augmented datasets, establishing a foundational model for grounded video generation. Secondly, we finetune the model from the first stage on three video generation tasks, incorporating multi-modal instructions. This process further refines the model's ability to handle diverse inputs and tasks, ensuring seamless integration of multi-modal information. After this two-stage train-ing process, VIMI demonstrates multimodal understanding capabilities, producing contextually rich and personalized videos grounded in the provided inputs, as shown in Figure 1. Compared to previous visual grounded video generation methods, VIMI can synthesize consistent and temporally coherent videos with large motion while retaining the semantic control. Lastly, VIMI also achieves state-of-the-art text-to-video generation results on UCF101 benchmark.
Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers
Feb 29, 2024



The quality of the data and annotation upper-bounds the quality of a downstream model. While there exist large text corpora and image-text pairs, high-quality video-text data is much harder to collect. First of all, manual labeling is more time-consuming, as it requires an annotator to watch an entire video. Second, videos have a temporal dimension, consisting of several scenes stacked together, and showing multiple actions. Accordingly, to establish a video dataset with high-quality captions, we propose an automatic approach leveraging multimodal inputs, such as textual video description, subtitles, and individual video frames. Specifically, we curate 3.8M high-resolution videos from the publicly available HD-VILA-100M dataset. We then split them into semantically consistent video clips, and apply multiple cross-modality teacher models to obtain captions for each video. Next, we finetune a retrieval model on a small subset where the best caption of each video is manually selected and then employ the model in the whole dataset to select the best caption as the annotation. In this way, we get 70M videos paired with high-quality text captions. We dub the dataset as Panda-70M. We show the value of the proposed dataset on three downstream tasks: video captioning, video and text retrieval, and text-driven video generation. The models trained on the proposed data score substantially better on the majority of metrics across all the tasks.
Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis
Feb 22, 2024



Contemporary models for generating images show remarkable quality and versatility. Swayed by these advantages, the research community repurposes them to generate videos. Since video content is highly redundant, we argue that naively bringing advances of image models to the video generation domain reduces motion fidelity, visual quality and impairs scalability. In this work, we build Snap Video, a video-first model that systematically addresses these challenges. To do that, we first extend the EDM framework to take into account spatially and temporally redundant pixels and naturally support video generation. Second, we show that a U-Net - a workhorse behind image generation - scales poorly when generating videos, requiring significant computational overhead. Hence, we propose a new transformer-based architecture that trains 3.31 times faster than U-Nets (and is ~4.5 faster at inference). This allows us to efficiently train a text-to-video model with billions of parameters for the first time, reach state-of-the-art results on a number of benchmarks, and generate videos with substantially higher quality, temporal consistency, and motion complexity. The user studies showed that our model was favored by a large margin over the most recent methods. See our website at https://snap-research.github.io/snapvideo/.
Motion-Conditioned Diffusion Model for Controllable Video Synthesis
Apr 27, 2023



Recent advancements in diffusion models have greatly improved the quality and diversity of synthesized content. To harness the expressive power of diffusion models, researchers have explored various controllable mechanisms that allow users to intuitively guide the content synthesis process. Although the latest efforts have primarily focused on video synthesis, there has been a lack of effective methods for controlling and describing desired content and motion. In response to this gap, we introduce MCDiff, a conditional diffusion model that generates a video from a starting image frame and a set of strokes, which allow users to specify the intended content and dynamics for synthesis. To tackle the ambiguity of sparse motion inputs and achieve better synthesis quality, MCDiff first utilizes a flow completion model to predict the dense video motion based on the semantic understanding of the video frame and the sparse motion control. Then, the diffusion model synthesizes high-quality future frames to form the output video. We qualitatively and quantitatively show that MCDiff achieves the state-the-of-art visual quality in stroke-guided controllable video synthesis. Additional experiments on MPII Human Pose further exhibit the capability of our model on diverse content and motion synthesis.
Hard Samples Rectification for Unsupervised Cross-domain Person Re-identification
Jun 14, 2021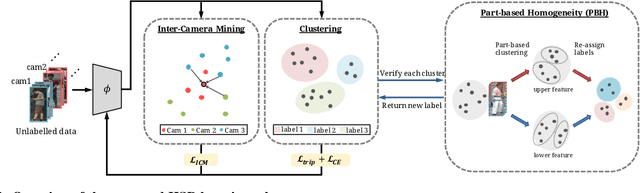
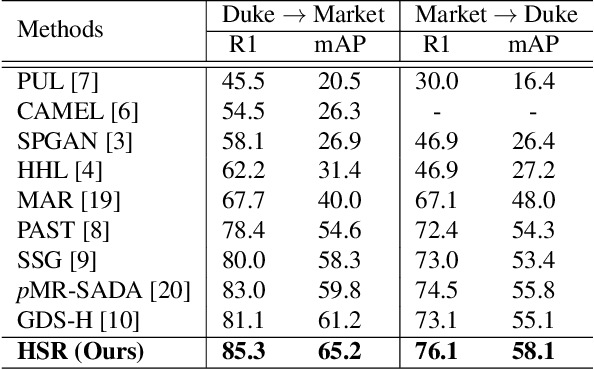
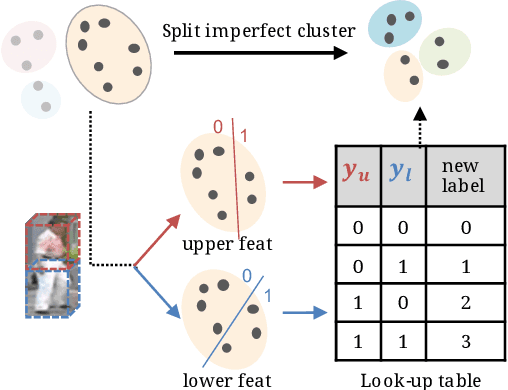
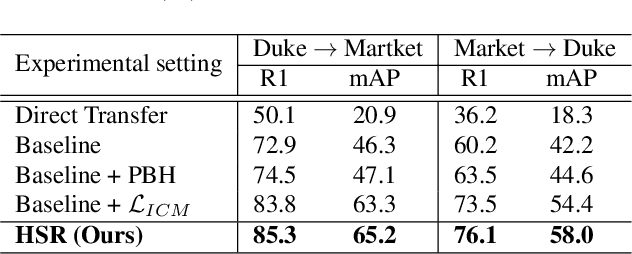
Person re-identification (re-ID) has received great success with the supervised learning methods. However, the task of unsupervised cross-domain re-ID is still challenging. In this paper, we propose a Hard Samples Rectification (HSR) learning scheme which resolves the weakness of original clustering-based methods being vulnerable to the hard positive and negative samples in the target unlabelled dataset. Our HSR contains two parts, an inter-camera mining method that helps recognize a person under different views (hard positive) and a part-based homogeneity technique that makes the model discriminate different persons but with similar appearance (hard negative). By rectifying those two hard cases, the re-ID model can learn effectively and achieve promising results on two large-scale benchmarks.
Incremental False Negative Detection for Contrastive Learning
Jun 07, 2021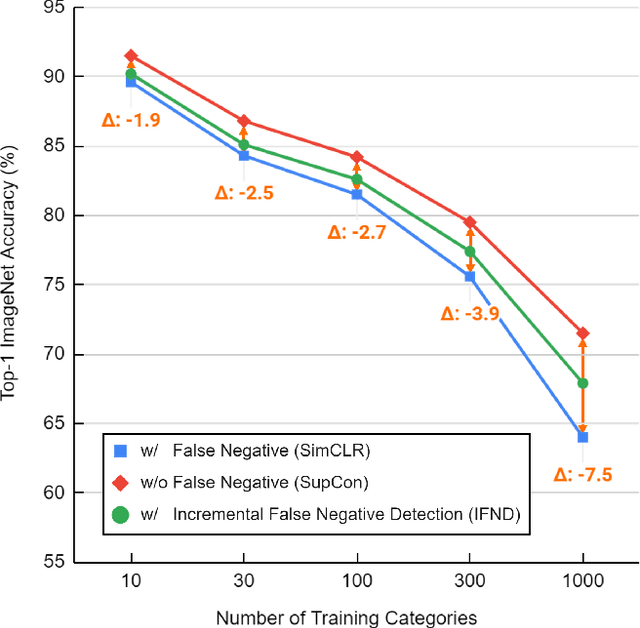
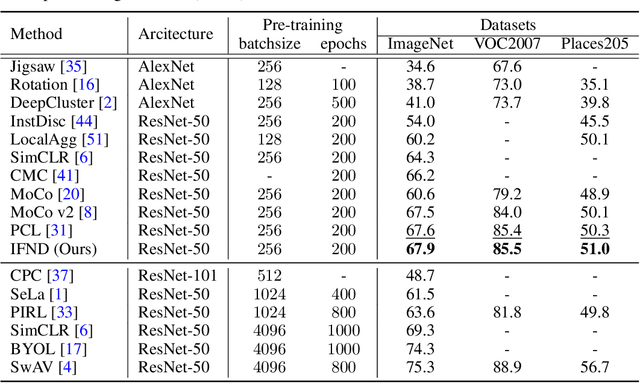
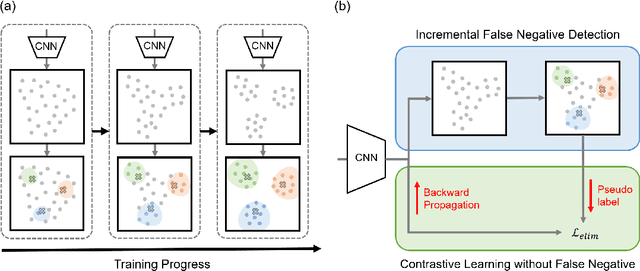
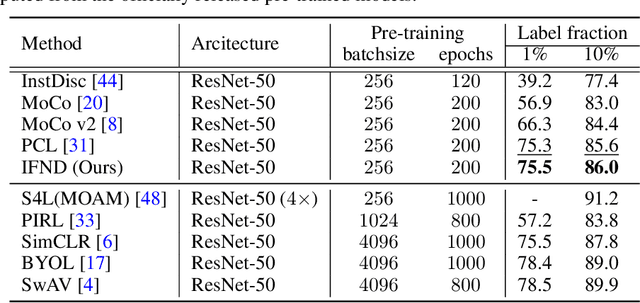
Self-supervised learning has recently shown great potential in vision tasks via contrastive learning, which aims to discriminate each image, or instance, in the dataset. However, such instance-level learning ignores the semantic relationship between instances and repels the anchor equally from the semantically similar samples, termed as false negatives. In this work, we first empirically highlight that the unfavorable effect from false negatives is more significant for the datasets containing images with more semantic concepts. To address the issue, we introduce a novel incremental false negative detection for self-supervised contrastive learning. Following the training process, when the encoder is gradually better-trained and the embedding space becomes more semantically structural, our method incrementally detects more reliable false negatives. Subsequently, during contrastive learning, we discuss two strategies to explicitly remove the detected false negatives. Extensive experiments show that our proposed method outperforms other self-supervised contrastive learning frameworks on multiple benchmarks within a limited compute.