 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Duplex Radiance Fields for Real-Time View Synthesis
Apr 20, 2023



Neural radiance fields (NeRFs) enable novel view synthesis with unprecedented visual quality. However, to render photorealistic images, NeRFs require hundreds of deep multilayer perceptron (MLP) evaluations - for each pixel. This is prohibitively expensive and makes real-time rendering infeasible, even on powerful modern GPUs. In this paper, we propose a novel approach to distill and bake NeRFs into highly efficient mesh-based neural representations that are fully compatible with the massively parallel graphics rendering pipeline. We represent scenes as neural radiance features encoded on a two-layer duplex mesh, which effectively overcomes the inherent inaccuracies in 3D surface reconstruction by learning the aggregated radiance information from a reliable interval of ray-surface intersections. To exploit local geometric relationships of nearby pixels, we leverage screen-space convolutions instead of the MLPs used in NeRFs to achieve high-quality appearance. Finally, the performance of the whole framework is further boosted by a novel multi-view distillation optimization strategy. We demonstrate the effectiveness and superiority of our approach via extensive experiments on a range of standard datasets.
Learning Spatio-Temporal Downsampling for Effective Video Upscaling
Mar 15, 2022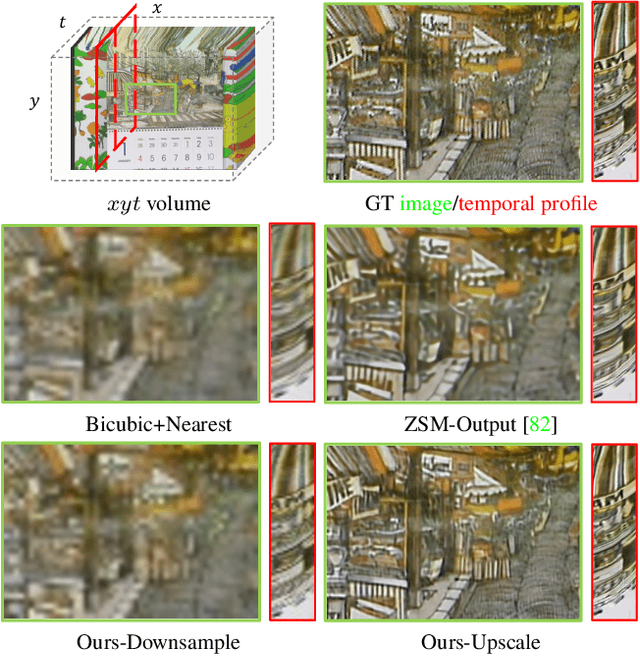
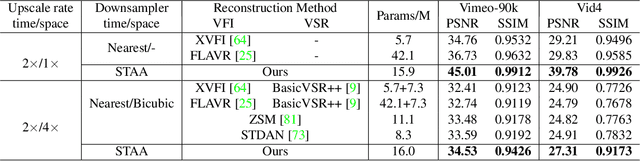
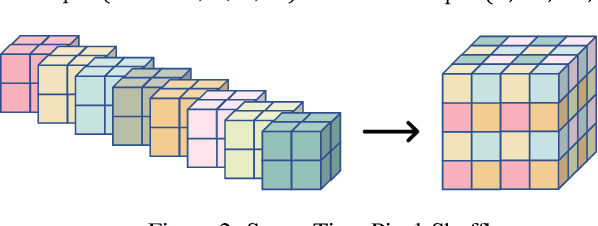
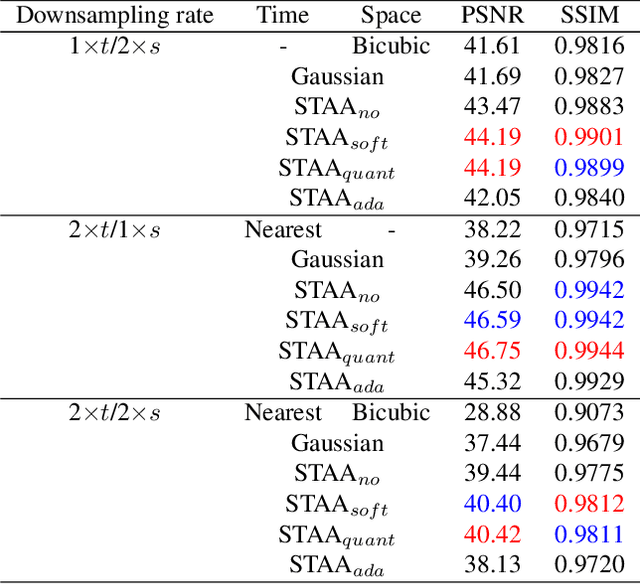
Downsampling is one of the most basic image processing operations. Improper spatio-temporal downsampling applied on videos can cause aliasing issues such as moir\'e patterns in space and the wagon-wheel effect in time. Consequently, the inverse task of upscaling a low-resolution, low frame-rate video in space and time becomes a challenging ill-posed problem due to information loss and aliasing artifacts. In this paper, we aim to solve the space-time aliasing problem by learning a spatio-temporal downsampler. Towards this goal, we propose a neural network framework that jointly learns spatio-temporal downsampling and upsampling. It enables the downsampler to retain the key patterns of the original video and maximizes the reconstruction performance of the upsampler. To make the downsamping results compatible with popular image and video storage formats, the downsampling results are encoded to uint8 with a differentiable quantization layer. To fully utilize the space-time correspondences, we propose two novel modules for explicit temporal propagation and space-time feature rearrangement. Experimental results show that our proposed method significantly boosts the space-time reconstruction quality by preserving spatial textures and motion patterns in both downsampling and upscaling. Moreover, our framework enables a variety of applications, including arbitrary video resampling, blurry frame reconstruction, and efficient video storage.
Programmable Spectral Filter Arrays for Hyperspectral Imaging
Sep 29, 2021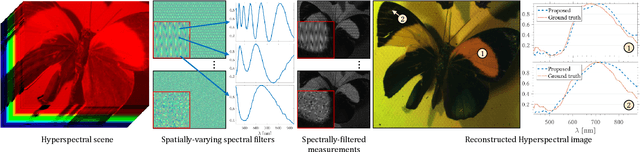
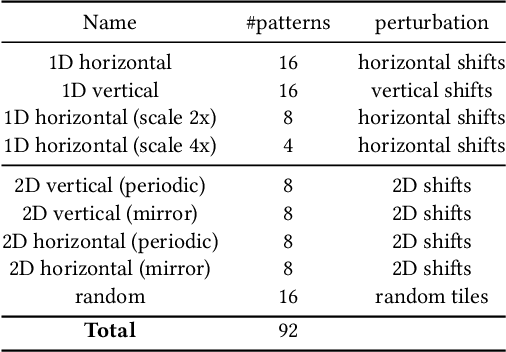

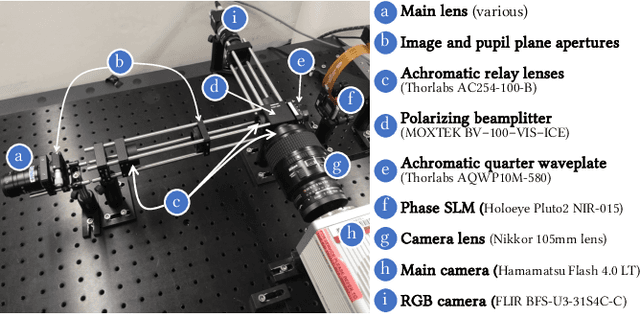
Modulating the spectral dimension of light has numerous applications in computational imaging. While there are many techniques for achieving this, there are few, if any, for implementing a spatially-varying and programmable spectral filter. This paper provides an optical design for implementing such a capability. Our key insight is that spatially-varying spectral modulation can be implemented using a liquid crystal spatial light modulator since it provides an array of liquid crystal cells, each of which can be purposed to act as a programmable spectral filter array. Relying on this insight, we provide an optical schematic and an associated lab prototype for realizing the capability, as well as address the associated challenges at implementation using optical and computational innovations. We show a number of unique operating points with our prototype including single- and multi-image hyperspectral imaging, as well as its application in material identification.
Photosequencing of Motion Blur using Short and Long Exposures
Dec 11, 2019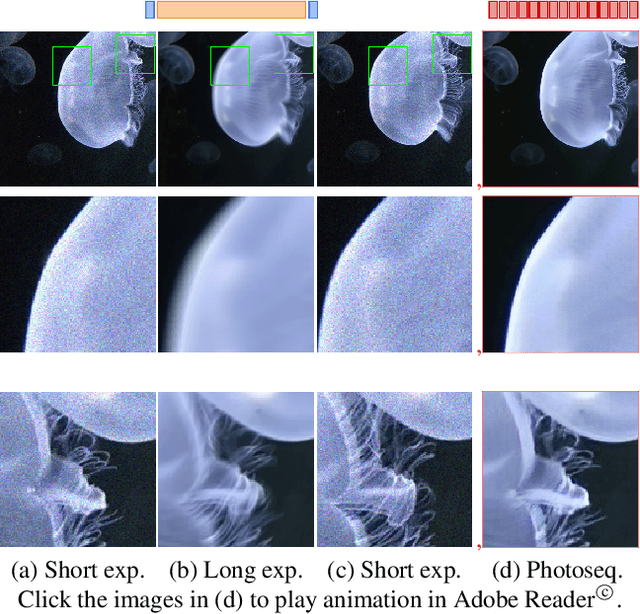

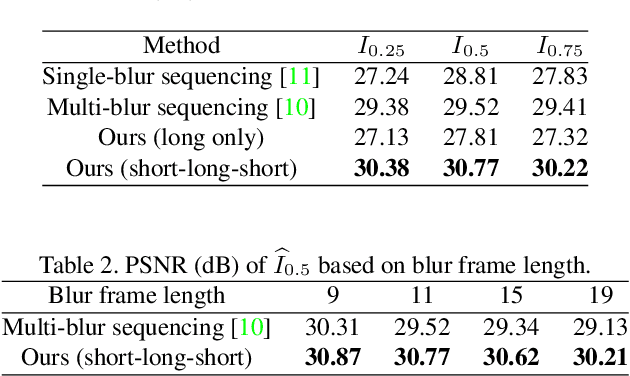
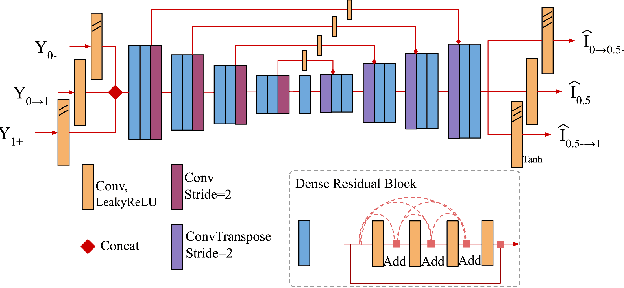
Photosequencing aims to transform a motion blurred image to a sequence of sharp images. This problem is challenging due to the inherent ambiguities in temporal ordering as well as the recovery of lost spatial textures due to blur. Adopting a computational photography approach, we propose to capture two short exposure images, along with the original blurred long exposure image to aid in the aforementioned challenges. Post-capture, we recover the sharp photosequence using a novel blur decomposition strategy that recursively splits the long exposure image into smaller exposure intervals. We validate the approach by capturing a variety of scenes with interesting motions using machine vision cameras programmed to capture short and long exposure sequences. Our experimental results show that the proposed method resolves both fast and fine motions better than prior works.