 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Conformal Volumetry for Template-Based Segmentation
Feb 28, 2026Template-based segmentation, a widely used paradigm in medical imaging, propagates anatomical labels via deformable registration from a labeled atlas to a target image, and is often used to compute volumetric biomarkers for downstream decision-making. While conformal prediction (CP) provides finite-sample valid intervals for scalar metrics, existing segmentation-based uncertainty quantification (UQ) approaches either rely on learned model features, often unavailable in classic template-based pipelines, or treat the registration process as a black box, resulting in overly conservative intervals when applied directly in output space. We introduce ConVOLT, a CP framework that achieves efficient volumetric UQ by conditioning calibration on properties of the estimated deformation field from template-based segmentation. ConVOLT calibrates a learned volumetric scaling factor from deformation space features. We evaluate ConVOLT on template-based segmentation tasks involving global, regional, and label volumetry across multiple datasets and registration methods. ConVOLT achieves target coverage while producing substantially tighter intervals than output-space conformal baselines. Our work paves way to exploit the registration process for efficient UQ in medical imaging pipelines.
COMPASS: Robust Feature Conformal Prediction for Medical Segmentation Metrics
Sep 26, 2025In clinical applications, the utility of segmentation models is often based on the accuracy of derived downstream metrics such as organ size, rather than by the pixel-level accuracy of the segmentation masks themselves. Thus, uncertainty quantification for such metrics is crucial for decision-making. Conformal prediction (CP) is a popular framework to derive such principled uncertainty guarantees, but applying CP naively to the final scalar metric is inefficient because it treats the complex, non-linear segmentation-to-metric pipeline as a black box. We introduce COMPASS, a practical framework that generates efficient, metric-based CP intervals for image segmentation models by leveraging the inductive biases of their underlying deep neural networks. COMPASS performs calibration directly in the model's representation space by perturbing intermediate features along low-dimensional subspaces maximally sensitive to the target metric. We prove that COMPASS achieves valid marginal coverage under exchangeability and nestedness assumptions. Empirically, we demonstrate that COMPASS produces significantly tighter intervals than traditional CP baselines on four medical image segmentation tasks for area estimation of skin lesions and anatomical structures. Furthermore, we show that leveraging learned internal features to estimate importance weights allows COMPASS to also recover target coverage under covariate shifts. COMPASS paves the way for practical, metric-based uncertainty quantification for medical image segmentation.
When are Diffusion Priors Helpful in Sparse Reconstruction? A Study with Sparse-view CT
Feb 04, 2025Diffusion models demonstrate state-of-the-art performance on image generation, and are gaining traction for sparse medical image reconstruction tasks. However, compared to classical reconstruction algorithms relying on simple analytical priors, diffusion models have the dangerous property of producing realistic looking results \emph{even when incorrect}, particularly with few observations. We investigate the utility of diffusion models as priors for image reconstruction by varying the number of observations and comparing their performance to classical priors (sparse and Tikhonov regularization) using pixel-based, structural, and downstream metrics. We make comparisons on low-dose chest wall computed tomography (CT) for fat mass quantification. First, we find that classical priors are superior to diffusion priors when the number of projections is ``sufficient''. Second, we find that diffusion priors can capture a large amount of detail with very few observations, significantly outperforming classical priors. However, they fall short of capturing all details, even with many observations. Finally, we find that the performance of diffusion priors plateau after extremely few ($\approx$10-15) projections. Ultimately, our work highlights potential issues with diffusion-based sparse reconstruction and underscores the importance of further investigation, particularly in high-stakes clinical settings.
Regression Conformal Prediction under Bias
Oct 07, 2024



Uncertainty quantification is crucial to account for the imperfect predictions of machine learning algorithms for high-impact applications. Conformal prediction (CP) is a powerful framework for uncertainty quantification that generates calibrated prediction intervals with valid coverage. In this work, we study how CP intervals are affected by bias - the systematic deviation of a prediction from ground truth values - a phenomenon prevalent in many real-world applications. We investigate the influence of bias on interval lengths of two different types of adjustments -- symmetric adjustments, the conventional method where both sides of the interval are adjusted equally, and asymmetric adjustments, a more flexible method where the interval can be adjusted unequally in positive or negative directions. We present theoretical and empirical analyses characterizing how symmetric and asymmetric adjustments impact the "tightness" of CP intervals for regression tasks. Specifically for absolute residual and quantile-based non-conformity scores, we prove: 1) the upper bound of symmetrically adjusted interval lengths increases by $2|b|$ where $b$ is a globally applied scalar value representing bias, 2) asymmetrically adjusted interval lengths are not affected by bias, and 3) conditions when asymmetrically adjusted interval lengths are guaranteed to be smaller than symmetric ones. Our analyses suggest that even if predictions exhibit significant drift from ground truth values, asymmetrically adjusted intervals are still able to maintain the same tightness and validity of intervals as if the drift had never happened, while symmetric ones significantly inflate the lengths. We demonstrate our theoretical results with two real-world prediction tasks: sparse-view computed tomography (CT) reconstruction and time-series weather forecasting. Our work paves the way for more bias-robust machine learning systems.
Wearing a MASK: Compressed Representations of Variable-Length Sequences Using Recurrent Neural Tangent Kernels
Oct 27, 2020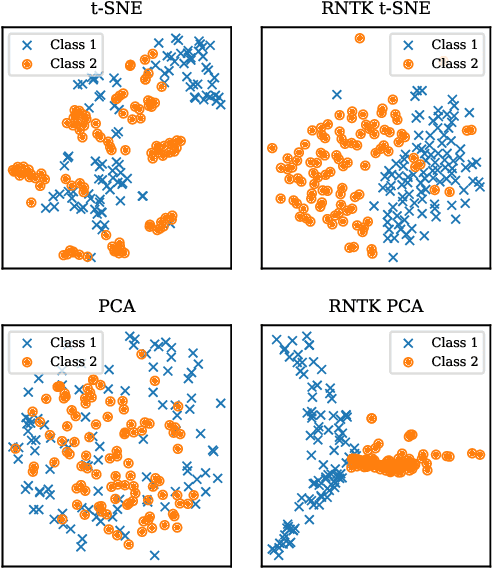
High dimensionality poses many challenges to the use of data, from visualization and interpretation, to prediction and storage for historical preservation. Techniques abound to reduce the dimensionality of fixed-length sequences, yet these methods rarely generalize to variable-length sequences. To address this gap, we extend existing methods that rely on the use of kernels to variable-length sequences via use of the Recurrent Neural Tangent Kernel (RNTK). Since a deep neural network with ReLu activation is a Max-Affine Spline Operator (MASO), we dub our approach Max-Affine Spline Kernel (MASK). We demonstrate how MASK can be used to extend principal components analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE) and apply these new algorithms to separate synthetic time series data sampled from second-order differential equations.