 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based metrics: Sample-efficient estimates of predictive model subpopulation performance
Apr 25, 2021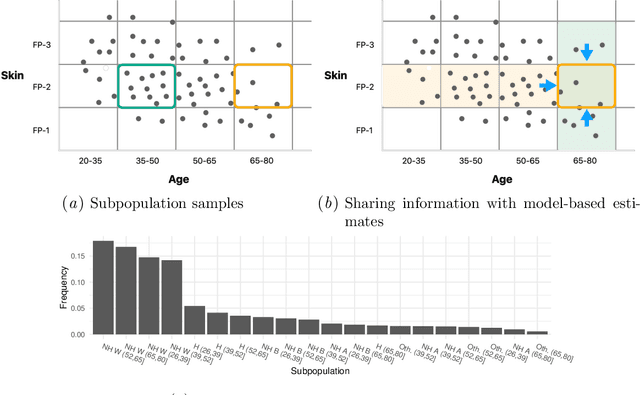
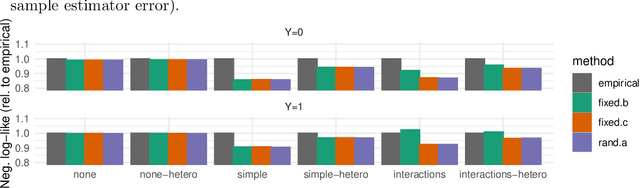
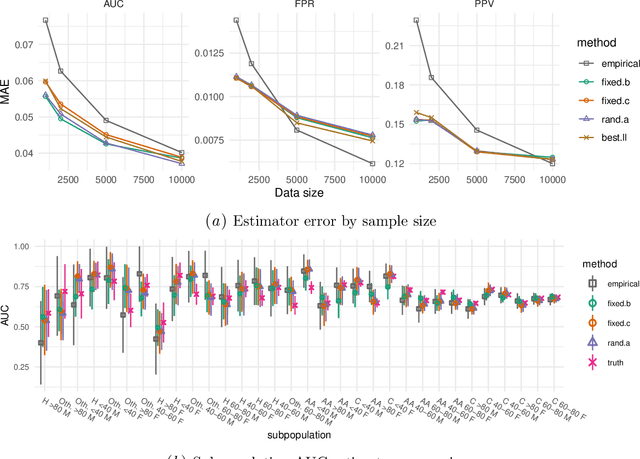
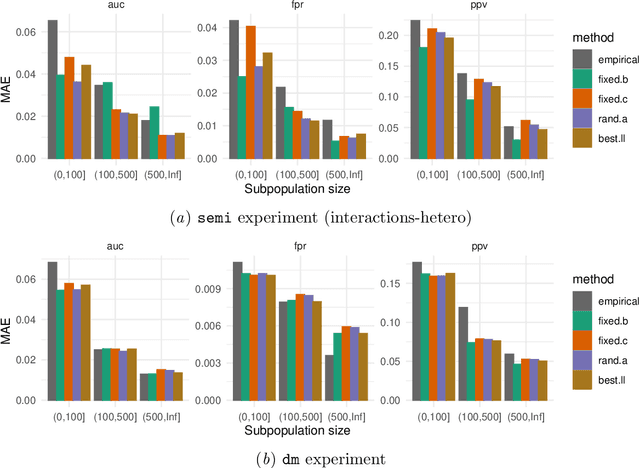
Machine learning models $-$ now commonly developed to screen, diagnose, or predict health conditions $-$ are evaluated with a variety of performance metrics. An important first step in assessing the practical utility of a model is to evaluate its average performance over an entire population of interest. In many settings, it is also critical that the model makes good predictions within predefined subpopulations. For instance, showing that a model is fair or equitable requires evaluating the model's performance in different demographic subgroups. However, subpopulation performance metrics are typically computed using only data from that subgroup, resulting in higher variance estimates for smaller groups. We devise a procedure to measure subpopulation performance that can be more sample-efficient than the typical subsample estimates. We propose using an evaluation model $-$ a model that describes the conditional distribution of the predictive model score $-$ to form model-based metric (MBM) estimates. Our procedure incorporates model checking and validation, and we propose a computationally efficient approximation of the traditional nonparametric bootstrap to form confidence intervals. We evaluate MBMs on two main tasks: a semi-synthetic setting where ground truth metrics are available and a real-world hospital readmission prediction task. We find that MBMs consistently produce more accurate and lower variance estimates of model performance for small subpopulations.
Modeling patterns of smartphone usage and their relationship to cognitive health
Nov 13, 2019


The ubiquity of smartphone usage in many people's lives make it a rich source of information about a person's mental and cognitive state. In this work we analyze 12 weeks of phone usage data from 113 older adults, 31 with diagnosed cognitive impairment and 82 without. We develop structured models of users' smartphone interactions to reveal differences in phone usage patterns between people with and without cognitive impairment. In particular, we focus on inferring specific types of phone usage sessions that are predictive of cognitive impairment. Our model achieves an AUROC of 0.79 when discriminating between healthy and symptomatic subjects, and its interpretability enables novel insights into which aspects of phone usage strongly relate with cognitive health in our dataset.
Diverse feature visualizations reveal invariances in early layers of deep neural networks
Jul 27, 2018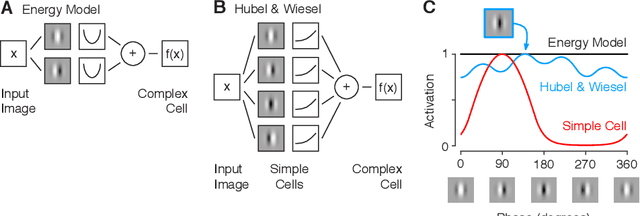
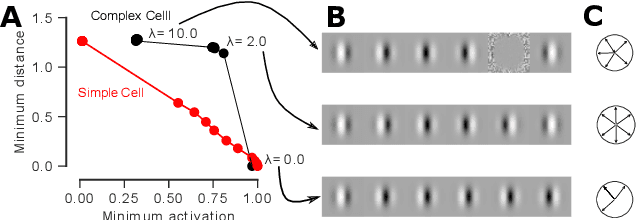
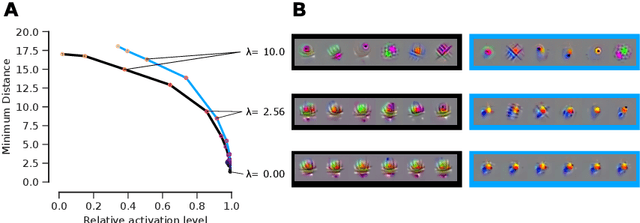
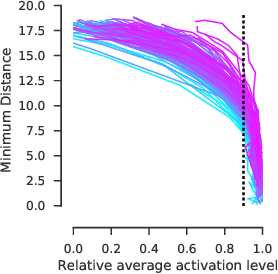
Visualizing features in deep neural networks (DNNs) can help understanding their computations. Many previous studies aimed to visualize the selectivity of individual units by finding meaningful images that maximize their activation. However, comparably little attention has been paid to visualizing to what image transformations units in DNNs are invariant. Here we propose a method to discover invariances in the responses of hidden layer units of deep neural networks. Our approach is based on simultaneously searching for a batch of images that strongly activate a unit while at the same time being as distinct from each other as possible. We find that even early convolutional layers in VGG-19 exhibit various forms of response invariance: near-perfect phase invariance in some units and invariance to local diffeomorphic transformations in others. At the same time, we uncover representational differences with ResNet-50 in its corresponding layers. We conclude that invariance transformations are a major computational component learned by DNNs and we provide a systematic method to study them.
Guiding human gaze with convolutional neural networks
Dec 18, 2017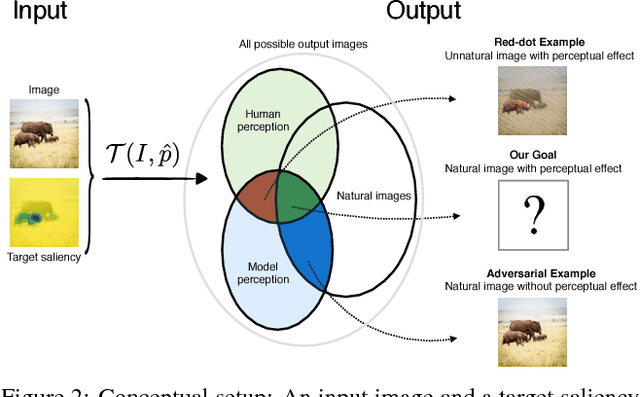
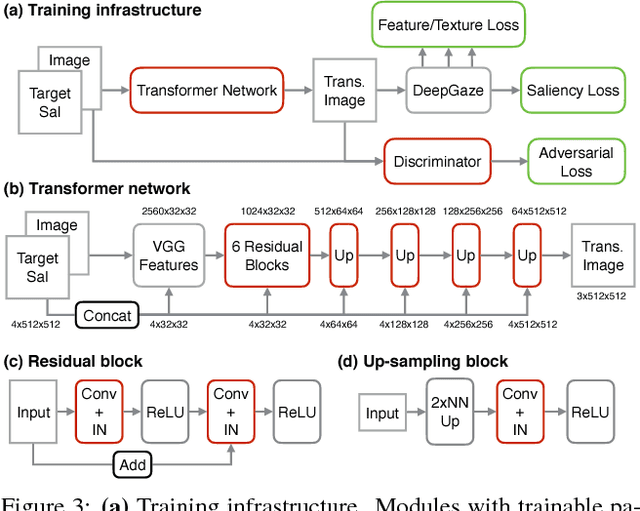
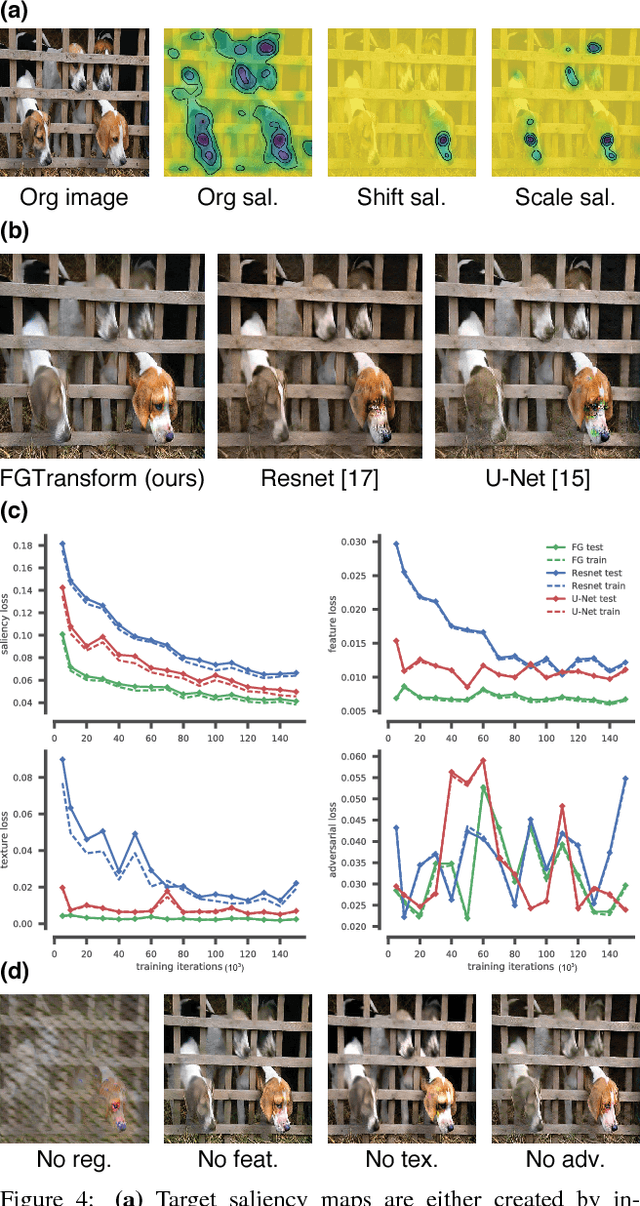

The eye fixation patterns of human observers are a fundamental indicator of the aspects of an image to which humans attend. Thus, manipulating fixation patterns to guide human attention is an exciting challenge in digital image processing. Here, we present a new model for manipulating images to change the distribution of human fixations in a controlled fashion. We use the state-of-the-art model for fixation prediction to train a convolutional neural network to transform images so that they satisfy a given fixation distribution. For network training, we carefully design a loss function to achieve a perceptual effect while preserving naturalness of the transformed images. Finally, we evaluate the success of our model by measuring human fixations for a set of manipulated images. On our test images we can in-/decrease the probability to fixate on selected objects on average by 43/22% but show that the effectiveness of the model depends on the semantic content of the manipulated images.
Controlling Perceptual Factors in Neural Style Transfer
May 11, 2017



Neural Style Transfer has shown very exciting results enabling new forms of image manipulation. Here we extend the existing method to introduce control over spatial location, colour information and across spatial scale. We demonstrate how this enhances the method by allowing high-resolution controlled stylisation and helps to alleviate common failure cases such as applying ground textures to sky regions. Furthermore, by decomposing style into these perceptual factors we enable the combination of style information from multiple sources to generate new, perceptually appealing styles from existing ones. We also describe how these methods can be used to more efficiently produce large size, high-quality stylisation. Finally we show how the introduced control measures can be applied in recent methods for Fast Neural Style Transfer.
Synthesising Dynamic Textures using Convolutional Neural Networks
Feb 22, 2017



Here we present a parametric model for dynamic textures. The model is based on spatiotemporal summary statistics computed from the feature representations of a Convolutional Neural Network (CNN) trained on object recognition. We demonstrate how the model can be used to synthesise new samples of dynamic textures and to predict motion in simple movies.
Preserving Color in Neural Artistic Style Transfer
Jun 19, 2016

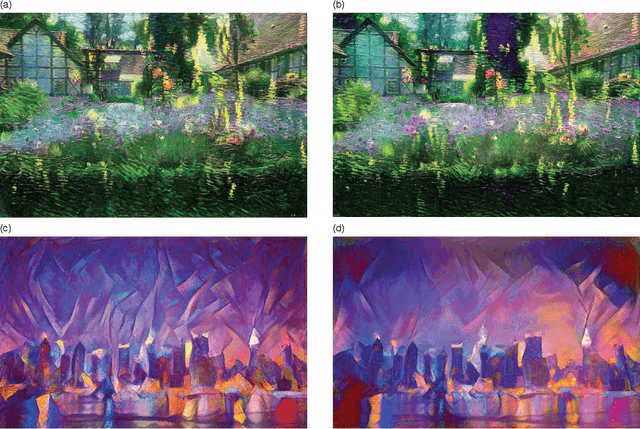

This note presents an extension to the neural artistic style transfer algorithm (Gatys et al.). The original algorithm transforms an image to have the style of another given image. For example, a photograph can be transformed to have the style of a famous painting. Here we address a potential shortcoming of the original method: the algorithm transfers the colors of the original painting, which can alter the appearance of the scene in undesirable ways. We describe simple linear methods for transferring style while preserving colors.
Texture Synthesis Using Shallow Convolutional Networks with Random Filters
May 31, 2016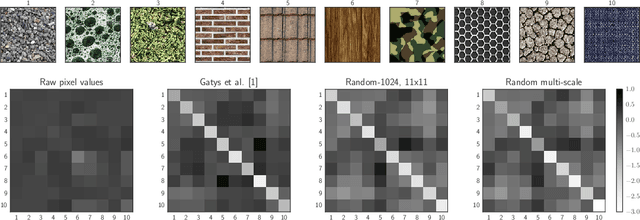



Here we demonstrate that the feature space of random shallow convolutional neural networks (CNNs) can serve as a surprisingly good model of natural textures. Patches from the same texture are consistently classified as being more similar then patches from different textures. Samples synthesized from the model capture spatial correlations on scales much larger then the receptive field size, and sometimes even rival or surpass the perceptual quality of state of the art texture models (but show less variability). The current state of the art in parametric texture synthesis relies on the multi-layer feature space of deep CNNs that were trained on natural images. Our finding suggests that such optimized multi-layer feature spaces are not imperative for texture modeling. Instead, much simpler shallow and convolutional networks can serve as the basis for novel texture synthesis algorithms.
Texture Synthesis Using Convolutional Neural Networks
Nov 06, 2015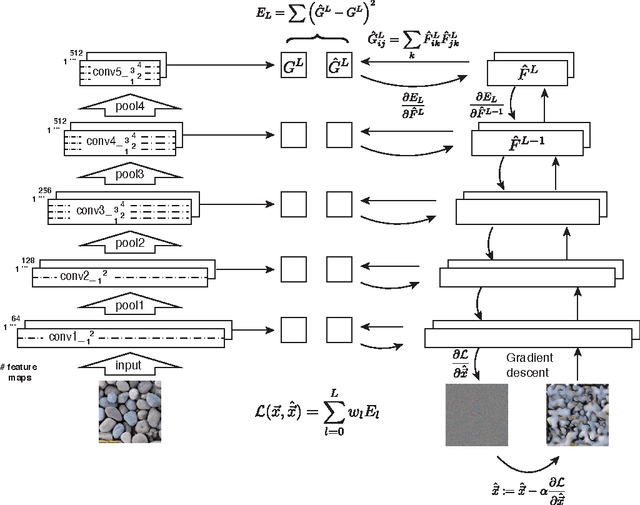



Here we introduce a new model of natural textures based on the feature spaces of convolutional neural networks optimised for object recognition. Samples from the model are of high perceptual quality demonstrating the generative power of neural networks trained in a purely discriminative fashion. Within the model, textures are represented by the correlations between feature maps in several layers of the network. We show that across layers the texture representations increasingly capture the statistical properties of natural images while making object information more and more explicit. The model provides a new tool to generate stimuli for neuroscience and might offer insights into the deep representations learned by convolutional neural networks.
A Neural Algorithm of Artistic Style
Sep 02, 2015


In fine art, especially painting, humans have mastered the skill to create unique visual experiences through composing a complex interplay between the content and style of an image. Thus far the algorithmic basis of this process is unknown and there exists no artificial system with similar capabilities. However, in other key areas of visual perception such as object and face recognition near-human performance was recently demonstrated by a class of biologically inspired vision models called Deep Neural Networks. Here we introduce an artificial system based on a Deep Neural Network that creates artistic images of high perceptual quality. The system uses neural representations to separate and recombine content and style of arbitrary images, providing a neural algorithm for the creation of artistic images. Moreover, in light of the striking similarities between performance-optimised artificial neural networks and biological vision, our work offers a path forward to an algorithmic understanding of how humans create and perceive artistic imagery.