 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards robust vision by multi-task learning on monkey visual cortex
Jul 29, 2021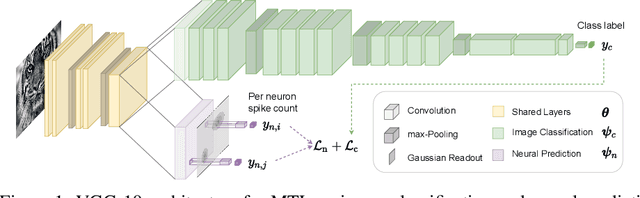
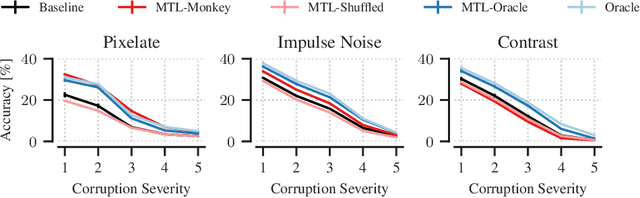
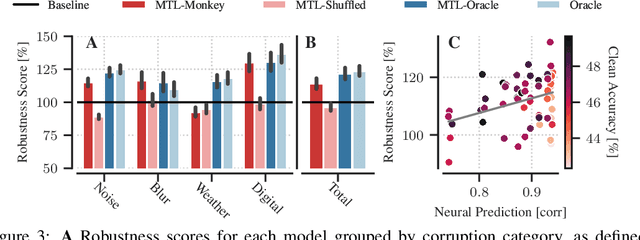
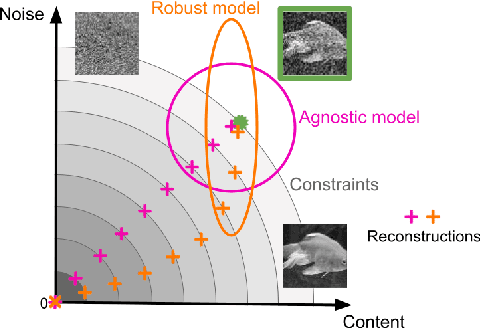
Deep neural networks set the state-of-the-art across many tasks in computer vision, but their generalization ability to image distortions is surprisingly fragile. In contrast, the mammalian visual system is robust to a wide range of perturbations. Recent work suggests that this generalization ability can be explained by useful inductive biases encoded in the representations of visual stimuli throughout the visual cortex. Here, we successfully leveraged these inductive biases with a multi-task learning approach: we jointly trained a deep network to perform image classification and to predict neural activity in macaque primary visual cortex (V1). We measured the out-of-distribution generalization abilities of our network by testing its robustness to image distortions. We found that co-training on monkey V1 data leads to increased robustness despite the absence of those distortions during training. Additionally, we showed that our network's robustness is very close to that of an Oracle network where parts of the architecture are directly trained on noisy images. Our results also demonstrated that the network's representations become more brain-like as their robustness improves. Using a novel constrained reconstruction analysis, we investigated what makes our brain-regularized network more robust. We found that our co-trained network is more sensitive to content than noise when compared to a Baseline network that we trained for image classification alone. Using DeepGaze-predicted saliency maps for ImageNet images, we found that our monkey co-trained network tends to be more sensitive to salient regions in a scene, reminiscent of existing theories on the role of V1 in the detection of object borders and bottom-up saliency. Overall, our work expands the promising research avenue of transferring inductive biases from the brain, and provides a novel analysis of the effects of our transfer.
On the Performance of Differential Evolution for Hyperparameter Tuning
Apr 15, 2019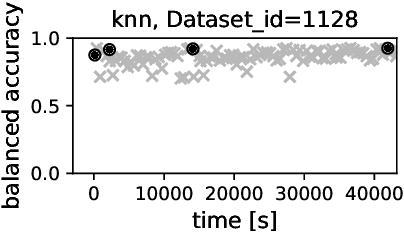
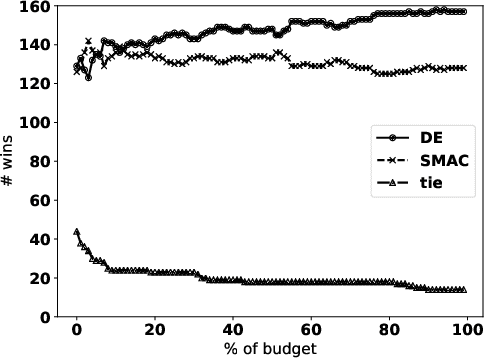
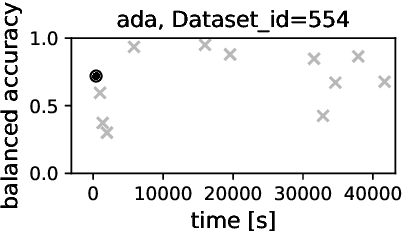

Automated hyperparameter tuning aspires to facilitate the application of machine learning for non-experts. In the literature, different optimization approaches are applied for that purpose. This paper investigates the performance of Differential Evolution for tuning hyperparameters of supervised learning algorithms for classification tasks. This empirical study involves a range of different machine learning algorithms and datasets with various characteristics to compare the performance of Differential Evolution with Sequential Model-based Algorithm Configuration (SMAC), a reference Bayesian Optimization approach. The results indicate that Differential Evolution outperforms SMAC for most datasets when tuning a given machine learning algorithm - particularly when breaking ties in a first-to-report fashion. Only for the tightest of computational budgets SMAC performs better. On small datasets, Differential Evolution outperforms SMAC by 19% (37% after tie-breaking). In a second experiment across a range of representative datasets taken from the literature, Differential Evolution scores 15% (23% after tie-breaking) more wins than SMAC.