 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMooneyMaker: A Python package to create ambiguous two-tone images
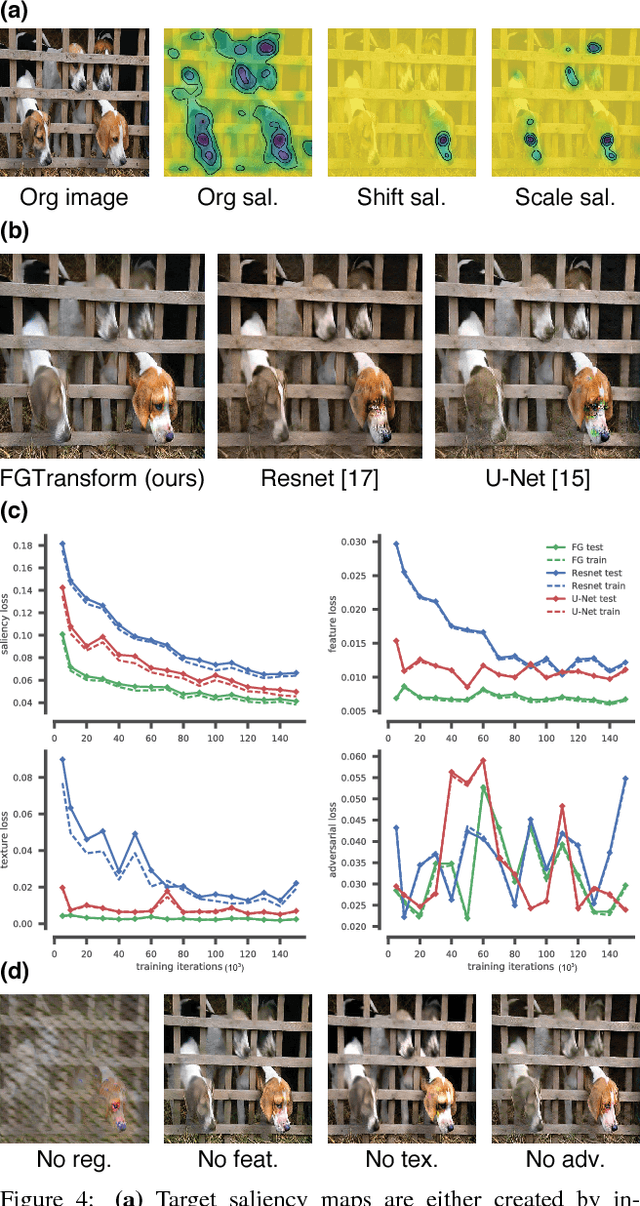
Jan 20, 2026Mooney images are high-contrast, two-tone visual stimuli, created by thresholding photographic images. They allow researchers to separate image content from image understanding, making them valuable for studying visual perception. An ideal Mooney image for this purpose achieves a specific balance: it initially appears unrecognizable but becomes fully interpretable to the observer after seeing the original template. Researchers traditionally created these stimuli manually using subjective criteria, which is labor-intensive and can introduce inconsistencies across studies. Automated generation techniques now offer an alternative to this manual approach. Here, we present MooneyMaker, an open-source Python package that automates the generation of ambiguous Mooney images using several complementary approaches. Users can choose between various generation techniques that range from approaches based on image statistics to deep learning models. These models strategically alter edge information to increase initial ambiguity. The package lets users create two-tone images with multiple methods and directly compare the results visually. In an experiment, we validate MooneyMaker by generating Mooney images using different techniques and assess their recognizability for human observers before and after disambiguating them by presenting the template images. Our results reveal that techniques with lower initial recognizability are associated with higher post-template recognition (i.e. a larger disambiguation effect). To help vision scientists build effective databases of Mooney stimuli, we provide practical guidelines for technique selection. By standardizing the generation process, MooneyMaker supports more consistent and reproducible visual perception research.
MRD: Using Physically Based Differentiable Rendering to Probe Vision Models for 3D Scene Understanding
Dec 13, 2025While deep learning methods have achieved impressive success in many vision benchmarks, it remains difficult to understand and explain the representations and decisions of these models. Though vision models are typically trained on 2D inputs, they are often assumed to develop an implicit representation of the underlying 3D scene (for example, showing tolerance to partial occlusion, or the ability to reason about relative depth). Here, we introduce MRD (metamers rendered differentiably), an approach that uses physically based differentiable rendering to probe vision models' implicit understanding of generative 3D scene properties, by finding 3D scene parameters that are physically different but produce the same model activation (i.e. are model metamers). Unlike previous pixel-based methods for evaluating model representations, these reconstruction results are always grounded in physical scene descriptions. This means we can, for example, probe a model's sensitivity to object shape while holding material and lighting constant. As a proof-of-principle, we assess multiple models in their ability to recover scene parameters of geometry (shape) and bidirectional reflectance distribution function (material). The results show high similarity in model activation between target and optimized scenes, with varying visual results. Qualitatively, these reconstructions help investigate the physical scene attributes to which models are sensitive or invariant. MRD holds promise for advancing our understanding of both computer and human vision by enabling analysis of how physical scene parameters drive changes in model responses.
How Well do Feature Visualizations Support Causal Understanding of CNN Activations?
Jun 23, 2021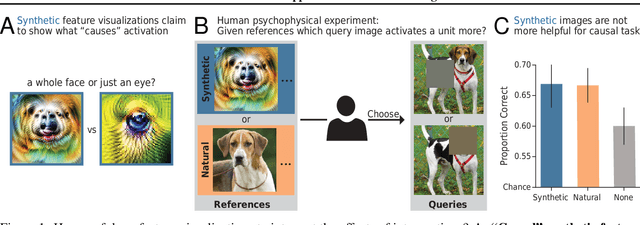

One widely used approach towards understanding the inner workings of deep convolutional neural networks is to visualize unit responses via activation maximization. Feature visualizations via activation maximization are thought to provide humans with precise information about the image features that cause a unit to be activated. If this is indeed true, these synthetic images should enable humans to predict the effect of an intervention, such as whether occluding a certain patch of the image (say, a dog's head) changes a unit's activation. Here, we test this hypothesis by asking humans to predict which of two square occlusions causes a larger change to a unit's activation. Both a large-scale crowdsourced experiment and measurements with experts show that on average, the extremely activating feature visualizations by Olah et al. (2017) indeed help humans on this task ($67 \pm 4\%$ accuracy; baseline performance without any visualizations is $60 \pm 3\%$). However, they do not provide any significant advantage over other visualizations (such as e.g. dataset samples), which yield similar performance ($66 \pm 3\%$ to $67 \pm 3\%$ accuracy). Taken together, we propose an objective psychophysical task to quantify the benefit of unit-level interpretability methods for humans, and find no evidence that feature visualizations provide humans with better "causal understanding" than simple alternative visualizations.
Exemplary Natural Images Explain CNN Activations Better than Feature Visualizations
Oct 23, 2020

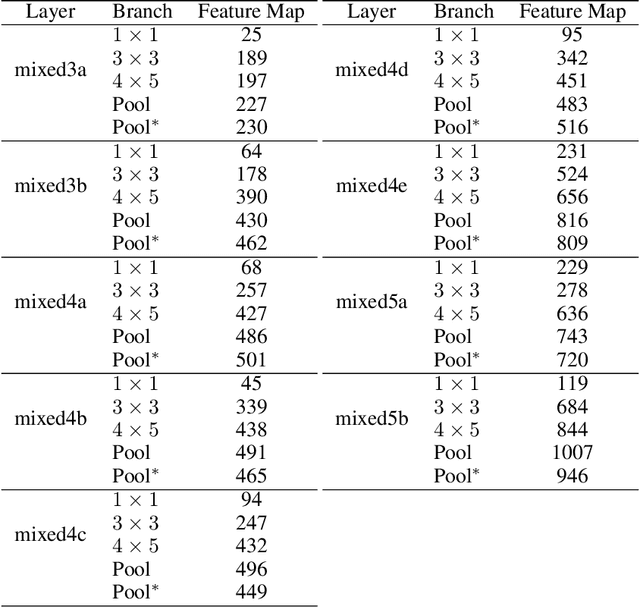
Feature visualizations such as synthetic maximally activating images are a widely used explanation method to better understand the information processing of convolutional neural networks (CNNs). At the same time, there are concerns that these visualizations might not accurately represent CNNs' inner workings. Here, we measure how much extremely activating images help humans to predict CNN activations. Using a well-controlled psychophysical paradigm, we compare the informativeness of synthetic images (Olah et al., 2017) with a simple baseline visualization, namely exemplary natural images that also strongly activate a specific feature map. Given either synthetic or natural reference images, human participants choose which of two query images leads to strong positive activation. The experiment is designed to maximize participants' performance, and is the first to probe intermediate instead of final layer representations. We find that synthetic images indeed provide helpful information about feature map activations (82% accuracy; chance would be 50%). However, natural images-originally intended to be a baseline-outperform synthetic images by a wide margin (92% accuracy). Additionally, participants are faster and more confident for natural images, whereas subjective impressions about the interpretability of feature visualization are mixed. The higher informativeness of natural images holds across most layers, for both expert and lay participants as well as for hand- and randomly-picked feature visualizations. Even if only a single reference image is given, synthetic images provide less information than natural images (65% vs. 73%). In summary, popular synthetic images from feature visualizations are significantly less informative for assessing CNN activations than natural images. We argue that future visualization methods should improve over this simple baseline.
The Notorious Difficulty of Comparing Human and Machine Perception
Apr 20, 2020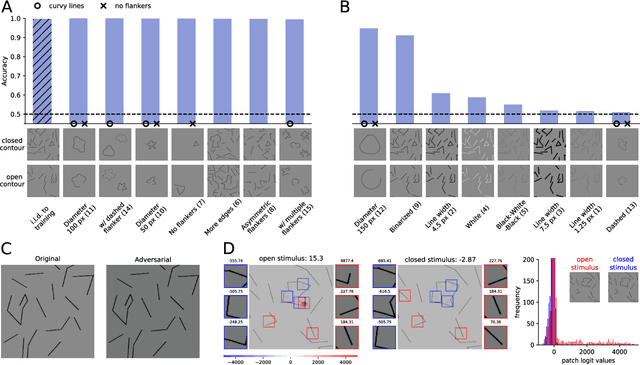


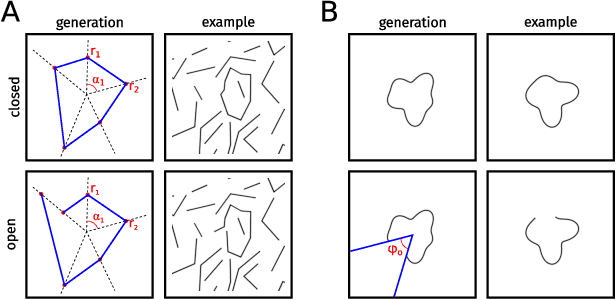
With the rise of machines to human-level performance in complex recognition tasks, a growing amount of work is directed towards comparing information processing in humans and machines. These works have the potential to deepen our understanding of the inner mechanisms of human perception and to improve machine learning. Drawing robust conclusions from comparison studies, however, turns out to be difficult. Here, we highlight common shortcomings that can easily lead to fragile conclusions. First, if a model does achieve high performance on a task similar to humans, its decision-making process is not necessarily human-like. Moreover, further analyses can reveal differences. Second, the performance of neural networks is sensitive to training procedures and architectural details. Thus, generalizing conclusions from specific architectures is difficult. Finally, when comparing humans and machines, equivalent experimental settings are crucial in order to identify innate differences. Addressing these shortcomings alters or refines the conclusions of studies. We show that, despite their ability to solve closed-contour tasks, our neural networks use different decision-making strategies than humans. We further show that there is no fundamental difference between same-different and spatial tasks for common feed-forward neural networks and finally, that neural networks do experience a "recognition gap" on minimal recognizable images. All in all, care has to be taken to not impose our human systematic bias when comparing human and machine perception.
Saliency Benchmarking Made Easy: Separating Models, Maps and Metrics
Jul 25, 2018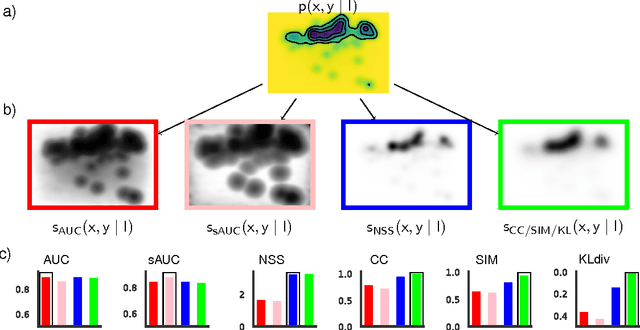

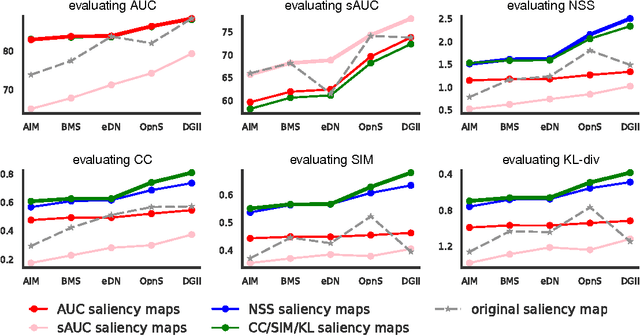
Dozens of new models on fixation prediction are published every year and compared on open benchmarks such as MIT300 and LSUN. However, progress in the field can be difficult to judge because models are compared using a variety of inconsistent metrics. Here we show that no single saliency map can perform well under all metrics. Instead, we propose a principled approach to solve the benchmarking problem by separating the notions of saliency models, maps and metrics. Inspired by Bayesian decision theory, we define a saliency model to be a probabilistic model of fixation density prediction and a saliency map to be a metric-specific prediction derived from the model density which maximizes the expected performance on that metric given the model density. We derive these optimal saliency maps for the most commonly used saliency metrics (AUC, sAUC, NSS, CC, SIM, KL-Div) and show that they can be computed analytically or approximated with high precision. We show that this leads to consistent rankings in all metrics and avoids the penalties of using one saliency map for all metrics. Our method allows researchers to have their model compete on many different metrics with state-of-the-art in those metrics: "good" models will perform well in all metrics.
Guiding human gaze with convolutional neural networks
Dec 18, 2017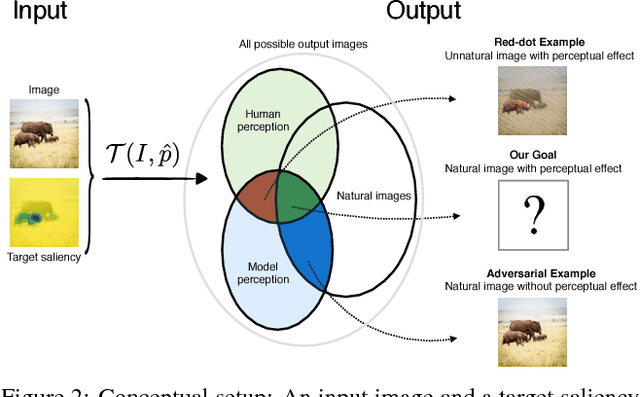
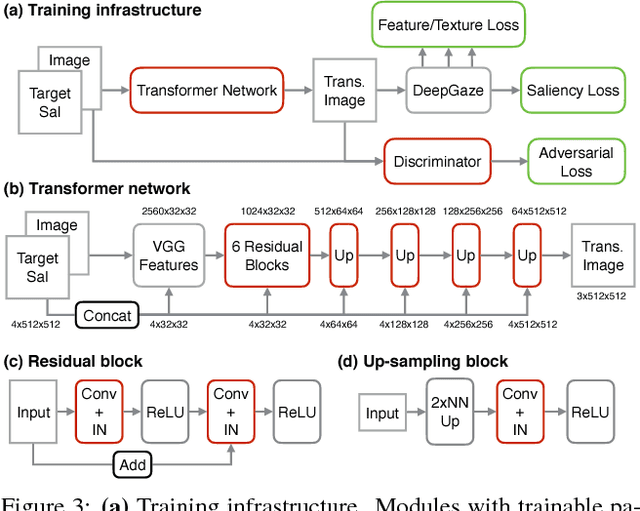

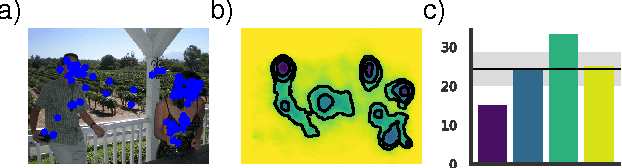
The eye fixation patterns of human observers are a fundamental indicator of the aspects of an image to which humans attend. Thus, manipulating fixation patterns to guide human attention is an exciting challenge in digital image processing. Here, we present a new model for manipulating images to change the distribution of human fixations in a controlled fashion. We use the state-of-the-art model for fixation prediction to train a convolutional neural network to transform images so that they satisfy a given fixation distribution. For network training, we carefully design a loss function to achieve a perceptual effect while preserving naturalness of the transformed images. Finally, we evaluate the success of our model by measuring human fixations for a set of manipulated images. On our test images we can in-/decrease the probability to fixate on selected objects on average by 43/22% but show that the effectiveness of the model depends on the semantic content of the manipulated images.
DeepGaze II: Reading fixations from deep features trained on object recognition
Oct 05, 2016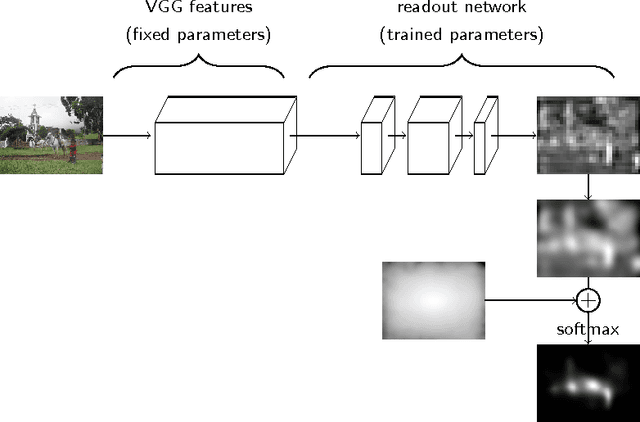

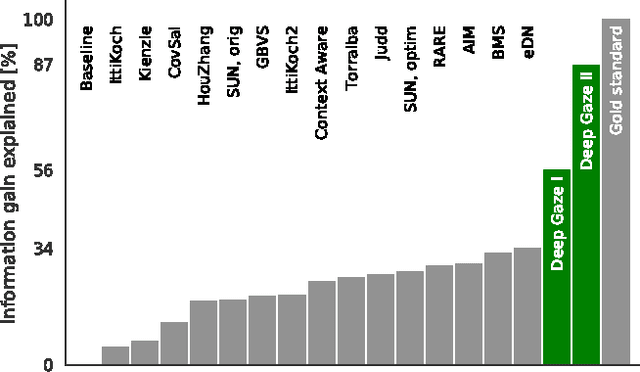
Here we present DeepGaze II, a model that predicts where people look in images. The model uses the features from the VGG-19 deep neural network trained to identify objects in images. Contrary to other saliency models that use deep features, here we use the VGG features for saliency prediction with no additional fine-tuning (rather, a few readout layers are trained on top of the VGG features to predict saliency). The model is therefore a strong test of transfer learning. After conservative cross-validation, DeepGaze II explains about 87% of the explainable information gain in the patterns of fixations and achieves top performance in area under the curve metrics on the MIT300 hold-out benchmark. These results corroborate the finding from DeepGaze I (which explained 56% of the explainable information gain), that deep features trained on object recognition provide a versatile feature space for performing related visual tasks. We explore the factors that contribute to this success and present several informative image examples. A web service is available to compute model predictions at http://deepgaze.bethgelab.org.