 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplay Can Provably Increase Forgetting
Jun 04, 2025Continual learning seeks to enable machine learning systems to solve an increasing corpus of tasks sequentially. A critical challenge for continual learning is forgetting, where the performance on previously learned tasks decreases as new tasks are introduced. One of the commonly used techniques to mitigate forgetting, sample replay, has been shown empirically to reduce forgetting by retaining some examples from old tasks and including them in new training episodes. In this work, we provide a theoretical analysis of sample replay in an over-parameterized continual linear regression setting, where each task is given by a linear subspace and with enough replay samples, one would be able to eliminate forgetting. Our analysis focuses on sample replay and highlights the role of the replayed samples and the relationship between task subspaces. Surprisingly, we find that, even in a noiseless setting, forgetting can be non-monotonic with respect to the number of replay samples. We present tasks where replay can be harmful with respect to worst-case settings, and also in distributional settings where replay of randomly selected samples increases forgetting in expectation. We also give empirical evidence that harmful replay is not limited to training with linear models by showing similar behavior for a neural networks equipped with SGD. Through experiments on a commonly used benchmark, we provide additional evidence that, even in seemingly benign scenarios, performance of the replay heavily depends on the choice of replay samples and the relationship between tasks.
Generalization properties of contrastive world models
Dec 29, 2023

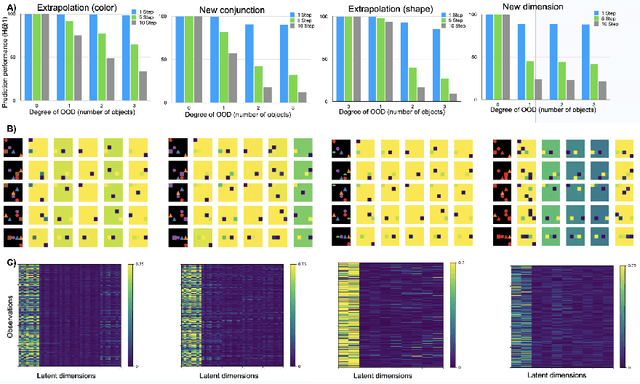

Recent work on object-centric world models aim to factorize representations in terms of objects in a completely unsupervised or self-supervised manner. Such world models are hypothesized to be a key component to address the generalization problem. While self-supervision has shown improved performance however, OOD generalization has not been systematically and explicitly tested. In this paper, we conduct an extensive study on the generalization properties of contrastive world model. We systematically test the model under a number of different OOD generalization scenarios such as extrapolation to new object attributes, introducing new conjunctions or new attributes. Our experiments show that the contrastive world model fails to generalize under the different OOD tests and the drop in performance depends on the extent to which the samples are OOD. When visualizing the transition updates and convolutional feature maps, we observe that any changes in object attributes (such as previously unseen colors, shapes, or conjunctions of color and shape) breaks down the factorization of object representations. Overall, our work highlights the importance of object-centric representations for generalization and current models are limited in their capacity to learn such representations required for human-level generalization.
Continual Learning: Applications and the Road Forward
Nov 21, 2023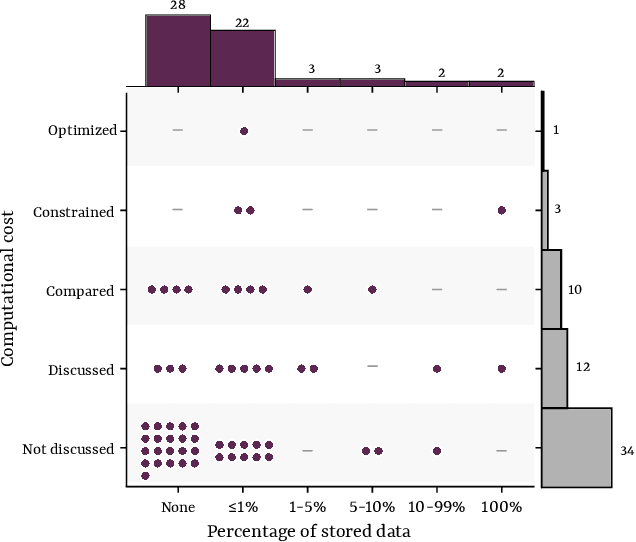
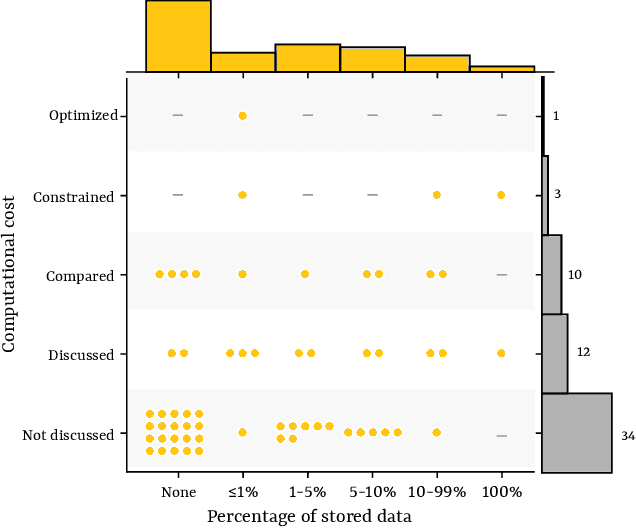
Continual learning is a sub-field of machine learning, which aims to allow machine learning models to continuously learn on new data, by accumulating knowledge without forgetting what was learned in the past. In this work, we take a step back, and ask: "Why should one care about continual learning in the first place?". We set the stage by surveying recent continual learning papers published at three major machine learning conferences, and show that memory-constrained settings dominate the field. Then, we discuss five open problems in machine learning, and even though they seem unrelated to continual learning at first sight, we show that continual learning will inevitably be part of their solution. These problems are model-editing, personalization, on-device learning, faster (re-)training and reinforcement learning. Finally, by comparing the desiderata from these unsolved problems and the current assumptions in continual learning, we highlight and discuss four future directions for continual learning research. We hope that this work offers an interesting perspective on the future of continual learning, while displaying its potential value and the paths we have to pursue in order to make it successful. This work is the result of the many discussions the authors had at the Dagstuhl seminar on Deep Continual Learning, in March 2023.
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Oct 15, 2022Neuroscience has long been an important driver of progress in artificial intelligence (AI). We propose that to accelerate progress in AI, we must invest in fundamental research in NeuroAI.
The Sensorium competition on predicting large-scale mouse primary visual cortex activity
Jun 17, 2022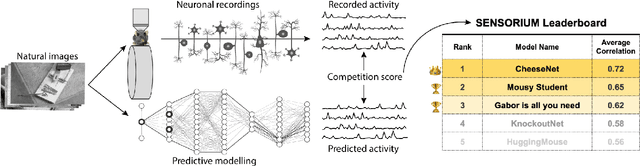
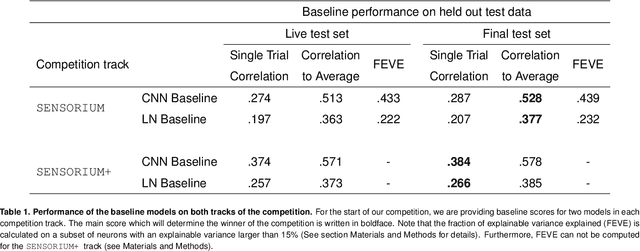
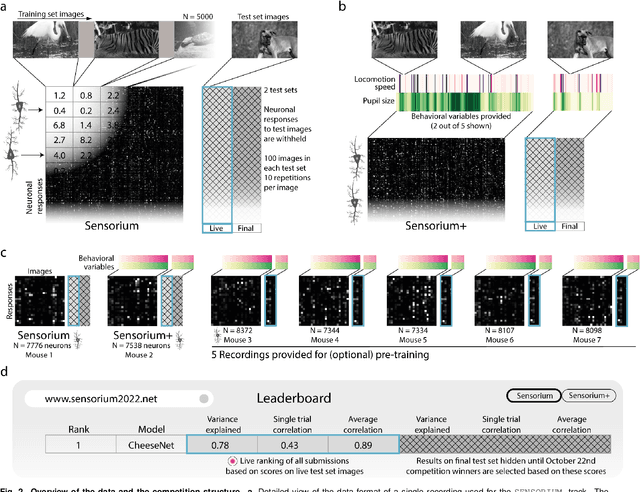
The neural underpinning of the biological visual system is challenging to study experimentally, in particular as the neuronal activity becomes increasingly nonlinear with respect to visual input. Artificial neural networks (ANNs) can serve a variety of goals for improving our understanding of this complex system, not only serving as predictive digital twins of sensory cortex for novel hypothesis generation in silico, but also incorporating bio-inspired architectural motifs to progressively bridge the gap between biological and machine vision. The mouse has recently emerged as a popular model system to study visual information processing, but no standardized large-scale benchmark to identify state-of-the-art models of the mouse visual system has been established. To fill this gap, we propose the Sensorium benchmark competition. We collected a large-scale dataset from mouse primary visual cortex containing the responses of more than 28,000 neurons across seven mice stimulated with thousands of natural images, together with simultaneous behavioral measurements that include running speed, pupil dilation, and eye movements. The benchmark challenge will rank models based on predictive performance for neuronal responses on a held-out test set, and includes two tracks for model input limited to either stimulus only (Sensorium) or stimulus plus behavior (Sensorium+). We provide a starting kit to lower the barrier for entry, including tutorials, pre-trained baseline models, and APIs with one line commands for data loading and submission. We would like to see this as a starting point for regular challenges and data releases, and as a standard tool for measuring progress in large-scale neural system identification models of the mouse visual system and beyond.
Understanding robustness and generalization of artificial neural networks through Fourier masks
Mar 16, 2022

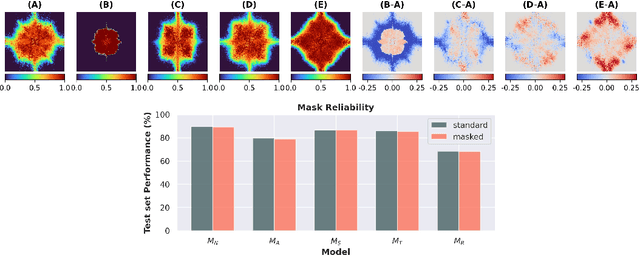
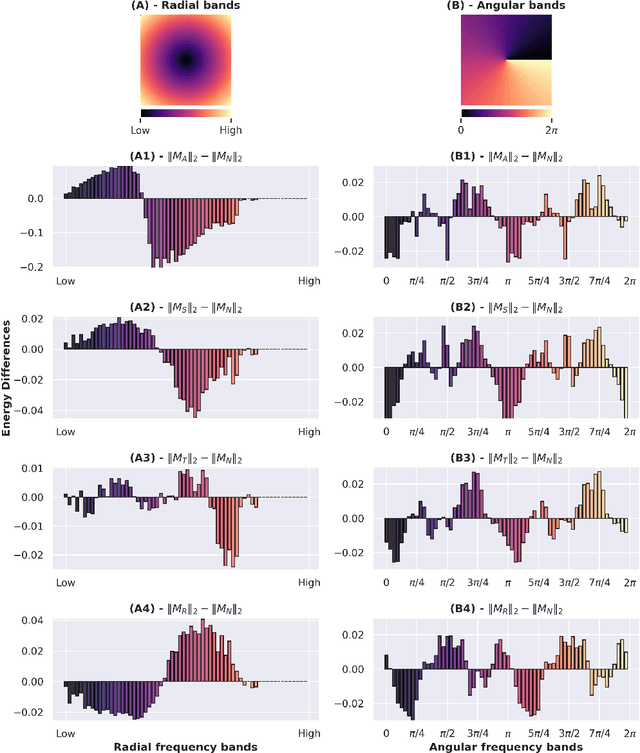
Despite the enormous success of artificial neural networks (ANNs) in many disciplines, the characterization of their computations and the origin of key properties such as generalization and robustness remain open questions. Recent literature suggests that robust networks with good generalization properties tend to be biased towards processing low frequencies in images. To explore the frequency bias hypothesis further, we develop an algorithm that allows us to learn modulatory masks highlighting the essential input frequencies needed for preserving a trained network's performance. We achieve this by imposing invariance in the loss with respect to such modulations in the input frequencies. We first use our method to test the low-frequency preference hypothesis of adversarially trained or data-augmented networks. Our results suggest that adversarially robust networks indeed exhibit a low-frequency bias but we find this bias is also dependent on directions in frequency space. However, this is not necessarily true for other types of data augmentation. Our results also indicate that the essential frequencies in question are effectively the ones used to achieve generalization in the first place. Surprisingly, images seen through these modulatory masks are not recognizable and resemble texture-like patterns.
Learning Dynamics and Structure of Complex Systems Using Graph Neural Networks
Feb 22, 2022
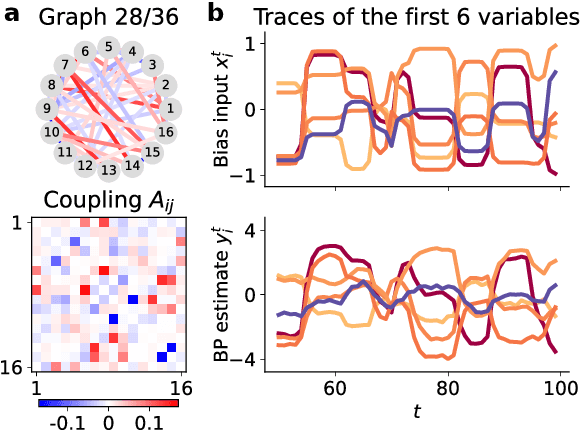
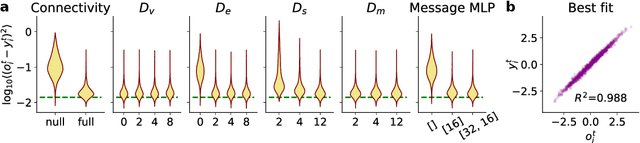

Many complex systems are composed of interacting parts, and the underlying laws are usually simple and universal. While graph neural networks provide a useful relational inductive bias for modeling such systems, generalization to new system instances of the same type is less studied. In this work we trained graph neural networks to fit time series from an example nonlinear dynamical system, the belief propagation algorithm. We found simple interpretations of the learned representation and model components, and they are consistent with core properties of the probabilistic inference algorithm. We successfully identified a `graph translator' between the statistical interactions in belief propagation and parameters of the corresponding trained network, and showed that it enables two types of novel generalization: to recover the underlying structure of a new system instance based solely on time series observations, or to construct a new network from this structure directly. Our results demonstrated a path towards understanding both dynamics and structure of a complex system and how such understanding can be used for generalization.
Towards robust vision by multi-task learning on monkey visual cortex
Jul 29, 2021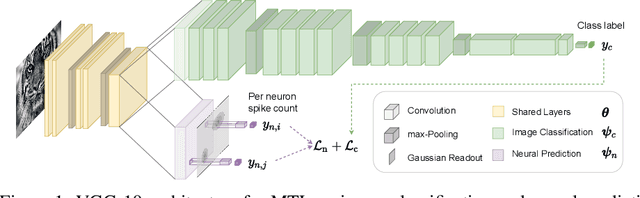
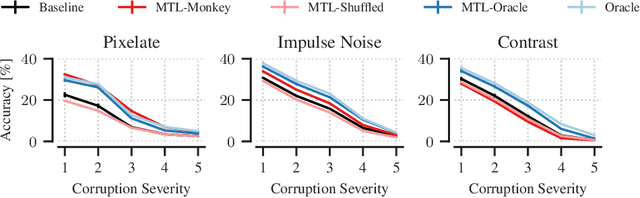
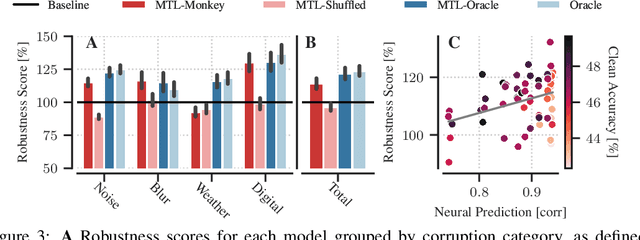
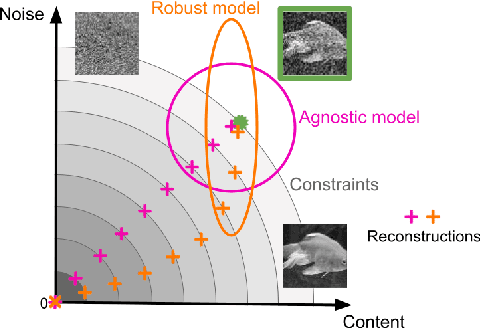
Deep neural networks set the state-of-the-art across many tasks in computer vision, but their generalization ability to image distortions is surprisingly fragile. In contrast, the mammalian visual system is robust to a wide range of perturbations. Recent work suggests that this generalization ability can be explained by useful inductive biases encoded in the representations of visual stimuli throughout the visual cortex. Here, we successfully leveraged these inductive biases with a multi-task learning approach: we jointly trained a deep network to perform image classification and to predict neural activity in macaque primary visual cortex (V1). We measured the out-of-distribution generalization abilities of our network by testing its robustness to image distortions. We found that co-training on monkey V1 data leads to increased robustness despite the absence of those distortions during training. Additionally, we showed that our network's robustness is very close to that of an Oracle network where parts of the architecture are directly trained on noisy images. Our results also demonstrated that the network's representations become more brain-like as their robustness improves. Using a novel constrained reconstruction analysis, we investigated what makes our brain-regularized network more robust. We found that our co-trained network is more sensitive to content than noise when compared to a Baseline network that we trained for image classification alone. Using DeepGaze-predicted saliency maps for ImageNet images, we found that our monkey co-trained network tends to be more sensitive to salient regions in a scene, reminiscent of existing theories on the role of V1 in the detection of object borders and bottom-up saliency. Overall, our work expands the promising research avenue of transferring inductive biases from the brain, and provides a novel analysis of the effects of our transfer.
Class-Incremental Learning with Generative Classifiers
Apr 28, 2021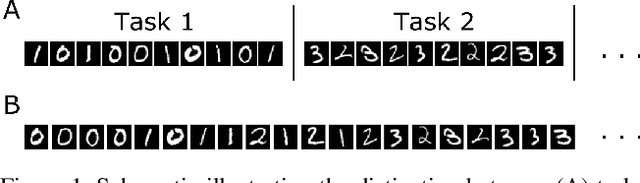

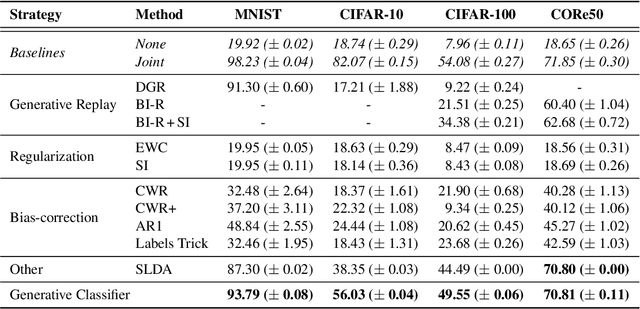

Incrementally training deep neural networks to recognize new classes is a challenging problem. Most existing class-incremental learning methods store data or use generative replay, both of which have drawbacks, while 'rehearsal-free' alternatives such as parameter regularization or bias-correction methods do not consistently achieve high performance. Here, we put forward a new strategy for class-incremental learning: generative classification. Rather than directly learning the conditional distribution p(y|x), our proposal is to learn the joint distribution p(x,y), factorized as p(x|y)p(y), and to perform classification using Bayes' rule. As a proof-of-principle, here we implement this strategy by training a variational autoencoder for each class to be learned and by using importance sampling to estimate the likelihoods p(x|y). This simple approach performs very well on a diverse set of continual learning benchmarks, outperforming generative replay and other existing baselines that do not store data.
Flexible Few-Shot Learning with Contextual Similarity
Dec 10, 2020


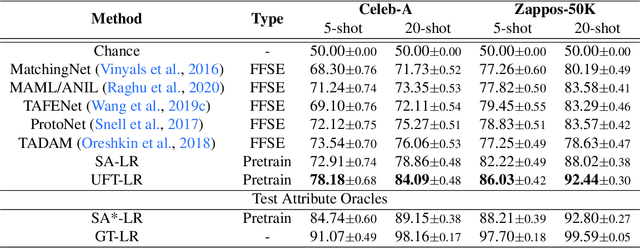
Existing approaches to few-shot learning deal with tasks that have persistent, rigid notions of classes. Typically, the learner observes data only from a fixed number of classes at training time and is asked to generalize to a new set of classes at test time. Two examples from the same class would always be assigned the same labels in any episode. In this work, we consider a realistic setting where the similarities between examples can change from episode to episode depending on the task context, which is not given to the learner. We define new benchmark datasets for this flexible few-shot scenario, where the tasks are based on images of faces (Celeb-A), shoes (Zappos50K), and general objects (ImageNet-with-Attributes). While classification baselines and episodic approaches learn representations that work well for standard few-shot learning, they suffer in our flexible tasks as novel similarity definitions arise during testing. We propose to build upon recent contrastive unsupervised learning techniques and use a combination of instance and class invariance learning, aiming to obtain general and flexible features. We find that our approach performs strongly on our new flexible few-shot learning benchmarks, demonstrating that unsupervised learning obtains more generalizable representations.