 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstaInpaint: Instant 3D-Scene Inpainting with Masked Large Reconstruction Model
Jun 12, 2025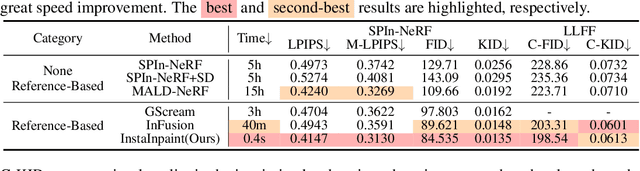


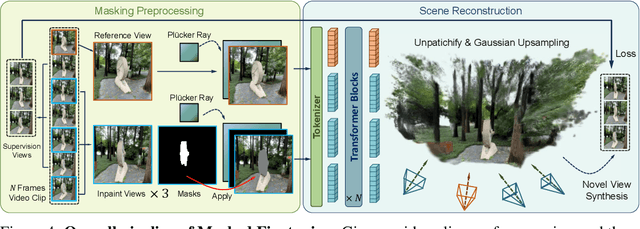
Recent advances in 3D scene reconstruction enable real-time viewing in virtual and augmented reality. To support interactive operations for better immersiveness, such as moving or editing objects, 3D scene inpainting methods are proposed to repair or complete the altered geometry. However, current approaches rely on lengthy and computationally intensive optimization, making them impractical for real-time or online applications. We propose InstaInpaint, a reference-based feed-forward framework that produces 3D-scene inpainting from a 2D inpainting proposal within 0.4 seconds. We develop a self-supervised masked-finetuning strategy to enable training of our custom large reconstruction model (LRM) on the large-scale dataset. Through extensive experiments, we analyze and identify several key designs that improve generalization, textural consistency, and geometric correctness. InstaInpaint achieves a 1000x speed-up from prior methods while maintaining a state-of-the-art performance across two standard benchmarks. Moreover, we show that InstaInpaint generalizes well to flexible downstream applications such as object insertion and multi-region inpainting. More video results are available at our project page: https://dhmbb2.github.io/InstaInpaint_page/.
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025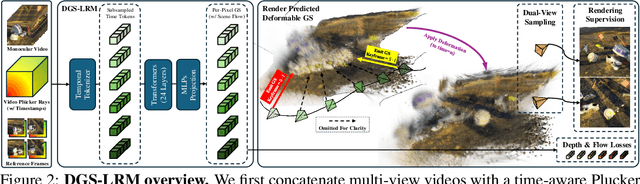
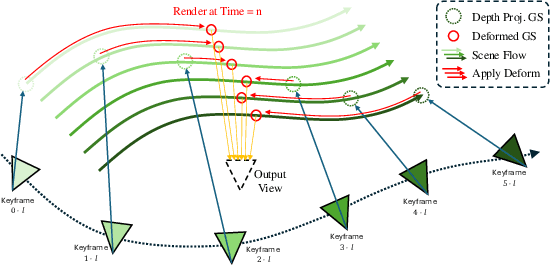
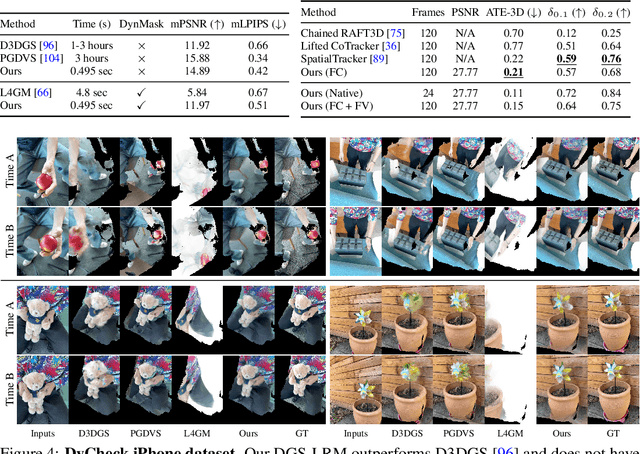

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
Towards Affordance-Aware Articulation Synthesis for Rigged Objects
Jan 21, 2025Rigged objects are commonly used in artist pipelines, as they can flexibly adapt to different scenes and postures. However, articulating the rigs into realistic affordance-aware postures (e.g., following the context, respecting the physics and the personalities of the object) remains time-consuming and heavily relies on human labor from experienced artists. In this paper, we tackle the novel problem and design A3Syn. With a given context, such as the environment mesh and a text prompt of the desired posture, A3Syn synthesizes articulation parameters for arbitrary and open-domain rigged objects obtained from the Internet. The task is incredibly challenging due to the lack of training data, and we do not make any topological assumptions about the open-domain rigs. We propose using 2D inpainting diffusion model and several control techniques to synthesize in-context affordance information. Then, we develop an efficient bone correspondence alignment using a combination of differentiable rendering and semantic correspondence. A3Syn has stable convergence, completes in minutes, and synthesizes plausible affordance on different combinations of in-the-wild object rigs and scenes.
Taming Latent Diffusion Model for Neural Radiance Field Inpainting
Apr 15, 2024Neural Radiance Field (NeRF) is a representation for 3D reconstruction from multi-view images. Despite some recent work showing preliminary success in editing a reconstructed NeRF with diffusion prior, they remain struggling to synthesize reasonable geometry in completely uncovered regions. One major reason is the high diversity of synthetic contents from the diffusion model, which hinders the radiance field from converging to a crisp and deterministic geometry. Moreover, applying latent diffusion models on real data often yields a textural shift incoherent to the image condition due to auto-encoding errors. These two problems are further reinforced with the use of pixel-distance losses. To address these issues, we propose tempering the diffusion model's stochasticity with per-scene customization and mitigating the textural shift with masked adversarial training. During the analyses, we also found the commonly used pixel and perceptual losses are harmful in the NeRF inpainting task. Through rigorous experiments, our framework yields state-of-the-art NeRF inpainting results on various real-world scenes. Project page: https://hubert0527.github.io/MALD-NeRF
Virtual Pets: Animatable Animal Generation in 3D Scenes
Dec 21, 2023Toward unlocking the potential of generative models in immersive 4D experiences, we introduce Virtual Pet, a novel pipeline to model realistic and diverse motions for target animal species within a 3D environment. To circumvent the limited availability of 3D motion data aligned with environmental geometry, we leverage monocular internet videos and extract deformable NeRF representations for the foreground and static NeRF representations for the background. For this, we develop a reconstruction strategy, encompassing species-level shared template learning and per-video fine-tuning. Utilizing the reconstructed data, we then train a conditional 3D motion model to learn the trajectory and articulation of foreground animals in the context of 3D backgrounds. We showcase the efficacy of our pipeline with comprehensive qualitative and quantitative evaluations using cat videos. We also demonstrate versatility across unseen cats and indoor environments, producing temporally coherent 4D outputs for enriched virtual experiences.
DreaMo: Articulated 3D Reconstruction From A Single Casual Video
Dec 07, 2023



Articulated 3D reconstruction has valuable applications in various domains, yet it remains costly and demands intensive work from domain experts. Recent advancements in template-free learning methods show promising results with monocular videos. Nevertheless, these approaches necessitate a comprehensive coverage of all viewpoints of the subject in the input video, thus limiting their applicability to casually captured videos from online sources. In this work, we study articulated 3D shape reconstruction from a single and casually captured internet video, where the subject's view coverage is incomplete. We propose DreaMo that jointly performs shape reconstruction while solving the challenging low-coverage regions with view-conditioned diffusion prior and several tailored regularizations. In addition, we introduce a skeleton generation strategy to create human-interpretable skeletons from the learned neural bones and skinning weights. We conduct our study on a self-collected internet video collection characterized by incomplete view coverage. DreaMo shows promising quality in novel-view rendering, detailed articulated shape reconstruction, and skeleton generation. Extensive qualitative and quantitative studies validate the efficacy of each proposed component, and show existing methods are unable to solve correct geometry due to the incomplete view coverage.
Motion-Conditioned Diffusion Model for Controllable Video Synthesis
Apr 27, 2023



Recent advancements in diffusion models have greatly improved the quality and diversity of synthesized content. To harness the expressive power of diffusion models, researchers have explored various controllable mechanisms that allow users to intuitively guide the content synthesis process. Although the latest efforts have primarily focused on video synthesis, there has been a lack of effective methods for controlling and describing desired content and motion. In response to this gap, we introduce MCDiff, a conditional diffusion model that generates a video from a starting image frame and a set of strokes, which allow users to specify the intended content and dynamics for synthesis. To tackle the ambiguity of sparse motion inputs and achieve better synthesis quality, MCDiff first utilizes a flow completion model to predict the dense video motion based on the semantic understanding of the video frame and the sparse motion control. Then, the diffusion model synthesizes high-quality future frames to form the output video. We qualitatively and quantitatively show that MCDiff achieves the state-the-of-art visual quality in stroke-guided controllable video synthesis. Additional experiments on MPII Human Pose further exhibit the capability of our model on diverse content and motion synthesis.
InfiniCity: Infinite-Scale City Synthesis
Jan 23, 2023Toward infinite-scale 3D city synthesis, we propose a novel framework, InfiniCity, which constructs and renders an unconstrainedly large and 3D-grounded environment from random noises. InfiniCity decomposes the seemingly impractical task into three feasible modules, taking advantage of both 2D and 3D data. First, an infinite-pixel image synthesis module generates arbitrary-scale 2D maps from the bird's-eye view. Next, an octree-based voxel completion module lifts the generated 2D map to 3D octrees. Finally, a voxel-based neural rendering module texturizes the voxels and renders 2D images. InfiniCity can thus synthesize arbitrary-scale and traversable 3D city environments, and allow flexible and interactive editing from users. We quantitatively and qualitatively demonstrate the efficacy of the proposed framework. Project page: https://hubert0527.github.io/infinicity/
Unveiling The Mask of Position-Information Pattern Through the Mist of Image Features
Jun 02, 2022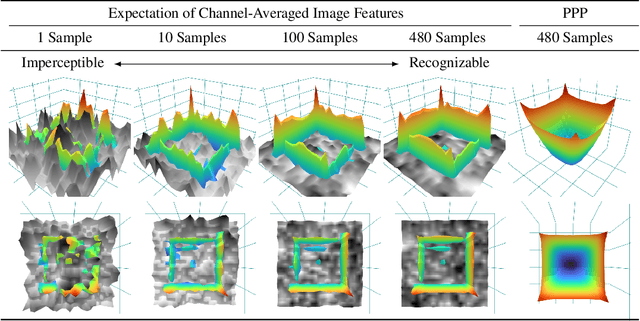
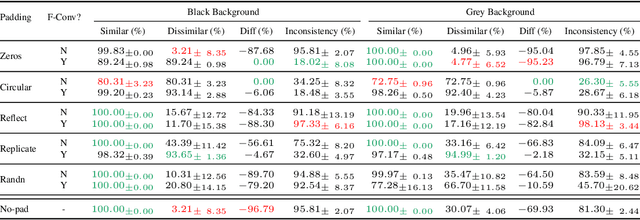
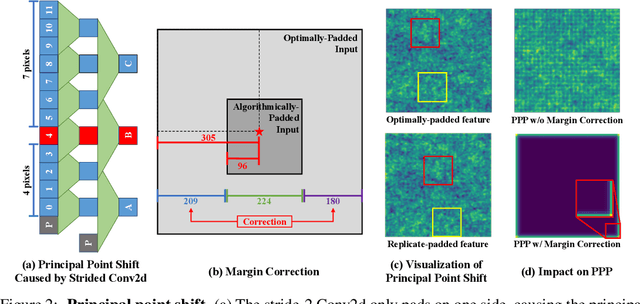
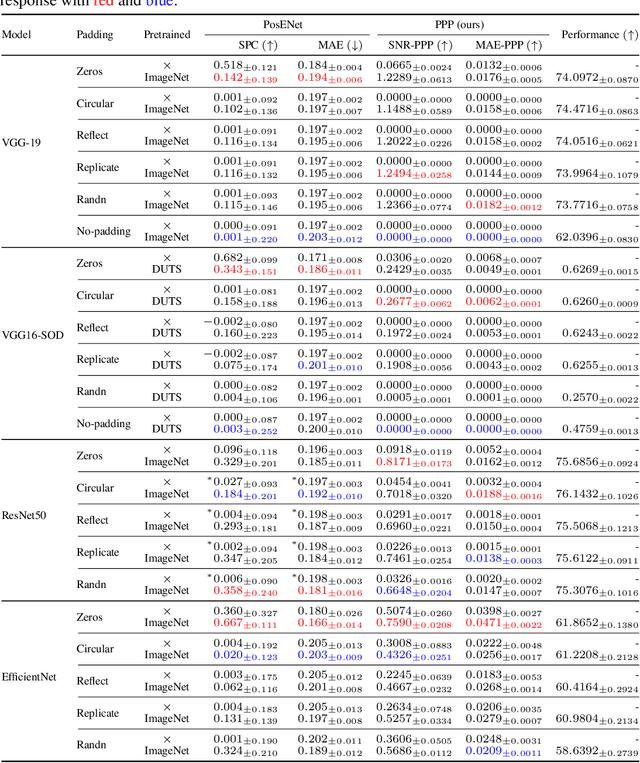
Recent studies show that paddings in convolutional neural networks encode absolute position information which can negatively affect the model performance for certain tasks. However, existing metrics for quantifying the strength of positional information remain unreliable and frequently lead to erroneous results. To address this issue, we propose novel metrics for measuring (and visualizing) the encoded positional information. We formally define the encoded information as PPP (Position-information Pattern from Padding) and conduct a series of experiments to study its properties as well as its formation. The proposed metrics measure the presence of positional information more reliably than the existing metrics based on PosENet and a test in F-Conv. We also demonstrate that for any extant (and proposed) padding schemes, PPP is primarily a learning artifact and is less dependent on the characteristics of the underlying padding schemes.
InfinityGAN: Towards Infinite-Resolution Image Synthesis
Apr 08, 2021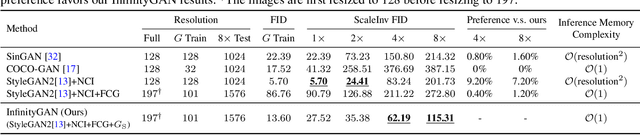
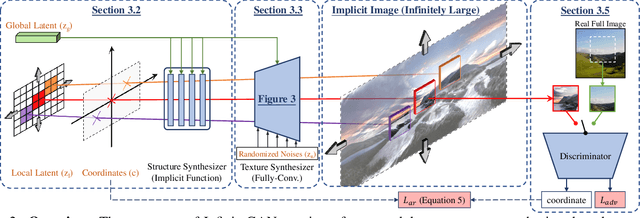
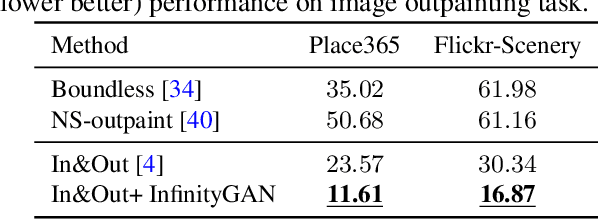
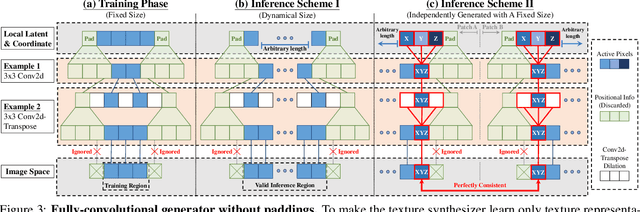
We present InfinityGAN, a method to generate arbitrary-resolution images. The problem is associated with several key challenges. First, scaling existing models to a high resolution is resource-constrained, both in terms of computation and availability of high-resolution training data. Infinity-GAN trains and infers patch-by-patch seamlessly with low computational resources. Second, large images should be locally and globally consistent, avoid repetitive patterns, and look realistic. To address these, InfinityGAN takes global appearance, local structure and texture into account.With this formulation, we can generate images with resolution and level of detail not attainable before. Experimental evaluation supports that InfinityGAN generates imageswith superior global structure compared to baselines at the same time featuring parallelizable inference. Finally, we how several applications unlocked by our approach, such as fusing styles spatially, multi-modal outpainting and image inbetweening at arbitrary input and output resolutions