 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFE-GAN: Efficient GAN-based Framework for Document Image Enhancement and Binarization with Multi-scale Feature Extraction
Dec 16, 2025



Document image enhancement and binarization are commonly performed prior to document analysis and recognition tasks for improving the efficiency and accuracy of optical character recognition (OCR) systems. This is because directly recognizing text in degraded documents, particularly in color images, often results in unsatisfactory recognition performance. To address these issues, existing methods train independent generative adversarial networks (GANs) for different color channels to remove shadows and noise, which, in turn, facilitates efficient text information extraction. However, deploying multiple GANs results in long training and inference times. To reduce both training and inference times of document image enhancement and binarization models, we propose MFE-GAN, an efficient GAN-based framework with multi-scale feature extraction (MFE), which incorporates Haar wavelet transformation (HWT) and normalization to process document images before feeding them into GANs for training. In addition, we present novel generators, discriminators, and loss functions to improve the model's performance, and we conduct ablation studies to demonstrate their effectiveness. Experimental results on the Benchmark, Nabuco, and CMATERdb datasets demonstrate that the proposed MFE-GAN significantly reduces the total training and inference times while maintaining comparable performance with respect to state-of-the-art (SOTA) methods. The implementation of this work is available at https://ruiyangju.github.io/MFE-GAN.
TranSplat: Lighting-Consistent Cross-Scene Object Transfer with 3D Gaussian Splatting
Mar 28, 2025We present TranSplat, a 3D scene rendering algorithm that enables realistic cross-scene object transfer (from a source to a target scene) based on the Gaussian Splatting framework. Our approach addresses two critical challenges: (1) precise 3D object extraction from the source scene, and (2) faithful relighting of the transferred object in the target scene without explicit material property estimation. TranSplat fits a splatting model to the source scene, using 2D object masks to drive fine-grained 3D segmentation. Following user-guided insertion of the object into the target scene, along with automatic refinement of position and orientation, TranSplat derives per-Gaussian radiance transfer functions via spherical harmonic analysis to adapt the object's appearance to match the target scene's lighting environment. This relighting strategy does not require explicitly estimating physical scene properties such as BRDFs. Evaluated on several synthetic and real-world scenes and objects, TranSplat yields excellent 3D object extractions and relighting performance compared to recent baseline methods and visually convincing cross-scene object transfers. We conclude by discussing the limitations of the approach.
ORB-SfMLearner: ORB-Guided Self-supervised Visual Odometry with Selective Online Adaptation
Sep 18, 2024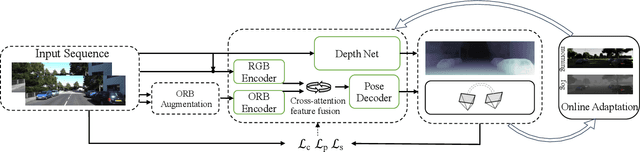


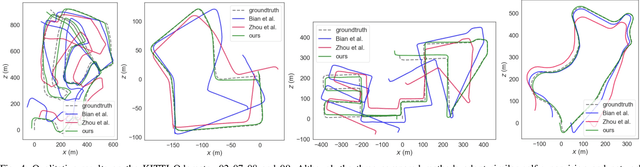
Deep visual odometry, despite extensive research, still faces limitations in accuracy and generalizability that prevent its broader application. To address these challenges, we propose an Oriented FAST and Rotated BRIEF (ORB)-guided visual odometry with selective online adaptation named ORB-SfMLearner. We present a novel use of ORB features for learning-based ego-motion estimation, leading to more robust and accurate results. We also introduce the cross-attention mechanism to enhance the explainability of PoseNet and have revealed that driving direction of the vehicle can be explained through attention weights, marking a novel exploration in this area. To improve generalizability, our selective online adaptation allows the network to rapidly and selectively adjust to the optimal parameters across different domains. Experimental results on KITTI and vKITTI datasets show that our method outperforms previous state-of-the-art deep visual odometry methods in terms of ego-motion accuracy and generalizability.
ToDER: Towards Colonoscopy Depth Estimation and Reconstruction with Geometry Constraint Adaptation
Jul 23, 2024



Visualizing colonoscopy is crucial for medical auxiliary diagnosis to prevent undetected polyps in areas that are not fully observed. Traditional feature-based and depth-based reconstruction approaches usually end up with undesirable results due to incorrect point matching or imprecise depth estimation in realistic colonoscopy videos. Modern deep-based methods often require a sufficient number of ground truth samples, which are generally hard to obtain in optical colonoscopy. To address this issue, self-supervised and domain adaptation methods have been explored. However, these methods neglect geometry constraints and exhibit lower accuracy in predicting detailed depth. We thus propose a novel reconstruction pipeline with a bi-directional adaptation architecture named ToDER to get precise depth estimations. Furthermore, we carefully design a TNet module in our adaptation architecture to yield geometry constraints and obtain better depth quality. Estimated depth is finally utilized to reconstruct a reliable colon model for visualization. Experimental results demonstrate that our approach can precisely predict depth maps in both realistic and synthetic colonoscopy videos compared with other self-supervised and domain adaptation methods. Our method on realistic colonoscopy also shows the great potential for visualizing unobserved regions and preventing misdiagnoses.