 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable and Robust Wavefront Sensing via Self-Reference Interferometry
Apr 04, 2026Wavefront sensing involves estimating the phase and intensity of light, enabling a wide range of imaging applications, from adaptive optics and astronomy to biomedical imaging. Since conventional image sensors can only measure the spatial intensity distribution, phase retrieval arises as the central problem in wavefront sensing. Conventional interferometric approaches like phase-shifting interferometry (PSI) can recover phase information, but they rely on a stable reference beam that is difficult to realize in practical settings. To overcome this limitation, we propose a novel self-reference framework that relies on interference between shifted copies of the incoming wave; this results in pairwise phase differences between shifted pixels. We formulate an analytical solution for the complete phase retrieval based on the propagation of these differences across a connected graph. Furthermore, we provide a theoretical analysis of optimal measurement patterns, proving that co-prime shifts guarantee a connected graph and bound worst-case error accumulation, yielding a provably robust method. Extensive simulations demonstrate that complete phase profiles can be recovered from as few as eight shifted measurements, outperforming several existing approaches. Finally, we validate our framework using a hardware prototype, demonstrating real experiments for optical phase profile recovery, auto-refocusing, and imaging through scattering media.
The Surprising Effectiveness of Noise Pretraining for Implicit Neural Representations
Mar 30, 2026The approximation and convergence properties of implicit neural representations (INRs) are known to be highly sensitive to parameter initialization strategies. While several data-driven initialization methods demonstrate significant improvements over standard random sampling, the reasons for their success -- specifically, whether they encode classical statistical signal priors or more complex features -- remain poorly understood. In this study, we explore this phenomenon through a series of experimental analyses leveraging noise pretraining. We pretrain INRs on diverse noise classes (e.g., Gaussian, Dead Leaves, Spectral) and measure their ability to both fit unseen signals and encode priors for an inverse imaging task (denoising). Our analyses on image and video data reveal a surprising finding: simply pretraining on unstructured noise (Uniform, Gaussian) dramatically improves signal fitting capacity compared to all other baselines. However, unstructured noise also yields poor deep image priors for denoising. In contrast, we also find that noise with the classic $1/|f^α|$ spectral structure of natural images achieves an excellent balance of signal fitting and inverse imaging capabilities, performing on par with the best data-driven initialization methods. This finding enables more efficient INR training in applications lacking sufficient prior domain-specific data. For more details, visit project page at https://kushalvyas.github.io/noisepretraining.html
Thermal is Always Wild: Characterizing and Addressing Challenges in Thermal-Only Novel View Synthesis
Mar 20, 2026Thermal cameras provide reliable visibility in darkness and adverse conditions, but thermal imagery remains significantly harder to use for novel view synthesis (NVS) than visible-light images. This difficulty stems primarily from two characteristics of affordable thermal sensors. First, thermal images have extremely low dynamic range, which weakens appearance cues and limits the gradients available for optimization. Second, thermal data exhibit rapid frame-to-frame photometric fluctuations together with slow radiometric drift, both of which destabilize correspondence estimation and create high-frequency floater artifacts during view synthesis, particularly when no RGB guidance (beyond camera pose) is available. Guided by these observations, we introduce a lightweight preprocessing and splatting pipeline that expands usable dynamic range and stabilizes per-frame photometry. Our approach achieves state-of-the-art performance across thermal-only NVS benchmarks, without requiring any dataset-specific tuning.
Implicit Neural Representation of Waveform Measurements in Power Systems Waveform Data Analysis
May 14, 2025There is currently a paradigm shift in several power system monitoring applications, such as incipient fault detection and monitoring inverter-based resources, to transition from traditional phasor analytics to more informative waveform analytics. This paper contributes to this transition by developing a novel approach to modeling voltage and current waveform measurements using implicit neural representations (INRs). INRs are continuous function approximators that are recently used in vision and signal processing. The proposed INR models are specifically designed to meet the requirements of waveform analytics in power systems, such as by using sinusoidal activation functions that capture the periodic nature of voltage and current waveforms. We also propose extended models that can efficiently represent correlated waveforms, such as three-phase waveforms and synchro-waveforms. Real-world case studies demonstrate the effectiveness of the proposed INR models in terms of accuracy (<1-2% MSE) and model size (4-6x compression). We also investigate the application of INR models in oscillation monitoring, for single mode oscillations and dual mode modulated oscillations.
Bias for Action: Video Implicit Neural Representations with Bias Modulation
Jan 16, 2025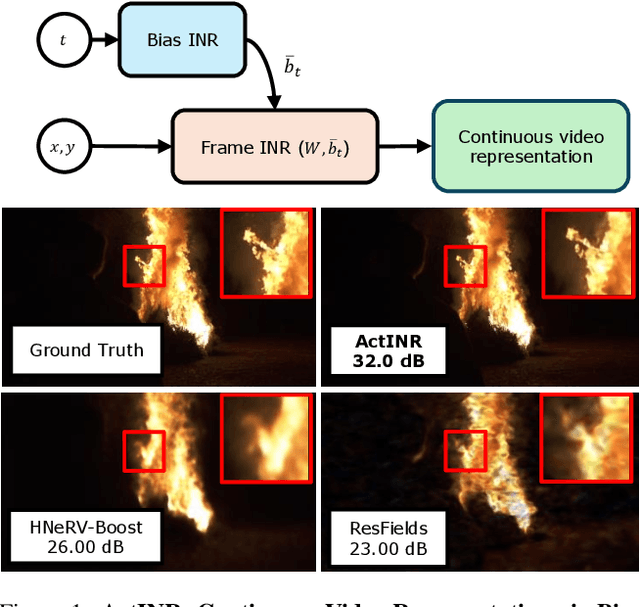
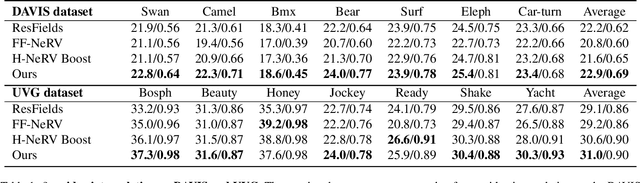
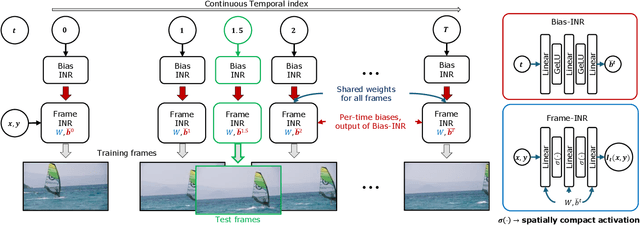

We propose a new continuous video modeling framework based on implicit neural representations (INRs) called ActINR. At the core of our approach is the observation that INRs can be considered as a learnable dictionary, with the shapes of the basis functions governed by the weights of the INR, and their locations governed by the biases. Given compact non-linear activation functions, we hypothesize that an INR's biases are suitable to capture motion across images, and facilitate compact representations for video sequences. Using these observations, we design ActINR to share INR weights across frames of a video sequence, while using unique biases for each frame. We further model the biases as the output of a separate INR conditioned on time index to promote smoothness. By training the video INR and this bias INR together, we demonstrate unique capabilities, including $10\times$ video slow motion, $4\times$ spatial super resolution along with $2\times$ slow motion, denoising, and video inpainting. ActINR performs remarkably well across numerous video processing tasks (often achieving more than 6dB improvement), setting a new standard for continuous modeling of videos.
Implicit Neural Representations and the Algebra of Complex Wavelets
Oct 01, 2023



Implicit neural representations (INRs) have arisen as useful methods for representing signals on Euclidean domains. By parameterizing an image as a multilayer perceptron (MLP) on Euclidean space, INRs effectively represent signals in a way that couples spatial and spectral features of the signal that is not obvious in the usual discrete representation, paving the way for continuous signal processing and machine learning approaches that were not previously possible. Although INRs using sinusoidal activation functions have been studied in terms of Fourier theory, recent works have shown the advantage of using wavelets instead of sinusoids as activation functions, due to their ability to simultaneously localize in both frequency and space. In this work, we approach such INRs and demonstrate how they resolve high-frequency features of signals from coarse approximations done in the first layer of the MLP. This leads to multiple prescriptions for the design of INR architectures, including the use of complex wavelets, decoupling of low and band-pass approximations, and initialization schemes based on the singularities of the desired signal.
Thermal Spread Functions (TSF): Physics-guided Material Classification
Apr 03, 2023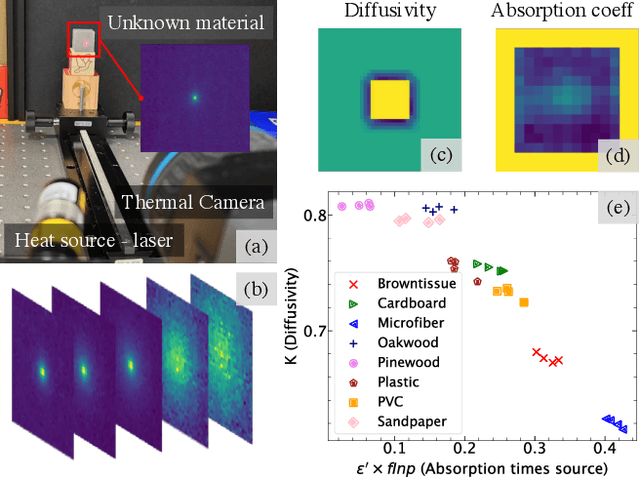
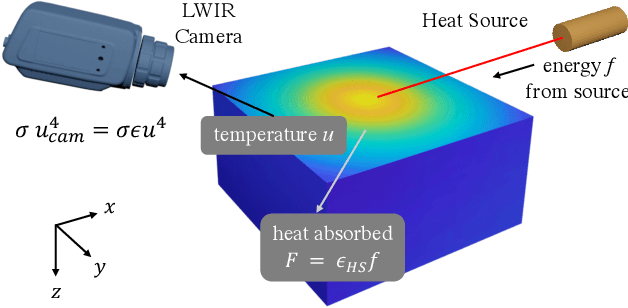
Robust and non-destructive material classification is a challenging but crucial first-step in numerous vision applications. We propose a physics-guided material classification framework that relies on thermal properties of the object. Our key observation is that the rate of heating and cooling of an object depends on the unique intrinsic properties of the material, namely the emissivity and diffusivity. We leverage this observation by gently heating the objects in the scene with a low-power laser for a fixed duration and then turning it off, while a thermal camera captures measurements during the heating and cooling process. We then take this spatial and temporal "thermal spread function" (TSF) to solve an inverse heat equation using the finite-differences approach, resulting in a spatially varying estimate of diffusivity and emissivity. These tuples are then used to train a classifier that produces a fine-grained material label at each spatial pixel. Our approach is extremely simple requiring only a small light source (low power laser) and a thermal camera, and produces robust classification results with 86% accuracy over 16 classes.
WIRE: Wavelet Implicit Neural Representations
Jan 05, 2023Implicit neural representations (INRs) have recently advanced numerous vision-related areas. INR performance depends strongly on the choice of the nonlinear activation function employed in its multilayer perceptron (MLP) network. A wide range of nonlinearities have been explored, but, unfortunately, current INRs designed to have high accuracy also suffer from poor robustness (to signal noise, parameter variation, etc.). Inspired by harmonic analysis, we develop a new, highly accurate and robust INR that does not exhibit this tradeoff. Wavelet Implicit neural REpresentation (WIRE) uses a continuous complex Gabor wavelet activation function that is well-known to be optimally concentrated in space-frequency and to have excellent biases for representing images. A wide range of experiments (image denoising, image inpainting, super-resolution, computed tomography reconstruction, image overfitting, and novel view synthesis with neural radiance fields) demonstrate that WIRE defines the new state of the art in INR accuracy, training time, and robustness.
Foveated Thermal Computational Imaging in the Wild Using All-Silicon Meta-Optics
Dec 13, 2022Foveated imaging provides a better tradeoff between situational awareness (field of view) and resolution and is critical in long-wavelength infrared regimes because of the size, weight, power, and cost of thermal sensors. We demonstrate computational foveated imaging by exploiting the ability of a meta-optical frontend to discriminate between different polarization states and a computational backend to reconstruct the captured image/video. The frontend is a three-element optic: the first element which we call the "foveal" element is a metalens that focuses s-polarized light at a distance of $f_1$ without affecting the p-polarized light; the second element which we call the "perifoveal" element is another metalens that focuses p-polarized light at a distance of $f_2$ without affecting the s-polarized light. The third element is a freely rotating polarizer that dynamically changes the mixing ratios between the two polarization states. Both the foveal element (focal length = 150mm; diameter = 75mm), and the perifoveal element (focal length = 25mm; diameter = 25mm) were fabricated as polarization-sensitive, all-silicon, meta surfaces resulting in a large-aperture, 1:6 foveal expansion, thermal imaging capability. A computational backend then utilizes a deep image prior to separate the resultant multiplexed image or video into a foveated image consisting of a high-resolution center and a lower-resolution large field of view context. We build a first-of-its-kind prototype system and demonstrate 12 frames per second real-time, thermal, foveated image, and video capture in the wild.
TITAN: Bringing The Deep Image Prior to Implicit Representations
Nov 01, 2022We study the interpolation capabilities of implicit neural representations (INRs) of images. In principle, INRs promise a number of advantages, such as continuous derivatives and arbitrary sampling, being freed from the restrictions of a raster grid. However, empirically, INRs have been observed to poorly interpolate between the pixels of the fit image; in other words, they do not inherently possess a suitable prior for natural images. In this paper, we propose to address and improve INRs' interpolation capabilities by explicitly integrating image prior information into the INR architecture via deep decoder, a specific implementation of the deep image prior (DIP). Our method, which we call TITAN, leverages a residual connection from the input which enables integrating the principles of the grid-based DIP into the grid-free INR. Through super-resolution and computed tomography experiments, we demonstrate that our method significantly improves upon classic INRs, thanks to the induced natural image bias. We also find that by constraining the weights to be sparse, image quality and sharpness are enhanced, increasing the Lipschitz constant.