 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConStellaration: A dataset of QI-like stellarator plasma boundaries and optimization benchmarks
Jun 24, 2025Stellarators are magnetic confinement devices under active development to deliver steady-state carbon-free fusion energy. Their design involves a high-dimensional, constrained optimization problem that requires expensive physics simulations and significant domain expertise. Recent advances in plasma physics and open-source tools have made stellarator optimization more accessible. However, broader community progress is currently bottlenecked by the lack of standardized optimization problems with strong baselines and datasets that enable data-driven approaches, particularly for quasi-isodynamic (QI) stellarator configurations, considered as a promising path to commercial fusion due to their inherent resilience to current-driven disruptions. Here, we release an open dataset of diverse QI-like stellarator plasma boundary shapes, paired with their ideal magnetohydrodynamic (MHD) equilibria and performance metrics. We generated this dataset by sampling a variety of QI fields and optimizing corresponding stellarator plasma boundaries. We introduce three optimization benchmarks of increasing complexity: (1) a single-objective geometric optimization problem, (2) a "simple-to-build" QI stellarator, and (3) a multi-objective ideal-MHD stable QI stellarator that investigates trade-offs between compactness and coil simplicity. For every benchmark, we provide reference code, evaluation scripts, and strong baselines based on classical optimization techniques. Finally, we show how learned models trained on our dataset can efficiently generate novel, feasible configurations without querying expensive physics oracles. By openly releasing the dataset along with benchmark problems and baselines, we aim to lower the entry barrier for optimization and machine learning researchers to engage in stellarator design and to accelerate cross-disciplinary progress toward bringing fusion energy to the grid.
The Sensorium competition on predicting large-scale mouse primary visual cortex activity
Jun 17, 2022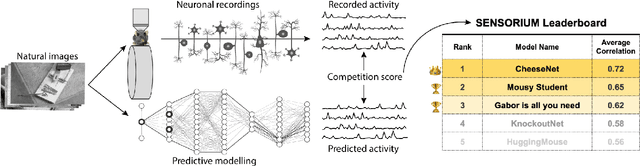
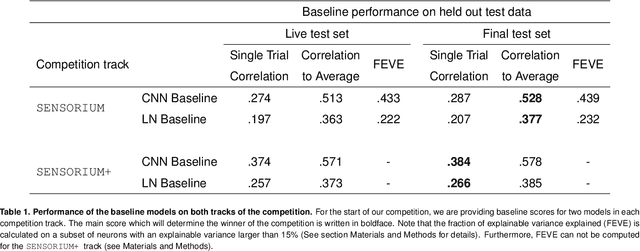
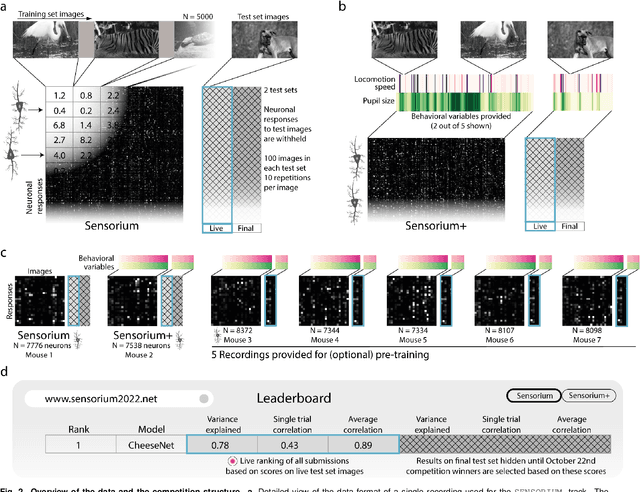
The neural underpinning of the biological visual system is challenging to study experimentally, in particular as the neuronal activity becomes increasingly nonlinear with respect to visual input. Artificial neural networks (ANNs) can serve a variety of goals for improving our understanding of this complex system, not only serving as predictive digital twins of sensory cortex for novel hypothesis generation in silico, but also incorporating bio-inspired architectural motifs to progressively bridge the gap between biological and machine vision. The mouse has recently emerged as a popular model system to study visual information processing, but no standardized large-scale benchmark to identify state-of-the-art models of the mouse visual system has been established. To fill this gap, we propose the Sensorium benchmark competition. We collected a large-scale dataset from mouse primary visual cortex containing the responses of more than 28,000 neurons across seven mice stimulated with thousands of natural images, together with simultaneous behavioral measurements that include running speed, pupil dilation, and eye movements. The benchmark challenge will rank models based on predictive performance for neuronal responses on a held-out test set, and includes two tracks for model input limited to either stimulus only (Sensorium) or stimulus plus behavior (Sensorium+). We provide a starting kit to lower the barrier for entry, including tutorials, pre-trained baseline models, and APIs with one line commands for data loading and submission. We would like to see this as a starting point for regular challenges and data releases, and as a standard tool for measuring progress in large-scale neural system identification models of the mouse visual system and beyond.
Towards robust vision by multi-task learning on monkey visual cortex
Jul 29, 2021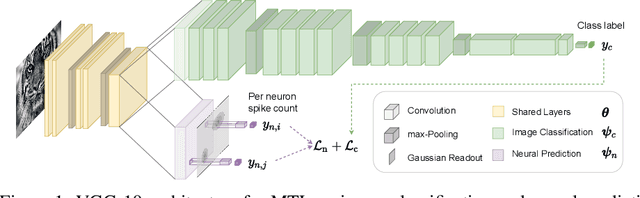
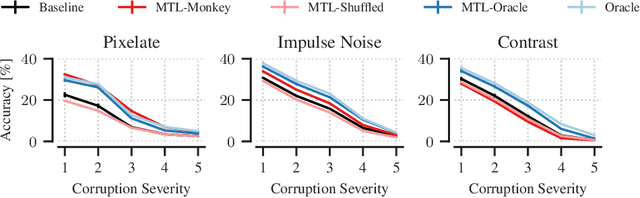
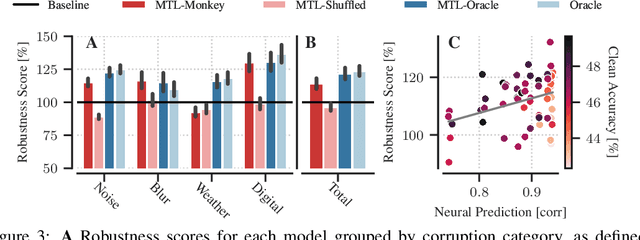
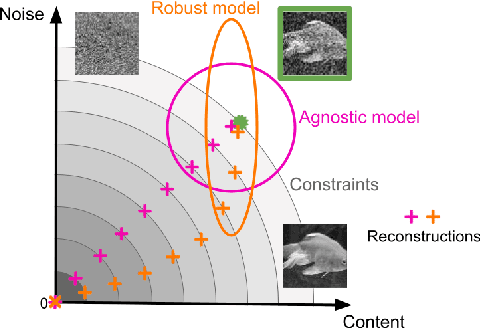
Deep neural networks set the state-of-the-art across many tasks in computer vision, but their generalization ability to image distortions is surprisingly fragile. In contrast, the mammalian visual system is robust to a wide range of perturbations. Recent work suggests that this generalization ability can be explained by useful inductive biases encoded in the representations of visual stimuli throughout the visual cortex. Here, we successfully leveraged these inductive biases with a multi-task learning approach: we jointly trained a deep network to perform image classification and to predict neural activity in macaque primary visual cortex (V1). We measured the out-of-distribution generalization abilities of our network by testing its robustness to image distortions. We found that co-training on monkey V1 data leads to increased robustness despite the absence of those distortions during training. Additionally, we showed that our network's robustness is very close to that of an Oracle network where parts of the architecture are directly trained on noisy images. Our results also demonstrated that the network's representations become more brain-like as their robustness improves. Using a novel constrained reconstruction analysis, we investigated what makes our brain-regularized network more robust. We found that our co-trained network is more sensitive to content than noise when compared to a Baseline network that we trained for image classification alone. Using DeepGaze-predicted saliency maps for ImageNet images, we found that our monkey co-trained network tends to be more sensitive to salient regions in a scene, reminiscent of existing theories on the role of V1 in the detection of object borders and bottom-up saliency. Overall, our work expands the promising research avenue of transferring inductive biases from the brain, and provides a novel analysis of the effects of our transfer.
A rotation-equivariant convolutional neural network model of primary visual cortex
Sep 27, 2018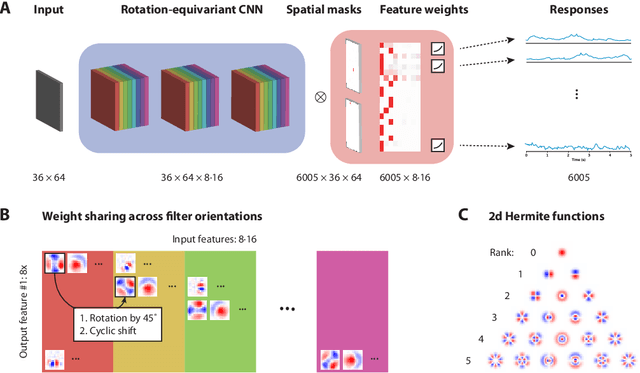
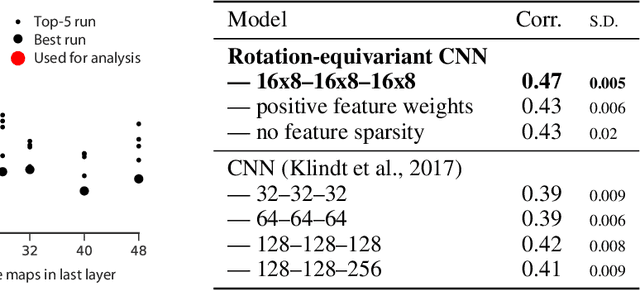
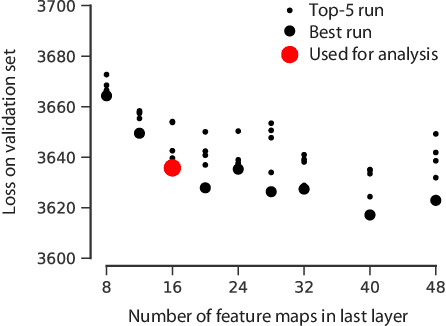
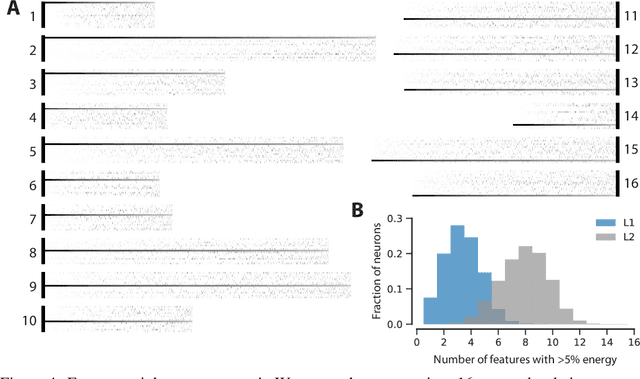
Classical models describe primary visual cortex (V1) as a filter bank of orientation-selective linear-nonlinear (LN) or energy models, but these models fail to predict neural responses to natural stimuli accurately. Recent work shows that models based on convolutional neural networks (CNNs) lead to much more accurate predictions, but it remains unclear which features are extracted by V1 neurons beyond orientation selectivity and phase invariance. Here we work towards systematically studying V1 computations by categorizing neurons into groups that perform similar computations. We present a framework to identify common features independent of individual neurons' orientation selectivity by using a rotation-equivariant convolutional neural network, which automatically extracts every feature at multiple different orientations. We fit this model to responses of a population of 6000 neurons to natural images recorded in mouse primary visual cortex using two-photon imaging. We show that our rotation-equivariant network not only outperforms a regular CNN with the same number of feature maps, but also reveals a number of common features shared by many V1 neurons, which deviate from the typical textbook idea of V1 as a bank of Gabor filters. Our findings are a first step towards a powerful new tool to study the nonlinear computations in V1.
Diverse feature visualizations reveal invariances in early layers of deep neural networks
Jul 27, 2018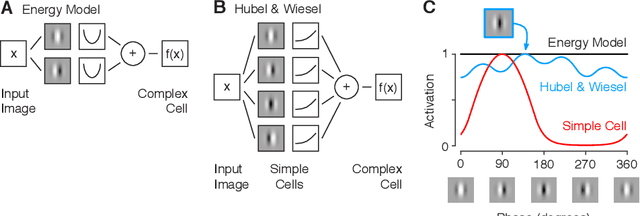
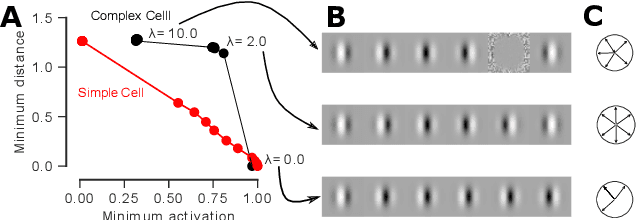
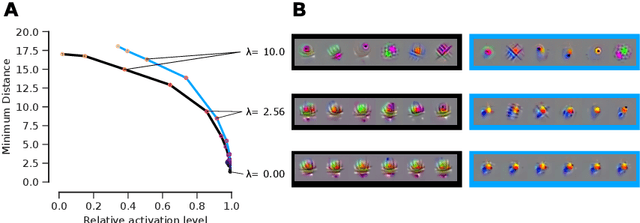
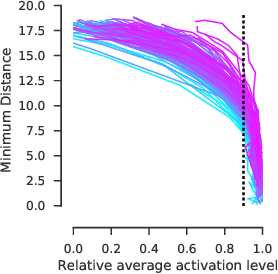
Visualizing features in deep neural networks (DNNs) can help understanding their computations. Many previous studies aimed to visualize the selectivity of individual units by finding meaningful images that maximize their activation. However, comparably little attention has been paid to visualizing to what image transformations units in DNNs are invariant. Here we propose a method to discover invariances in the responses of hidden layer units of deep neural networks. Our approach is based on simultaneously searching for a batch of images that strongly activate a unit while at the same time being as distinct from each other as possible. We find that even early convolutional layers in VGG-19 exhibit various forms of response invariance: near-perfect phase invariance in some units and invariance to local diffeomorphic transformations in others. At the same time, we uncover representational differences with ResNet-50 in its corresponding layers. We conclude that invariance transformations are a major computational component learned by DNNs and we provide a systematic method to study them.