 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextured Gaussians for Enhanced 3D Scene Appearance Modeling
Nov 27, 2024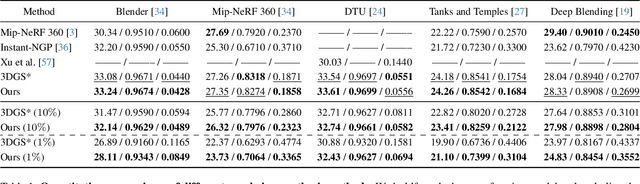
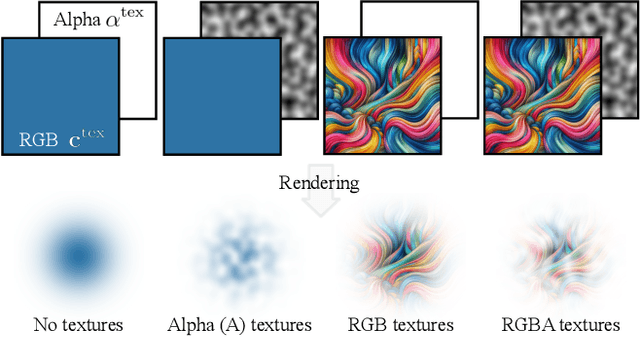

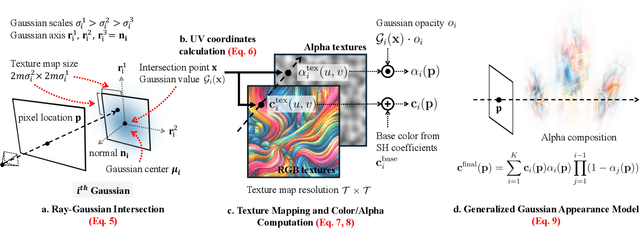
3D Gaussian Splatting (3DGS) has recently emerged as a state-of-the-art 3D reconstruction and rendering technique due to its high-quality results and fast training and rendering time. However, pixels covered by the same Gaussian are always shaded in the same color up to a Gaussian falloff scaling factor. Furthermore, the finest geometric detail any individual Gaussian can represent is a simple ellipsoid. These properties of 3DGS greatly limit the expressivity of individual Gaussian primitives. To address these issues, we draw inspiration from texture and alpha mapping in traditional graphics and integrate it with 3DGS. Specifically, we propose a new generalized Gaussian appearance representation that augments each Gaussian with alpha~(A), RGB, or RGBA texture maps to model spatially varying color and opacity across the extent of each Gaussian. As such, each Gaussian can represent a richer set of texture patterns and geometric structures, instead of just a single color and ellipsoid as in naive Gaussian Splatting. Surprisingly, we found that the expressivity of Gaussians can be greatly improved by using alpha-only texture maps, and further augmenting Gaussians with RGB texture maps achieves the highest expressivity. We validate our method on a wide variety of standard benchmark datasets and our own custom captures at both the object and scene levels. We demonstrate image quality improvements over existing methods while using a similar or lower number of Gaussians.
Taming Latent Diffusion Model for Neural Radiance Field Inpainting
Apr 15, 2024Neural Radiance Field (NeRF) is a representation for 3D reconstruction from multi-view images. Despite some recent work showing preliminary success in editing a reconstructed NeRF with diffusion prior, they remain struggling to synthesize reasonable geometry in completely uncovered regions. One major reason is the high diversity of synthetic contents from the diffusion model, which hinders the radiance field from converging to a crisp and deterministic geometry. Moreover, applying latent diffusion models on real data often yields a textural shift incoherent to the image condition due to auto-encoding errors. These two problems are further reinforced with the use of pixel-distance losses. To address these issues, we propose tempering the diffusion model's stochasticity with per-scene customization and mitigating the textural shift with masked adversarial training. During the analyses, we also found the commonly used pixel and perceptual losses are harmful in the NeRF inpainting task. Through rigorous experiments, our framework yields state-of-the-art NeRF inpainting results on various real-world scenes. Project page: https://hubert0527.github.io/MALD-NeRF
Consistent View Synthesis with Pose-Guided Diffusion Models
Mar 30, 2023Novel view synthesis from a single image has been a cornerstone problem for many Virtual Reality applications that provide immersive experiences. However, most existing techniques can only synthesize novel views within a limited range of camera motion or fail to generate consistent and high-quality novel views under significant camera movement. In this work, we propose a pose-guided diffusion model to generate a consistent long-term video of novel views from a single image. We design an attention layer that uses epipolar lines as constraints to facilitate the association between different viewpoints. Experimental results on synthetic and real-world datasets demonstrate the effectiveness of the proposed diffusion model against state-of-the-art transformer-based and GAN-based approaches.