 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextured Gaussians for Enhanced 3D Scene Appearance Modeling
Nov 27, 2024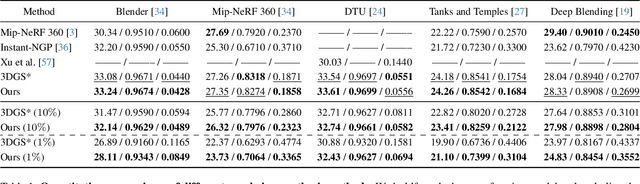
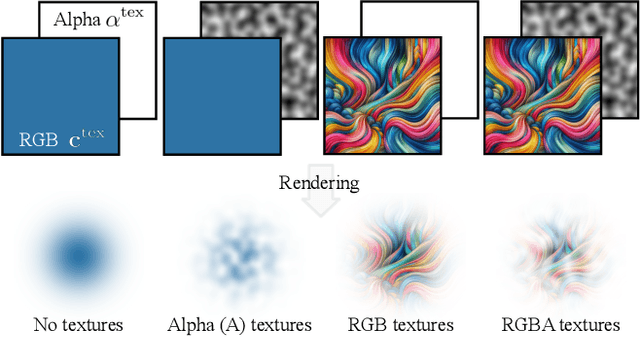

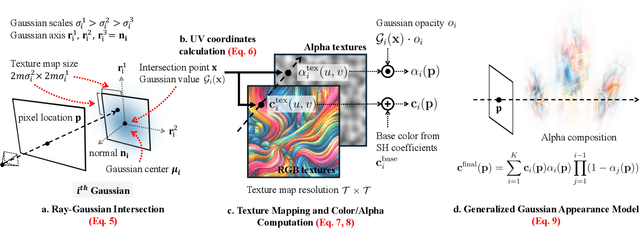
3D Gaussian Splatting (3DGS) has recently emerged as a state-of-the-art 3D reconstruction and rendering technique due to its high-quality results and fast training and rendering time. However, pixels covered by the same Gaussian are always shaded in the same color up to a Gaussian falloff scaling factor. Furthermore, the finest geometric detail any individual Gaussian can represent is a simple ellipsoid. These properties of 3DGS greatly limit the expressivity of individual Gaussian primitives. To address these issues, we draw inspiration from texture and alpha mapping in traditional graphics and integrate it with 3DGS. Specifically, we propose a new generalized Gaussian appearance representation that augments each Gaussian with alpha~(A), RGB, or RGBA texture maps to model spatially varying color and opacity across the extent of each Gaussian. As such, each Gaussian can represent a richer set of texture patterns and geometric structures, instead of just a single color and ellipsoid as in naive Gaussian Splatting. Surprisingly, we found that the expressivity of Gaussians can be greatly improved by using alpha-only texture maps, and further augmenting Gaussians with RGB texture maps achieves the highest expressivity. We validate our method on a wide variety of standard benchmark datasets and our own custom captures at both the object and scene levels. We demonstrate image quality improvements over existing methods while using a similar or lower number of Gaussians.
IRIS: Inverse Rendering of Indoor Scenes from Low Dynamic Range Images
Jan 23, 2024While numerous 3D reconstruction and novel-view synthesis methods allow for photorealistic rendering of a scene from multi-view images easily captured with consumer cameras, they bake illumination in their representations and fall short of supporting advanced applications like material editing, relighting, and virtual object insertion. The reconstruction of physically based material properties and lighting via inverse rendering promises to enable such applications. However, most inverse rendering techniques require high dynamic range (HDR) images as input, a setting that is inaccessible to most users. We present a method that recovers the physically based material properties and spatially-varying HDR lighting of a scene from multi-view, low-dynamic-range (LDR) images. We model the LDR image formation process in our inverse rendering pipeline and propose a novel optimization strategy for material, lighting, and a camera response model. We evaluate our approach with synthetic and real scenes compared to the state-of-the-art inverse rendering methods that take either LDR or HDR input. Our method outperforms existing methods taking LDR images as input, and allows for highly realistic relighting and object insertion.
Learning Neural Duplex Radiance Fields for Real-Time View Synthesis
Apr 20, 2023



Neural radiance fields (NeRFs) enable novel view synthesis with unprecedented visual quality. However, to render photorealistic images, NeRFs require hundreds of deep multilayer perceptron (MLP) evaluations - for each pixel. This is prohibitively expensive and makes real-time rendering infeasible, even on powerful modern GPUs. In this paper, we propose a novel approach to distill and bake NeRFs into highly efficient mesh-based neural representations that are fully compatible with the massively parallel graphics rendering pipeline. We represent scenes as neural radiance features encoded on a two-layer duplex mesh, which effectively overcomes the inherent inaccuracies in 3D surface reconstruction by learning the aggregated radiance information from a reliable interval of ray-surface intersections. To exploit local geometric relationships of nearby pixels, we leverage screen-space convolutions instead of the MLPs used in NeRFs to achieve high-quality appearance. Finally, the performance of the whole framework is further boosted by a novel multi-view distillation optimization strategy. We demonstrate the effectiveness and superiority of our approach via extensive experiments on a range of standard datasets.