 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance of Feature Extraction in the Calculation of Fréchet Distance for Medical Imaging
Nov 22, 2023Fr\'echet Inception Distance is a widely used metric for evaluating synthetic image quality that utilizes an ImageNet-trained InceptionV3 network as a feature extractor. However, its application in medical imaging lacks a standard feature extractor, leading to biased and inconsistent comparisons. This study aimed to compare state-of-the-art feature extractors for computing Fr\'echet Distances (FDs) in medical imaging. A StyleGAN2 network was trained with data augmentation techniques tailored for limited data domains on datasets comprising three medical imaging modalities and four anatomical locations. Human evaluation of generative quality (via a visual Turing test) was compared to FDs calculated using ImageNet-trained InceptionV3, ResNet50, SwAV, DINO, and Swin Transformer architectures, in addition to an InceptionV3 network trained on a large medical dataset, RadImageNet. All ImageNet-based extractors were consistent with each other, but only SwAV was significantly correlated with medical expert judgment. The RadImageNet-based FD showed volatility and lacked correlation with human judgment. Caution is advised when using medical image-trained extraction networks in the FD calculation. These networks should be rigorously evaluated on the imaging modality under consideration and publicly released. ImageNet-based extractors, while imperfect, are consistent and widely understood. Training extraction networks with SwAV is a promising approach for synthetic medical image evaluation.
Dimensionality Reduction for Improving Out-of-Distribution Detection in Medical Image Segmentation
Aug 07, 2023Clinically deployed segmentation models are known to fail on data outside of their training distribution. As these models perform well on most cases, it is imperative to detect out-of-distribution (OOD) images at inference to protect against automation bias. This work applies the Mahalanobis distance post hoc to the bottleneck features of a Swin UNETR model that segments the liver on T1-weighted magnetic resonance imaging. By reducing the dimensions of the bottleneck features with principal component analysis, OOD images were detected with high performance and minimal computational load.
A Quantitative Approach to Predicting Representational Learning and Performance in Neural Networks
Jul 14, 2023A key property of neural networks (both biological and artificial) is how they learn to represent and manipulate input information in order to solve a task. Different types of representations may be suited to different types of tasks, making identifying and understanding learned representations a critical part of understanding and designing useful networks. In this paper, we introduce a new pseudo-kernel based tool for analyzing and predicting learned representations, based only on the initial conditions of the network and the training curriculum. We validate the method on a simple test case, before demonstrating its use on a question about the effects of representational learning on sequential single versus concurrent multitask performance. We show that our method can be used to predict the effects of the scale of weight initialization and training curriculum on representational learning and downstream concurrent multitasking performance.
StyleGAN2-based Out-of-Distribution Detection for Medical Imaging
Jul 10, 2023
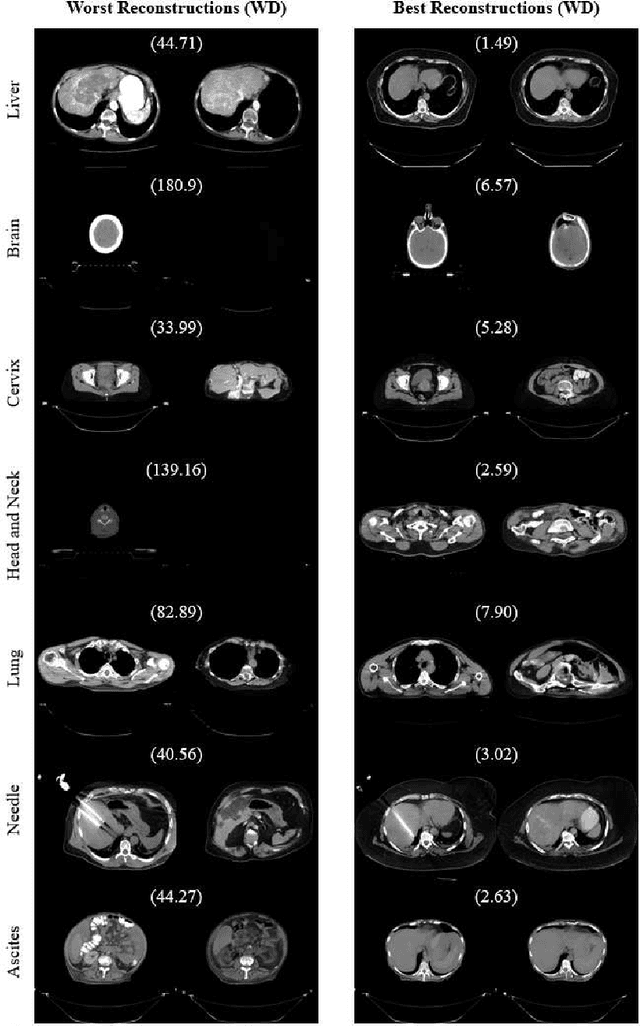
One barrier to the clinical deployment of deep learning-based models is the presence of images at runtime that lie far outside the training distribution of a given model. We aim to detect these out-of-distribution (OOD) images with a generative adversarial network (GAN). Our training dataset was comprised of 3,234 liver-containing computed tomography (CT) scans from 456 patients. Our OOD test data consisted of CT images of the brain, head and neck, lung, cervix, and abnormal livers. A StyleGAN2-ADA architecture was employed to model the training distribution. Images were reconstructed using backpropagation. Reconstructions were evaluated using the Wasserstein distance, mean squared error, and the structural similarity index measure. OOD detection was evaluated with the area under the receiver operating characteristic curve (AUROC). Our paradigm distinguished between liver and non-liver CT with greater than 90% AUROC. It was also completely unable to reconstruct liver artifacts, such as needles and ascites.
* Extended abstract published in the "Medical Imaging Meets NeurIPS" workshop at NeurIPS 2022. Original abstract can be found at http://www.cse.cuhk.edu.hk/~qdou/public/medneurips2022/125.pdf
Towards causally linking architectural parametrizations to algorithmic bias in neural networks
Feb 07, 2023



Training dataset biases are by far the most scrutinized factors when explaining algorithmic biases of neural networks. In contrast, hyperparameters related to the neural network architecture, e.g., the number of layers or choice of activation functions, have largely been ignored even though different network parameterizations are known to induce different implicit biases over learned features. For example, convolutional kernel size has been shown to bias CNNs towards different frequencies. In order to study the effect of these hyperparameters, we designed a causal framework for linking an architectural hyperparameter to algorithmic bias. Our framework is experimental, in that several versions of a network are trained with an intervention to a specific hyperparameter, and the resulting causal effect of this choice on performance bias is measured. We focused on the causal relationship between sensitivity to high-frequency image details and face analysis classification performance across different subpopulations (race/gender). In this work, we show that modifying a CNN hyperparameter (convolutional kernel size), even in one layer of a CNN, will not only change a fundamental characteristic of the learned features (frequency content) but that this change can vary significantly across data subgroups (race/gender populations) leading to biased generalization performance even in the presence of a balanced dataset.
Evaluating the Performance of StyleGAN2-ADA on Medical Images
Oct 07, 2022Although generative adversarial networks (GANs) have shown promise in medical imaging, they have four main limitations that impeded their utility: computational cost, data requirements, reliable evaluation measures, and training complexity. Our work investigates each of these obstacles in a novel application of StyleGAN2-ADA to high-resolution medical imaging datasets. Our dataset is comprised of liver-containing axial slices from non-contrast and contrast-enhanced computed tomography (CT) scans. Additionally, we utilized four public datasets composed of various imaging modalities. We trained a StyleGAN2 network with transfer learning (from the Flickr-Faces-HQ dataset) and data augmentation (horizontal flipping and adaptive discriminator augmentation). The network's generative quality was measured quantitatively with the Fr\'echet Inception Distance (FID) and qualitatively with a visual Turing test given to seven radiologists and radiation oncologists. The StyleGAN2-ADA network achieved a FID of 5.22 ($\pm$ 0.17) on our liver CT dataset. It also set new record FIDs of 10.78, 3.52, 21.17, and 5.39 on the publicly available SLIVER07, ChestX-ray14, ACDC, and Medical Segmentation Decathlon (brain tumors) datasets. In the visual Turing test, the clinicians rated generated images as real 42% of the time, approaching random guessing. Our computational ablation study revealed that transfer learning and data augmentation stabilize training and improve the perceptual quality of the generated images. We observed the FID to be consistent with human perceptual evaluation of medical images. Finally, our work found that StyleGAN2-ADA consistently produces high-quality results without hyperparameter searches or retraining.
* This preprint has not undergone post-submission improvements or corrections. The Version of Record of this contribution is published in LNCS, volume 13570, and is available online at https://doi.org/10.1007/978-3-031-16980-9_14
Dyadic Interaction Assessment from Free-living Audio for Depression Severity Assessment
Sep 08, 2022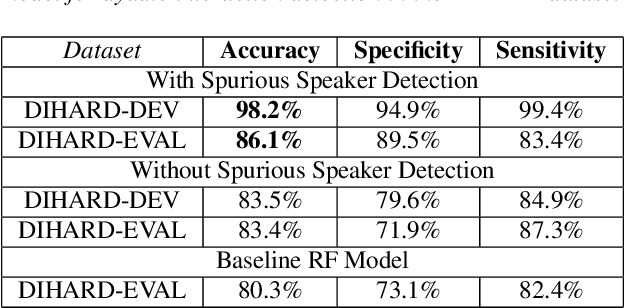
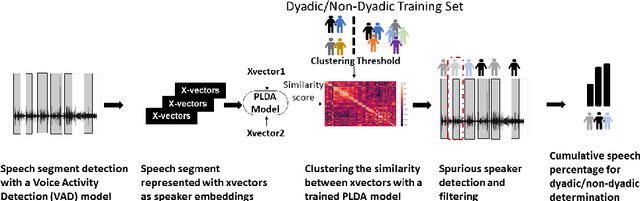
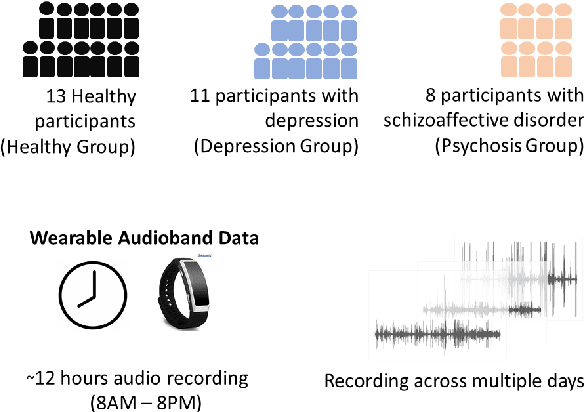
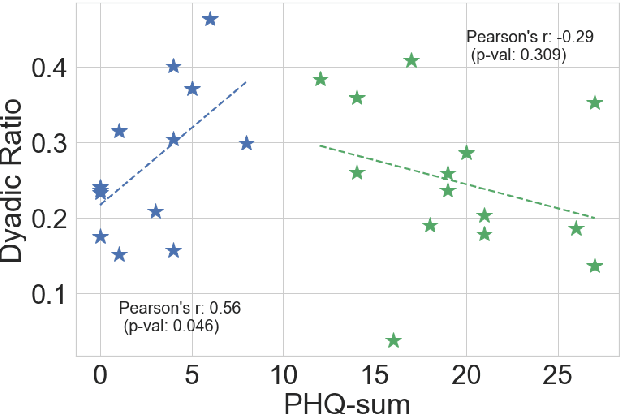
Psychomotor retardation in depression has been associated with speech timing changes from dyadic clinical interviews. In this work, we investigate speech timing features from free-living dyadic interactions. Apart from the possibility of continuous monitoring to complement clinical visits, a study in free-living conditions would also allow inferring sociability features such as dyadic interaction frequency implicated in depression. We adapted a speaker count estimator as a dyadic interaction detector with a specificity of 89.5% and a sensitivity of 86.1% in the DIHARD dataset. Using the detector, we obtained speech timing features from the detected dyadic interactions in multi-day audio recordings of 32 participants comprised of 13 healthy individuals, 11 individuals with depression, and 8 individuals with psychotic disorders. The dyadic interaction frequency increased with depression severity in participants with no or mild depression, indicating a potential diagnostic marker of depression onset. However, the dyadic interaction frequency decreased with increasing depression severity for participants with moderate or severe depression. In terms of speech timing features, the response time had a significant positive correlation with depression severity. Our work shows the potential of dyadic interaction analysis from audio recordings of free-living to obtain markers of depression severity.
Understanding robustness and generalization of artificial neural networks through Fourier masks
Mar 16, 2022

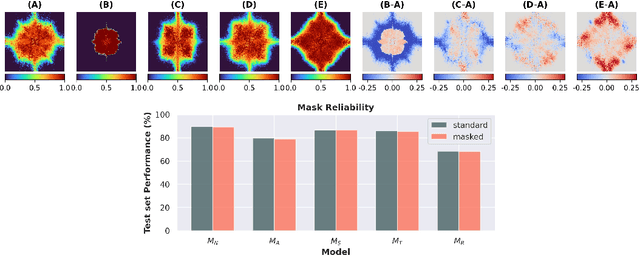
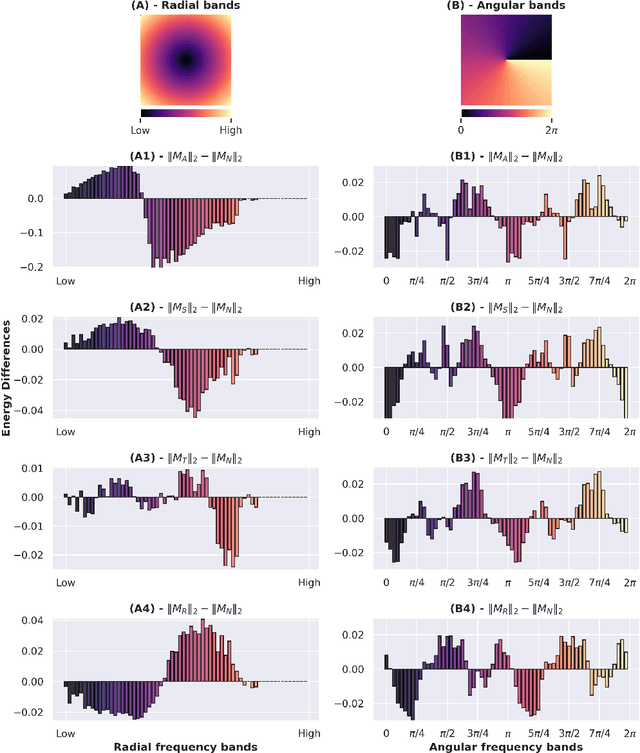
Despite the enormous success of artificial neural networks (ANNs) in many disciplines, the characterization of their computations and the origin of key properties such as generalization and robustness remain open questions. Recent literature suggests that robust networks with good generalization properties tend to be biased towards processing low frequencies in images. To explore the frequency bias hypothesis further, we develop an algorithm that allows us to learn modulatory masks highlighting the essential input frequencies needed for preserving a trained network's performance. We achieve this by imposing invariance in the loss with respect to such modulations in the input frequencies. We first use our method to test the low-frequency preference hypothesis of adversarially trained or data-augmented networks. Our results suggest that adversarially robust networks indeed exhibit a low-frequency bias but we find this bias is also dependent on directions in frequency space. However, this is not necessarily true for other types of data augmentation. Our results also indicate that the essential frequencies in question are effectively the ones used to achieve generalization in the first place. Surprisingly, images seen through these modulatory masks are not recognizable and resemble texture-like patterns.
Bongard-LOGO: A New Benchmark for Human-Level Concept Learning and Reasoning
Oct 02, 2020
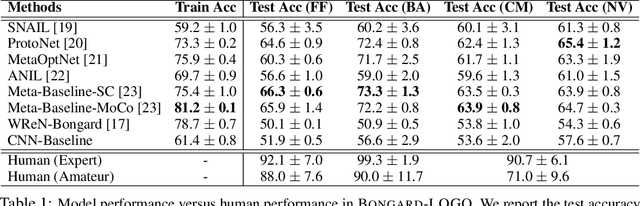
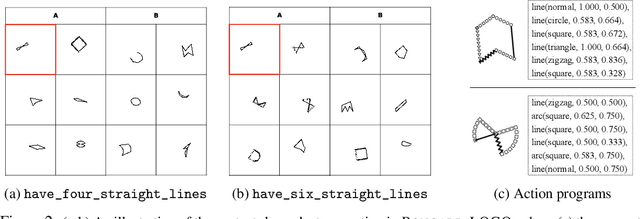
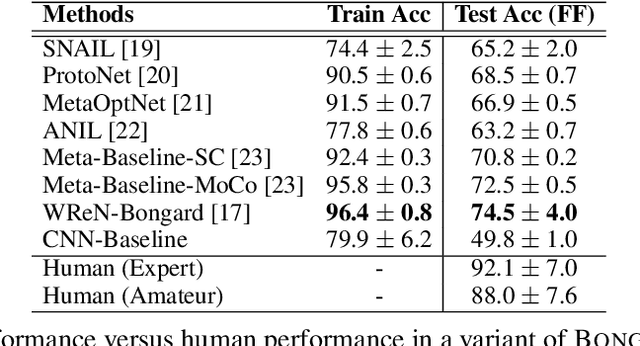
Humans have an inherent ability to learn novel concepts from only a few samples and generalize these concepts to different situations. Even though today's machine learning models excel with a plethora of training data on standard recognition tasks, a considerable gap exists between machine-level pattern recognition and human-level concept learning. To narrow this gap, the Bongard Problems (BPs) were introduced as an inspirational challenge for visual cognition in intelligent systems. Albeit new advances in representation learning and learning to learn, BPs remain a daunting challenge for modern AI. Inspired by the original one hundred BPs, we propose a new benchmark Bongard-LOGO for human-level concept learning and reasoning. We develop a program-guided generation technique to produce a large set of human-interpretable visual cognition problems in action-oriented LOGO language. Our benchmark captures three core properties of human cognition: 1) context-dependent perception, in which the same object may have disparate interpretations given different contexts; 2) analogy-making perception, in which some meaningful concepts are traded off for other meaningful concepts; and 3) perception with a few samples but infinite vocabulary. In experiments, we show that the state-of-the-art deep learning methods perform substantially worse than human subjects, implying that they fail to capture core human cognition properties. Finally, we discuss research directions towards a general architecture for visual reasoning to tackle this benchmark.
An Improved Semi-Supervised VAE for Learning Disentangled Representations
Jun 22, 2020



Learning interpretable and disentangled representations is a crucial yet challenging task in representation learning. In this work, we focus on semi-supervised disentanglement learning and extend work by Locatello et al. (2019) by introducing another source of supervision that we denote as label replacement. Specifically, during training, we replace the inferred representation associated with a data point with its ground-truth representation whenever it is available. Our extension is theoretically inspired by our proposed general framework of semi-supervised disentanglement learning in the context of VAEs which naturally motivates the supervised terms commonly used in existing semi-supervised VAEs (but not for disentanglement learning). Extensive experiments on synthetic and real datasets demonstrate both quantitatively and qualitatively the ability of our extension to significantly and consistently improve disentanglement with very limited supervision.