 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Effectiveness of Noise Pretraining for Implicit Neural Representations
Mar 30, 2026The approximation and convergence properties of implicit neural representations (INRs) are known to be highly sensitive to parameter initialization strategies. While several data-driven initialization methods demonstrate significant improvements over standard random sampling, the reasons for their success -- specifically, whether they encode classical statistical signal priors or more complex features -- remain poorly understood. In this study, we explore this phenomenon through a series of experimental analyses leveraging noise pretraining. We pretrain INRs on diverse noise classes (e.g., Gaussian, Dead Leaves, Spectral) and measure their ability to both fit unseen signals and encode priors for an inverse imaging task (denoising). Our analyses on image and video data reveal a surprising finding: simply pretraining on unstructured noise (Uniform, Gaussian) dramatically improves signal fitting capacity compared to all other baselines. However, unstructured noise also yields poor deep image priors for denoising. In contrast, we also find that noise with the classic $1/|f^α|$ spectral structure of natural images achieves an excellent balance of signal fitting and inverse imaging capabilities, performing on par with the best data-driven initialization methods. This finding enables more efficient INR training in applications lacking sufficient prior domain-specific data. For more details, visit project page at https://kushalvyas.github.io/noisepretraining.html
Efficient Conformal Volumetry for Template-Based Segmentation
Feb 28, 2026Template-based segmentation, a widely used paradigm in medical imaging, propagates anatomical labels via deformable registration from a labeled atlas to a target image, and is often used to compute volumetric biomarkers for downstream decision-making. While conformal prediction (CP) provides finite-sample valid intervals for scalar metrics, existing segmentation-based uncertainty quantification (UQ) approaches either rely on learned model features, often unavailable in classic template-based pipelines, or treat the registration process as a black box, resulting in overly conservative intervals when applied directly in output space. We introduce ConVOLT, a CP framework that achieves efficient volumetric UQ by conditioning calibration on properties of the estimated deformation field from template-based segmentation. ConVOLT calibrates a learned volumetric scaling factor from deformation space features. We evaluate ConVOLT on template-based segmentation tasks involving global, regional, and label volumetry across multiple datasets and registration methods. ConVOLT achieves target coverage while producing substantially tighter intervals than output-space conformal baselines. Our work paves way to exploit the registration process for efficient UQ in medical imaging pipelines.
Guidestar-Free Adaptive Optics with Asymmetric Apertures
Feb 02, 2026This work introduces the first closed-loop adaptive optics (AO) system capable of optically correcting aberrations in real-time without a guidestar or a wavefront sensor. Nearly 40 years ago, Cederquist et al. demonstrated that asymmetric apertures enable phase retrieval (PR) algorithms to perform fully computational wavefront sensing, albeit at a high computational cost. More recently, Chimitt et al. extended this approach with machine learning and demonstrated real-time wavefront sensing using only a single (guidestar-based) point-spread-function (PSF) measurement. Inspired by these works, we introduce a guidestar-free AO framework built around asymmetric apertures and machine learning. Our approach combines three key elements: (1) an asymmetric aperture placed in the optical path that enables PR-based wavefront sensing, (2) a pair of machine learning algorithms that estimate the PSF from natural scene measurements and reconstruct phase aberrations, and (3) a spatial light modulator that performs optical correction. We experimentally validate this framework on dense natural scenes imaged through unknown obscurants. Our method outperforms state-of-the-art guidestar-free wavefront shaping methods, using an order of magnitude fewer measurements and three orders of magnitude less computation.
Compressive Sensing Photoacoustic Imaging Receiver with Matrix-Vector-Multiplication SAR ADC
Nov 09, 2025Wearable photoacoustic imaging devices hold great promise for continuous health monitoring and point-of-care diagnostics. However, the large data volume generated by high-density transducer arrays presents a major challenge for realizing compact and power-efficient wearable systems. This paper presents a photoacoustic imaging receiver (RX) that embeds compressive sensing directly into the hardware to address this bottleneck. The RX integrates 16 AFEs and four matrix-vector-multiplication (MVM) SAR ADCs that perform energy- and area-efficient analog-domain compression. The architecture achieves a 4-8x reduction in output data rate while preserving low-loss full-array information. The MVM SAR ADC executes passive and accurate MVM using user-defined programmable ternary weights. Two signal reconstruction methods are implemented: (1) an optimization approach using the fast iterative shrinkage-thresholding algorithm, and (2) a learning-based approach employing implicit neural representation. Fabricated in 65 nm CMOS, the chip achieves an ADC's SNDR of 57.5 dB at 20.41 MS/s, with an AFE input-referred noise of 3.5 nV/sqrt(Hz). MVM linearity measurements show R^2 > 0.999 across a wide range of weights and input amplitudes. The system is validated through phantom imaging experiments, demonstrating high-fidelity image reconstruction under up to 8x compression. The RX consumes 5.83 mW/channel and supports a general ternary-weighted measurement matrix, offering a compelling solution for next-generation miniaturized, wearable PA imaging systems.
COMPASS: Robust Feature Conformal Prediction for Medical Segmentation Metrics
Sep 26, 2025In clinical applications, the utility of segmentation models is often based on the accuracy of derived downstream metrics such as organ size, rather than by the pixel-level accuracy of the segmentation masks themselves. Thus, uncertainty quantification for such metrics is crucial for decision-making. Conformal prediction (CP) is a popular framework to derive such principled uncertainty guarantees, but applying CP naively to the final scalar metric is inefficient because it treats the complex, non-linear segmentation-to-metric pipeline as a black box. We introduce COMPASS, a practical framework that generates efficient, metric-based CP intervals for image segmentation models by leveraging the inductive biases of their underlying deep neural networks. COMPASS performs calibration directly in the model's representation space by perturbing intermediate features along low-dimensional subspaces maximally sensitive to the target metric. We prove that COMPASS achieves valid marginal coverage under exchangeability and nestedness assumptions. Empirically, we demonstrate that COMPASS produces significantly tighter intervals than traditional CP baselines on four medical image segmentation tasks for area estimation of skin lesions and anatomical structures. Furthermore, we show that leveraging learned internal features to estimate importance weights allows COMPASS to also recover target coverage under covariate shifts. COMPASS paves the way for practical, metric-based uncertainty quantification for medical image segmentation.
Post-Hurricane Debris Segmentation Using Fine-Tuned Foundational Vision Models
Apr 19, 2025Timely and accurate detection of hurricane debris is critical for effective disaster response and community resilience. While post-disaster aerial imagery is readily available, robust debris segmentation solutions applicable across multiple disaster regions remain limited. Developing a generalized solution is challenging due to varying environmental and imaging conditions that alter debris' visual signatures across different regions, further compounded by the scarcity of training data. This study addresses these challenges by fine-tuning pre-trained foundational vision models, achieving robust performance with a relatively small, high-quality dataset. Specifically, this work introduces an open-source dataset comprising approximately 1,200 manually annotated aerial RGB images from Hurricanes Ian, Ida, and Ike. To mitigate human biases and enhance data quality, labels from multiple annotators are strategically aggregated and visual prompt engineering is employed. The resulting fine-tuned model, named fCLIPSeg, achieves a Dice score of 0.70 on data from Hurricane Ida -- a disaster event entirely excluded during training -- with virtually no false positives in debris-free areas. This work presents the first event-agnostic debris segmentation model requiring only standard RGB imagery during deployment, making it well-suited for rapid, large-scale post-disaster impact assessments and recovery planning.
TranSplat: Lighting-Consistent Cross-Scene Object Transfer with 3D Gaussian Splatting
Mar 28, 2025We present TranSplat, a 3D scene rendering algorithm that enables realistic cross-scene object transfer (from a source to a target scene) based on the Gaussian Splatting framework. Our approach addresses two critical challenges: (1) precise 3D object extraction from the source scene, and (2) faithful relighting of the transferred object in the target scene without explicit material property estimation. TranSplat fits a splatting model to the source scene, using 2D object masks to drive fine-grained 3D segmentation. Following user-guided insertion of the object into the target scene, along with automatic refinement of position and orientation, TranSplat derives per-Gaussian radiance transfer functions via spherical harmonic analysis to adapt the object's appearance to match the target scene's lighting environment. This relighting strategy does not require explicitly estimating physical scene properties such as BRDFs. Evaluated on several synthetic and real-world scenes and objects, TranSplat yields excellent 3D object extractions and relighting performance compared to recent baseline methods and visually convincing cross-scene object transfers. We conclude by discussing the limitations of the approach.
When are Diffusion Priors Helpful in Sparse Reconstruction? A Study with Sparse-view CT
Feb 04, 2025Diffusion models demonstrate state-of-the-art performance on image generation, and are gaining traction for sparse medical image reconstruction tasks. However, compared to classical reconstruction algorithms relying on simple analytical priors, diffusion models have the dangerous property of producing realistic looking results \emph{even when incorrect}, particularly with few observations. We investigate the utility of diffusion models as priors for image reconstruction by varying the number of observations and comparing their performance to classical priors (sparse and Tikhonov regularization) using pixel-based, structural, and downstream metrics. We make comparisons on low-dose chest wall computed tomography (CT) for fat mass quantification. First, we find that classical priors are superior to diffusion priors when the number of projections is ``sufficient''. Second, we find that diffusion priors can capture a large amount of detail with very few observations, significantly outperforming classical priors. However, they fall short of capturing all details, even with many observations. Finally, we find that the performance of diffusion priors plateau after extremely few ($\approx$10-15) projections. Ultimately, our work highlights potential issues with diffusion-based sparse reconstruction and underscores the importance of further investigation, particularly in high-stakes clinical settings.
Video-based Surgical Tool-tip and Keypoint Tracking using Multi-frame Context-driven Deep Learning Models
Jan 30, 2025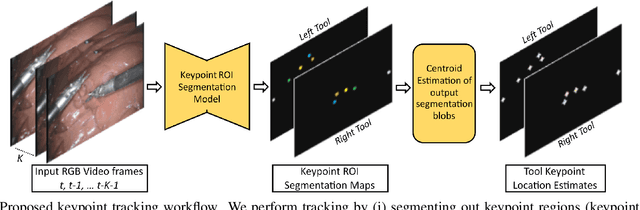

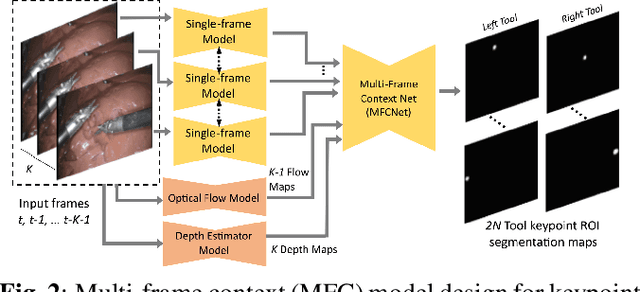
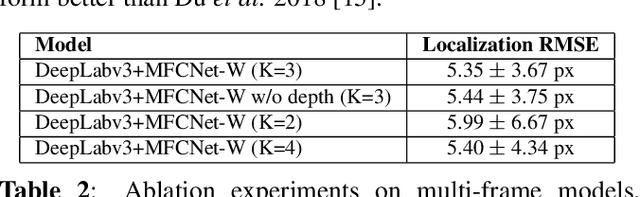
Automated tracking of surgical tool keypoints in robotic surgery videos is an essential task for various downstream use cases such as skill assessment, expertise assessment, and the delineation of safety zones. In recent years, the explosion of deep learning for vision applications has led to many works in surgical instrument segmentation, while lesser focus has been on tracking specific tool keypoints, such as tool tips. In this work, we propose a novel, multi-frame context-driven deep learning framework to localize and track tool keypoints in surgical videos. We train and test our models on the annotated frames from the 2015 EndoVis Challenge dataset, resulting in state-of-the-art performance. By leveraging sophisticated deep learning models and multi-frame context, we achieve 90\% keypoint detection accuracy and a localization RMS error of 5.27 pixels. Results on a self-annotated JIGSAWS dataset with more challenging scenarios also show that the proposed multi-frame models can accurately track tool-tip and tool-base keypoints, with ${<}4.2$-pixel RMS error overall. Such a framework paves the way for accurately tracking surgical instrument keypoints, enabling further downstream use cases. Project and dataset webpage: https://tinyurl.com/mfc-tracker
Regression Conformal Prediction under Bias
Oct 07, 2024



Uncertainty quantification is crucial to account for the imperfect predictions of machine learning algorithms for high-impact applications. Conformal prediction (CP) is a powerful framework for uncertainty quantification that generates calibrated prediction intervals with valid coverage. In this work, we study how CP intervals are affected by bias - the systematic deviation of a prediction from ground truth values - a phenomenon prevalent in many real-world applications. We investigate the influence of bias on interval lengths of two different types of adjustments -- symmetric adjustments, the conventional method where both sides of the interval are adjusted equally, and asymmetric adjustments, a more flexible method where the interval can be adjusted unequally in positive or negative directions. We present theoretical and empirical analyses characterizing how symmetric and asymmetric adjustments impact the "tightness" of CP intervals for regression tasks. Specifically for absolute residual and quantile-based non-conformity scores, we prove: 1) the upper bound of symmetrically adjusted interval lengths increases by $2|b|$ where $b$ is a globally applied scalar value representing bias, 2) asymmetrically adjusted interval lengths are not affected by bias, and 3) conditions when asymmetrically adjusted interval lengths are guaranteed to be smaller than symmetric ones. Our analyses suggest that even if predictions exhibit significant drift from ground truth values, asymmetrically adjusted intervals are still able to maintain the same tightness and validity of intervals as if the drift had never happened, while symmetric ones significantly inflate the lengths. We demonstrate our theoretical results with two real-world prediction tasks: sparse-view computed tomography (CT) reconstruction and time-series weather forecasting. Our work paves the way for more bias-robust machine learning systems.