 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen are Diffusion Priors Helpful in Sparse Reconstruction? A Study with Sparse-view CT
Feb 04, 2025Diffusion models demonstrate state-of-the-art performance on image generation, and are gaining traction for sparse medical image reconstruction tasks. However, compared to classical reconstruction algorithms relying on simple analytical priors, diffusion models have the dangerous property of producing realistic looking results \emph{even when incorrect}, particularly with few observations. We investigate the utility of diffusion models as priors for image reconstruction by varying the number of observations and comparing their performance to classical priors (sparse and Tikhonov regularization) using pixel-based, structural, and downstream metrics. We make comparisons on low-dose chest wall computed tomography (CT) for fat mass quantification. First, we find that classical priors are superior to diffusion priors when the number of projections is ``sufficient''. Second, we find that diffusion priors can capture a large amount of detail with very few observations, significantly outperforming classical priors. However, they fall short of capturing all details, even with many observations. Finally, we find that the performance of diffusion priors plateau after extremely few ($\approx$10-15) projections. Ultimately, our work highlights potential issues with diffusion-based sparse reconstruction and underscores the importance of further investigation, particularly in high-stakes clinical settings.
Regression Conformal Prediction under Bias
Oct 07, 2024



Uncertainty quantification is crucial to account for the imperfect predictions of machine learning algorithms for high-impact applications. Conformal prediction (CP) is a powerful framework for uncertainty quantification that generates calibrated prediction intervals with valid coverage. In this work, we study how CP intervals are affected by bias - the systematic deviation of a prediction from ground truth values - a phenomenon prevalent in many real-world applications. We investigate the influence of bias on interval lengths of two different types of adjustments -- symmetric adjustments, the conventional method where both sides of the interval are adjusted equally, and asymmetric adjustments, a more flexible method where the interval can be adjusted unequally in positive or negative directions. We present theoretical and empirical analyses characterizing how symmetric and asymmetric adjustments impact the "tightness" of CP intervals for regression tasks. Specifically for absolute residual and quantile-based non-conformity scores, we prove: 1) the upper bound of symmetrically adjusted interval lengths increases by $2|b|$ where $b$ is a globally applied scalar value representing bias, 2) asymmetrically adjusted interval lengths are not affected by bias, and 3) conditions when asymmetrically adjusted interval lengths are guaranteed to be smaller than symmetric ones. Our analyses suggest that even if predictions exhibit significant drift from ground truth values, asymmetrically adjusted intervals are still able to maintain the same tightness and validity of intervals as if the drift had never happened, while symmetric ones significantly inflate the lengths. We demonstrate our theoretical results with two real-world prediction tasks: sparse-view computed tomography (CT) reconstruction and time-series weather forecasting. Our work paves the way for more bias-robust machine learning systems.
Dimensionality Reduction and Nearest Neighbors for Improving Out-of-Distribution Detection in Medical Image Segmentation
Aug 05, 2024
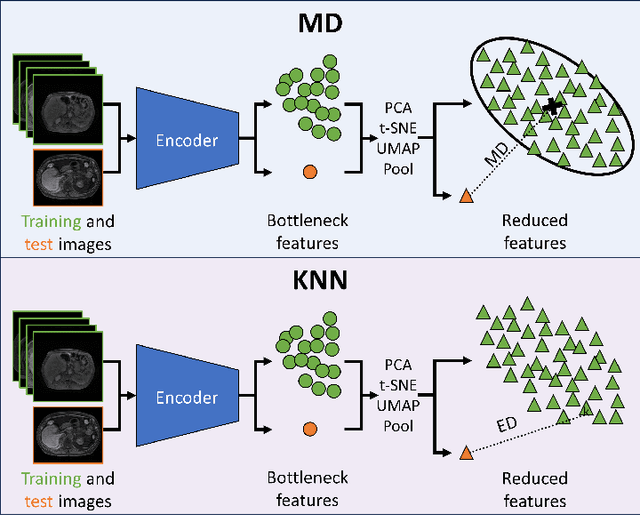

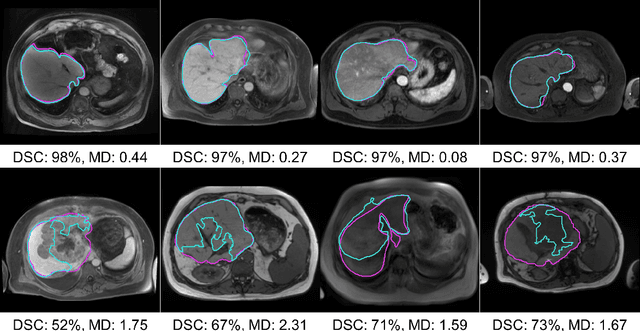
Clinically deployed deep learning-based segmentation models are known to fail on data outside of their training distributions. While clinicians review the segmentations, these models tend to perform well in most instances, which could exacerbate automation bias. Therefore, detecting out-of-distribution images at inference is critical to warn the clinicians that the model likely failed. This work applied the Mahalanobis distance (MD) post hoc to the bottleneck features of four Swin UNETR and nnU-net models that segmented the liver on T1-weighted magnetic resonance imaging and computed tomography. By reducing the dimensions of the bottleneck features with either principal component analysis or uniform manifold approximation and projection, images the models failed on were detected with high performance and minimal computational load. In addition, this work explored a non-parametric alternative to the MD, a k-th nearest neighbors distance (KNN). KNN drastically improved scalability and performance over MD when both were applied to raw and average-pooled bottleneck features.
Dimensionality Reduction for Improving Out-of-Distribution Detection in Medical Image Segmentation
Aug 07, 2023Clinically deployed segmentation models are known to fail on data outside of their training distribution. As these models perform well on most cases, it is imperative to detect out-of-distribution (OOD) images at inference to protect against automation bias. This work applies the Mahalanobis distance post hoc to the bottleneck features of a Swin UNETR model that segments the liver on T1-weighted magnetic resonance imaging. By reducing the dimensions of the bottleneck features with principal component analysis, OOD images were detected with high performance and minimal computational load.