 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 3D Reconstruction with Priors in Test Time
Apr 04, 2026We introduce a test-time framework for multiview Transformers (MVTs) that incorporates priors (e.g., camera poses, intrinsics, and depth) to improve 3D tasks without retraining or modifying pre-trained image-only networks. Rather than feeding priors into the architecture, we cast them as constraints on the predictions and optimize the network at inference time. The optimization loss consists of a self-supervised objective and prior penalty terms. The self-supervised objective captures the compatibility among multi-view predictions and is implemented using photometric or geometric loss between renderings from other views and each view itself. Any available priors are converted into penalty terms on the corresponding output modalities. Across a series of 3D vision benchmarks, including point map estimation and camera pose estimation, our method consistently improves performance over base MVTs by a large margin. On the ETH3D, 7-Scenes, and NRGBD datasets, our method reduces the point-map distance error by more than half compared with the base image-only models. Our method also outperforms retrained prior-aware feed-forward methods, demonstrating the effectiveness of our test-time constrained optimization (TCO) framework for incorporating priors into 3D vision tasks.
Poppy: Polarization-based Plug-and-Play Guidance for Enhancing Monocular Normal Estimation
Mar 29, 2026Monocular surface normal estimators trained on large-scale RGB-normal data often perform poorly in the edge cases of reflective, textureless, and dark surfaces. Polarization encodes surface orientation independently of texture and albedo, offering a physics-based complement for these cases. Existing polarization methods, however, require multi-view capture or specialized training data, limiting generalization. We introduce Poppy, a training-free framework that refines normals from any frozen RGB backbone using single-shot polarization measurements at test time. Keeping backbone weights frozen, Poppy optimizes per-pixel offsets to the input RGB and output normal along with a learned reflectance decomposition. A differentiable rendering layer converts the refined normals into polarization predictions and penalizes mismatches with the observed signal. Across seven benchmarks and three backbone architectures (diffusion, flow, and feed-forward), Poppy reduces mean angular error by 23-26% on synthetic data and 6-16% on real data. These results show that guiding learned RGB-based normal estimators with polarization cues at test time refines normals on challenging surfaces without retraining.
Task-Driven Implicit Representations for Automated Design of LiDAR Systems
May 28, 2025Imaging system design is a complex, time-consuming, and largely manual process; LiDAR design, ubiquitous in mobile devices, autonomous vehicles, and aerial imaging platforms, adds further complexity through unique spatial and temporal sampling requirements. In this work, we propose a framework for automated, task-driven LiDAR system design under arbitrary constraints. To achieve this, we represent LiDAR configurations in a continuous six-dimensional design space and learn task-specific implicit densities in this space via flow-based generative modeling. We then synthesize new LiDAR systems by modeling sensors as parametric distributions in 6D space and fitting these distributions to our learned implicit density using expectation-maximization, enabling efficient, constraint-aware LiDAR system design. We validate our method on diverse tasks in 3D vision, enabling automated LiDAR system design across real-world-inspired applications in face scanning, robotic tracking, and object detection.
TranSplat: Lighting-Consistent Cross-Scene Object Transfer with 3D Gaussian Splatting
Mar 28, 2025We present TranSplat, a 3D scene rendering algorithm that enables realistic cross-scene object transfer (from a source to a target scene) based on the Gaussian Splatting framework. Our approach addresses two critical challenges: (1) precise 3D object extraction from the source scene, and (2) faithful relighting of the transferred object in the target scene without explicit material property estimation. TranSplat fits a splatting model to the source scene, using 2D object masks to drive fine-grained 3D segmentation. Following user-guided insertion of the object into the target scene, along with automatic refinement of position and orientation, TranSplat derives per-Gaussian radiance transfer functions via spherical harmonic analysis to adapt the object's appearance to match the target scene's lighting environment. This relighting strategy does not require explicitly estimating physical scene properties such as BRDFs. Evaluated on several synthetic and real-world scenes and objects, TranSplat yields excellent 3D object extractions and relighting performance compared to recent baseline methods and visually convincing cross-scene object transfers. We conclude by discussing the limitations of the approach.
What if Eye...? Computationally Recreating Vision Evolution
Jan 25, 2025



Vision systems in nature show remarkable diversity, from simple light-sensitive patches to complex camera eyes with lenses. While natural selection has produced these eyes through countless mutations over millions of years, they represent just one set of realized evolutionary paths. Testing hypotheses about how environmental pressures shaped eye evolution remains challenging since we cannot experimentally isolate individual factors. Computational evolution offers a way to systematically explore alternative trajectories. Here we show how environmental demands drive three fundamental aspects of visual evolution through an artificial evolution framework that co-evolves both physical eye structure and neural processing in embodied agents. First, we demonstrate computational evidence that task specific selection drives bifurcation in eye evolution - orientation tasks like navigation in a maze leads to distributed compound-type eyes while an object discrimination task leads to the emergence of high-acuity camera-type eyes. Second, we reveal how optical innovations like lenses naturally emerge to resolve fundamental tradeoffs between light collection and spatial precision. Third, we uncover systematic scaling laws between visual acuity and neural processing, showing how task complexity drives coordinated evolution of sensory and computational capabilities. Our work introduces a novel paradigm that illuminates evolutionary principles shaping vision by creating targeted single-player games where embodied agents must simultaneously evolve visual systems and learn complex behaviors. Through our unified genetic encoding framework, these embodied agents serve as next-generation hypothesis testing machines while providing a foundation for designing manufacturable bio-inspired vision systems.
Blurred LiDAR for Sharper 3D: Robust Handheld 3D Scanning with Diffuse LiDAR and RGB
Nov 29, 2024



3D surface reconstruction is essential across applications of virtual reality, robotics, and mobile scanning. However, RGB-based reconstruction often fails in low-texture, low-light, and low-albedo scenes. Handheld LiDARs, now common on mobile devices, aim to address these challenges by capturing depth information from time-of-flight measurements of a coarse grid of projected dots. Yet, these sparse LiDARs struggle with scene coverage on limited input views, leaving large gaps in depth information. In this work, we propose using an alternative class of "blurred" LiDAR that emits a diffuse flash, greatly improving scene coverage but introducing spatial ambiguity from mixed time-of-flight measurements across a wide field of view. To handle these ambiguities, we propose leveraging the complementary strengths of diffuse LiDAR with RGB. We introduce a Gaussian surfel-based rendering framework with a scene-adaptive loss function that dynamically balances RGB and diffuse LiDAR signals. We demonstrate that, surprisingly, diffuse LiDAR can outperform traditional sparse LiDAR, enabling robust 3D scanning with accurate color and geometry estimation in challenging environments.
Enhancing Autonomous Navigation by Imaging Hidden Objects using Single-Photon LiDAR
Oct 04, 2024



Robust autonomous navigation in environments with limited visibility remains a critical challenge in robotics. We present a novel approach that leverages Non-Line-of-Sight (NLOS) sensing using single-photon LiDAR to improve visibility and enhance autonomous navigation. Our method enables mobile robots to "see around corners" by utilizing multi-bounce light information, effectively expanding their perceptual range without additional infrastructure. We propose a three-module pipeline: (1) Sensing, which captures multi-bounce histograms using SPAD-based LiDAR; (2) Perception, which estimates occupancy maps of hidden regions from these histograms using a convolutional neural network; and (3) Control, which allows a robot to follow safe paths based on the estimated occupancy. We evaluate our approach through simulations and real-world experiments on a mobile robot navigating an L-shaped corridor with hidden obstacles. Our work represents the first experimental demonstration of NLOS imaging for autonomous navigation, paving the way for safer and more efficient robotic systems operating in complex environments. We also contribute a novel dynamics-integrated transient rendering framework for simulating NLOS scenarios, facilitating future research in this domain.
NeST: Neural Stress Tensor Tomography by leveraging 3D Photoelasticity
Jun 14, 2024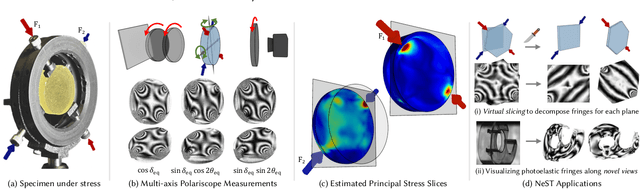

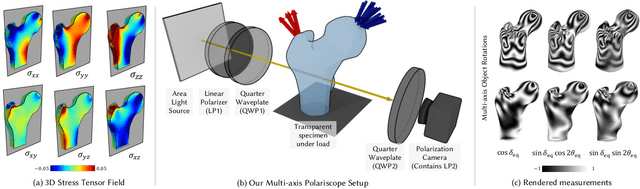
Photoelasticity enables full-field stress analysis in transparent objects through stress-induced birefringence. Existing techniques are limited to 2D slices and require destructively slicing the object. Recovering the internal 3D stress distribution of the entire object is challenging as it involves solving a tensor tomography problem and handling phase wrapping ambiguities. We introduce NeST, an analysis-by-synthesis approach for reconstructing 3D stress tensor fields as neural implicit representations from polarization measurements. Our key insight is to jointly handle phase unwrapping and tensor tomography using a differentiable forward model based on Jones calculus. Our non-linear model faithfully matches real captures, unlike prior linear approximations. We develop an experimental multi-axis polariscope setup to capture 3D photoelasticity and experimentally demonstrate that NeST reconstructs the internal stress distribution for objects with varying shape and force conditions. Additionally, we showcase novel applications in stress analysis, such as visualizing photoelastic fringes by virtually slicing the object and viewing photoelastic fringes from unseen viewpoints. NeST paves the way for scalable non-destructive 3D photoelastic analysis.
Event Cameras Meet SPADs for High-Speed, Low-Bandwidth Imaging
Apr 17, 2024



Traditional cameras face a trade-off between low-light performance and high-speed imaging: longer exposure times to capture sufficient light results in motion blur, whereas shorter exposures result in Poisson-corrupted noisy images. While burst photography techniques help mitigate this tradeoff, conventional cameras are fundamentally limited in their sensor noise characteristics. Event cameras and single-photon avalanche diode (SPAD) sensors have emerged as promising alternatives to conventional cameras due to their desirable properties. SPADs are capable of single-photon sensitivity with microsecond temporal resolution, and event cameras can measure brightness changes up to 1 MHz with low bandwidth requirements. We show that these properties are complementary, and can help achieve low-light, high-speed image reconstruction with low bandwidth requirements. We introduce a sensor fusion framework to combine SPADs with event cameras to improves the reconstruction of high-speed, low-light scenes while reducing the high bandwidth cost associated with using every SPAD frame. Our evaluation, on both synthetic and real sensor data, demonstrates significant enhancements ( > 5 dB PSNR) in reconstructing low-light scenes at high temporal resolution (100 kHz) compared to conventional cameras. Event-SPAD fusion shows great promise for real-world applications, such as robotics or medical imaging.
DecentNeRFs: Decentralized Neural Radiance Fields from Crowdsourced Images
Mar 28, 2024Neural radiance fields (NeRFs) show potential for transforming images captured worldwide into immersive 3D visual experiences. However, most of this captured visual data remains siloed in our camera rolls as these images contain personal details. Even if made public, the problem of learning 3D representations of billions of scenes captured daily in a centralized manner is computationally intractable. Our approach, DecentNeRF, is the first attempt at decentralized, crowd-sourced NeRFs that require $\sim 10^4\times$ less server computing for a scene than a centralized approach. Instead of sending the raw data, our approach requires users to send a 3D representation, distributing the high computation cost of training centralized NeRFs between the users. It learns photorealistic scene representations by decomposing users' 3D views into personal and global NeRFs and a novel optimally weighted aggregation of only the latter. We validate the advantage of our approach to learn NeRFs with photorealism and minimal server computation cost on structured synthetic and real-world photo tourism datasets. We further analyze how secure aggregation of global NeRFs in DecentNeRF minimizes the undesired reconstruction of personal content by the server.