 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias for Action: Video Implicit Neural Representations with Bias Modulation
Jan 16, 2025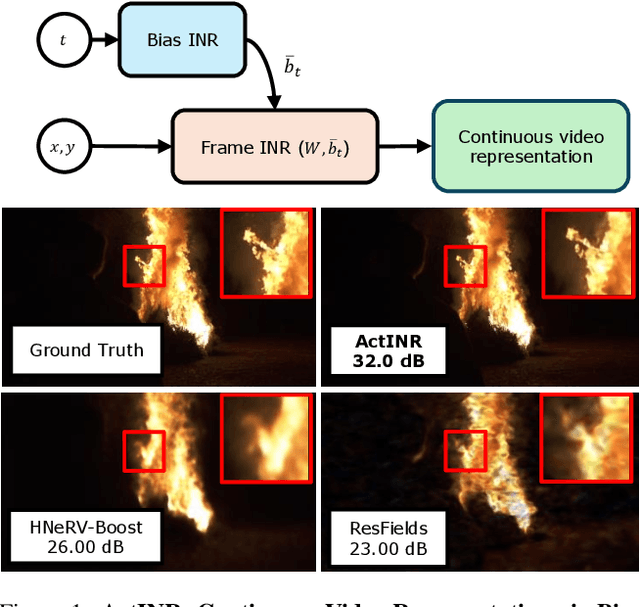
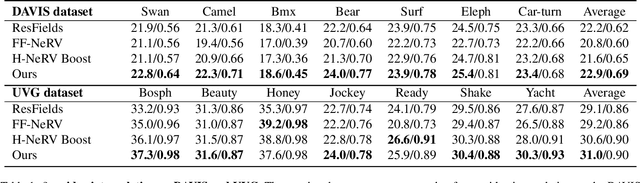
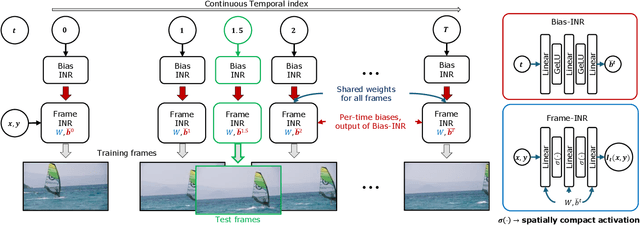

We propose a new continuous video modeling framework based on implicit neural representations (INRs) called ActINR. At the core of our approach is the observation that INRs can be considered as a learnable dictionary, with the shapes of the basis functions governed by the weights of the INR, and their locations governed by the biases. Given compact non-linear activation functions, we hypothesize that an INR's biases are suitable to capture motion across images, and facilitate compact representations for video sequences. Using these observations, we design ActINR to share INR weights across frames of a video sequence, while using unique biases for each frame. We further model the biases as the output of a separate INR conditioned on time index to promote smoothness. By training the video INR and this bias INR together, we demonstrate unique capabilities, including $10\times$ video slow motion, $4\times$ spatial super resolution along with $2\times$ slow motion, denoising, and video inpainting. ActINR performs remarkably well across numerous video processing tasks (often achieving more than 6dB improvement), setting a new standard for continuous modeling of videos.
Optimal HDR and Depth from Dual Cameras
Mar 12, 2020
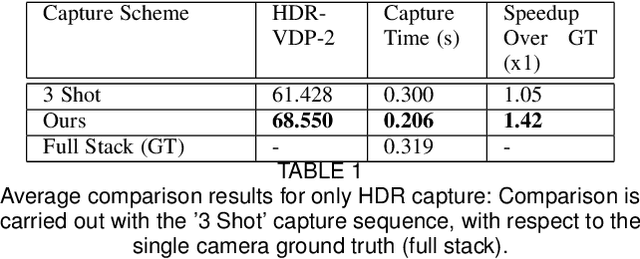
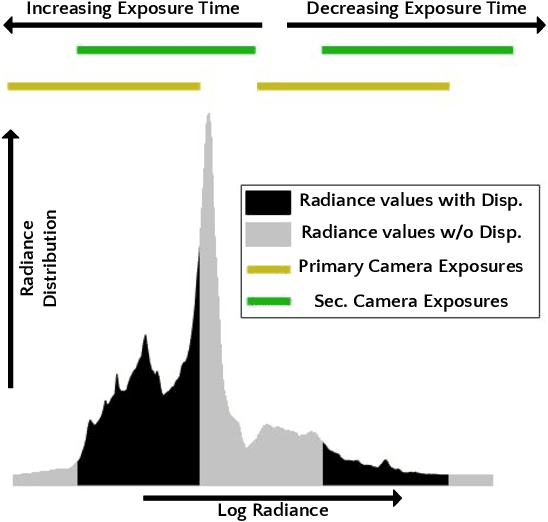
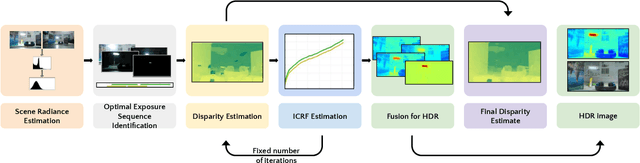
Dual camera systems have assisted in the proliferation of various applications, such as optical zoom, low-light imaging and High Dynamic Range (HDR) imaging. In this work, we explore an optimal method for capturing the scene HDR and disparity map using dual camera setups. Hasinoff et al. (2010) have developed a noise optimal framework for HDR capture from a single camera. We generalize this to the dual camera set-up for estimating both HDR and disparity map. It may seem that dual camera systems can capture HDR in a shorter time. However, disparity estimation is a necessary step, which requires overlap among the images captured by the two cameras. This may lead to an increase in the capture time. To address this conflicting requirement, we propose a novel framework to find the optimal exposure and ISO sequence by minimizing the capture time under the constraints of an upper bound on the disparity error and a lower bound on the per-exposure SNR. We show that the resulting optimization problem is non-convex in general and propose an appropriate initialization technique. To obtain the HDR and disparity map from the optimal capture sequence, we propose a pipeline which alternates between estimating the camera ICRFs and the scene disparity map. We demonstrate that our optimal capture sequence leads to better results than other possible capture sequences. Our results are also close to those obtained by capturing the full stereo stack spanning the entire dynamic range. Finally, we present for the first time a stereo HDR dataset consisting of dense ISO and exposure stack captured from a smartphone dual camera. The dataset consists of 6 scenes, with an average of 142 exposure-ISO image sequence per scene.
A Unified Learning Based Framework for Light Field Reconstruction from Coded Projections
Dec 26, 2018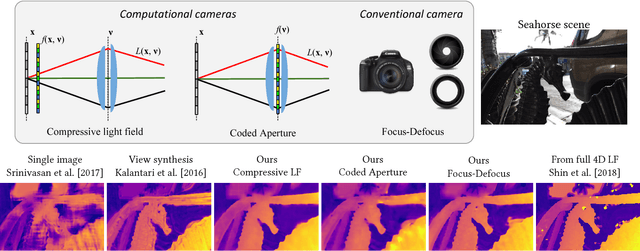
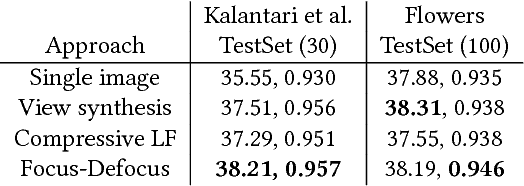
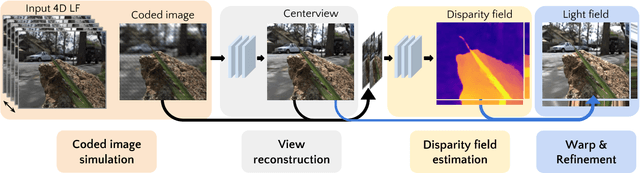
Light field presents a rich way to represent the 3D world by capturing the spatio-angular dimensions of the visual signal. However, the popular way of capturing light field (LF) via a plenoptic camera presents spatio-angular resolution trade-off. Computational imaging techniques such as compressive light field and programmable coded aperture reconstruct full sensor resolution LF from coded projections obtained by multiplexing the incoming spatio-angular light field. Here, we present a unified learning framework that can reconstruct LF from a variety of multiplexing schemes with minimal number of coded images as input. We consider three light field capture schemes: heterodyne capture scheme with code placed near the sensor, coded aperture scheme with code at the camera aperture and finally the dual exposure scheme of capturing a focus-defocus pair where there is no explicit coding. Our algorithm consists of three stages 1) we recover the all-in-focus image from the coded image 2) we estimate the disparity maps for all the LF views from the coded image and the all-in-focus image, 3) we then render the LF by warping the all-in-focus image using disparity maps and refine it. For these three stages we propose three deep neural networks - ViewNet, DispairtyNet and RefineNet. Our reconstructions show that our learning algorithm achieves state-of-the-art results for all the three multiplexing schemes. Especially, our LF reconstructions from focus-defocus pair is comparable to other learning-based view synthesis approaches from multiple images. Thus, our work paves the way for capturing high-resolution LF (~ a megapixel) using conventional cameras such as DSLRs. Please check our supplementary materials $\href{https://docs.google.com/presentation/d/1Vr-F8ZskrSd63tvnLfJ2xmEXY6OBc1Rll3XeOAtc11I/}{online}$ to better appreciate the reconstructed light fields.
Learning Light Field Reconstruction from a Single Coded Image
Apr 26, 2018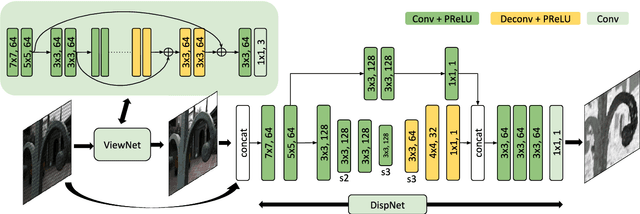



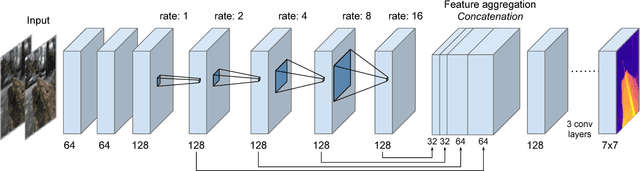
Light field imaging is a rich way of representing the 3D world around us. However, due to limited sensor resolution capturing light field data inherently poses spatio-angular resolution trade-off. In this paper, we propose a deep learning based solution to tackle the resolution trade-off. Specifically, we reconstruct full sensor resolution light field from a single coded image. We propose to do this in three stages 1) reconstruction of center view from the coded image 2) estimating disparity map from the coded image and center view 3) warping center view using the disparity to generate light field. We propose three neural networks for these stages. Our disparity estimation network is trained in an unsupervised manner alleviating the need for ground truth disparity. Our results demonstrate better recovery of parallax from the coded image. Also, we get better results than dictionary learning based approaches both qualitatively and quatitatively.
Solving Inverse Computational Imaging Problems using Deep Pixel-level Prior
Apr 24, 2018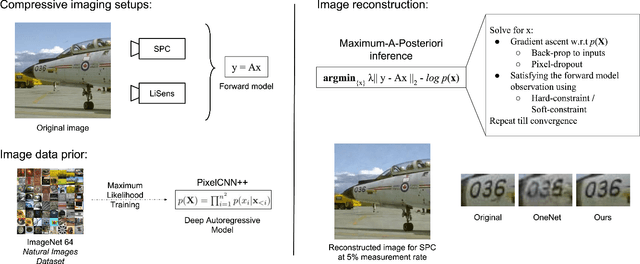



Signal reconstruction is a challenging aspect of computational imaging as it often involves solving ill-posed inverse problems. Recently, deep feed-forward neural networks have led to state-of-the-art results in solving various inverse imaging problems. However, being task specific, these networks have to be learned for each inverse problem. On the other hand, a more flexible approach would be to learn a deep generative model once and then use it as a signal prior for solving various inverse problems. We show that among the various state of the art deep generative models, autoregressive models are especially suitable for our purpose for the following reasons. First, they explicitly model the pixel level dependencies and hence are capable of reconstructing low-level details such as texture patterns and edges better. Second, they provide an explicit expression for the image prior which can then be used for MAP based inference along with the forward model. Third, they can model long range dependencies in images which make them ideal for handling global multiplexing as encountered in various compressive imaging systems. We demonstrate the efficacy of our proposed approach in solving three computational imaging problems: Single Pixel Camera (SPC), LiSens and FlatCam. For both real and simulated cases, we obtain better reconstructions than the state-of-the-art methods in terms of perceptual and quantitative metrics.
Compressive Image Recovery Using Recurrent Generative Model
May 03, 2017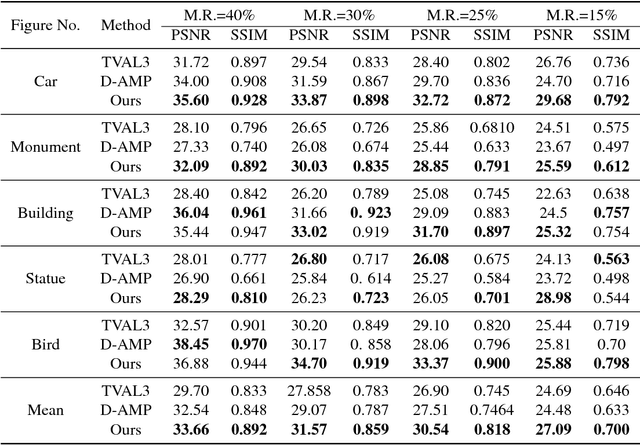



Reconstruction of signals from compressively sensed measurements is an ill-posed problem. In this paper, we leverage the recurrent generative model, RIDE, as an image prior for compressive image reconstruction. Recurrent networks can model long-range dependencies in images and hence are suitable to handle global multiplexing in reconstruction from compressive imaging. We perform MAP inference with RIDE using back-propagation to the inputs and projected gradient method. We propose an entropy thresholding based approach for preserving texture in images well. Our approach shows superior reconstructions compared to recent global reconstruction approaches like D-AMP and TVAL3 on both simulated and real data.