 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Analysis of CNN Robustness
Oct 14, 2021
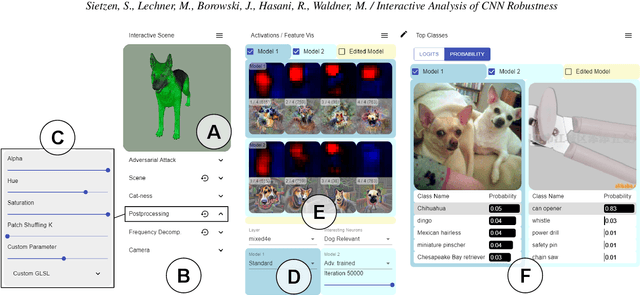

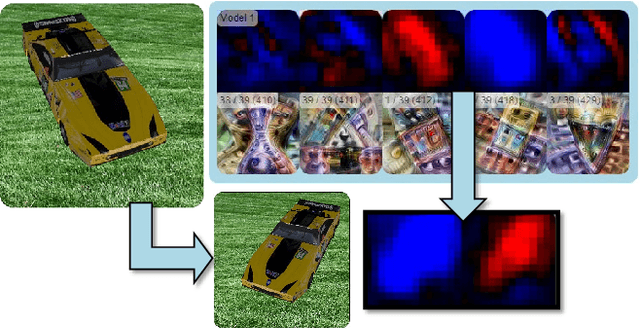
While convolutional neural networks (CNNs) have found wide adoption as state-of-the-art models for image-related tasks, their predictions are often highly sensitive to small input perturbations, which the human vision is robust against. This paper presents Perturber, a web-based application that allows users to instantaneously explore how CNN activations and predictions evolve when a 3D input scene is interactively perturbed. Perturber offers a large variety of scene modifications, such as camera controls, lighting and shading effects, background modifications, object morphing, as well as adversarial attacks, to facilitate the discovery of potential vulnerabilities. Fine-tuned model versions can be directly compared for qualitative evaluation of their robustness. Case studies with machine learning experts have shown that Perturber helps users to quickly generate hypotheses about model vulnerabilities and to qualitatively compare model behavior. Using quantitative analyses, we could replicate users' insights with other CNN architectures and input images, yielding new insights about the vulnerability of adversarially trained models.
How Well do Feature Visualizations Support Causal Understanding of CNN Activations?
Jun 23, 2021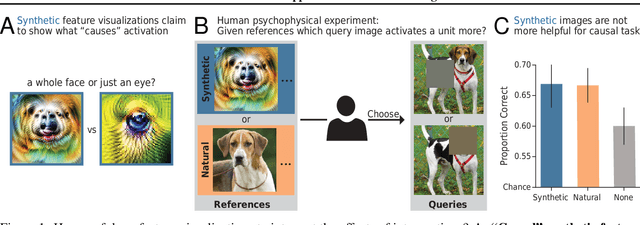

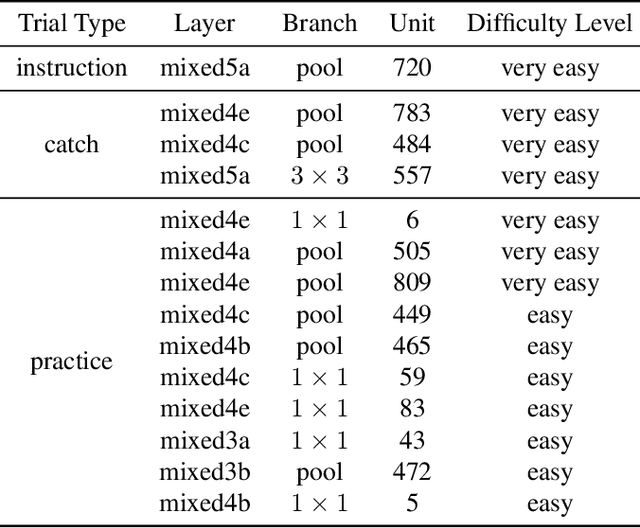
One widely used approach towards understanding the inner workings of deep convolutional neural networks is to visualize unit responses via activation maximization. Feature visualizations via activation maximization are thought to provide humans with precise information about the image features that cause a unit to be activated. If this is indeed true, these synthetic images should enable humans to predict the effect of an intervention, such as whether occluding a certain patch of the image (say, a dog's head) changes a unit's activation. Here, we test this hypothesis by asking humans to predict which of two square occlusions causes a larger change to a unit's activation. Both a large-scale crowdsourced experiment and measurements with experts show that on average, the extremely activating feature visualizations by Olah et al. (2017) indeed help humans on this task ($67 \pm 4\%$ accuracy; baseline performance without any visualizations is $60 \pm 3\%$). However, they do not provide any significant advantage over other visualizations (such as e.g. dataset samples), which yield similar performance ($66 \pm 3\%$ to $67 \pm 3\%$ accuracy). Taken together, we propose an objective psychophysical task to quantify the benefit of unit-level interpretability methods for humans, and find no evidence that feature visualizations provide humans with better "causal understanding" than simple alternative visualizations.
Exemplary Natural Images Explain CNN Activations Better than Feature Visualizations
Oct 23, 2020

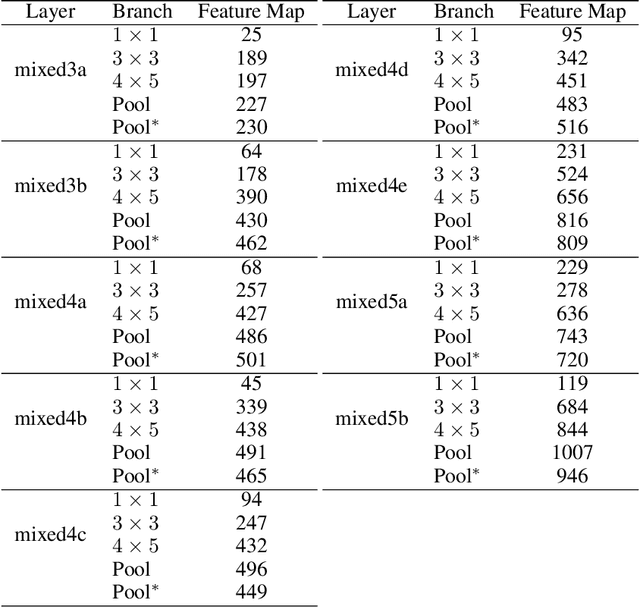
Feature visualizations such as synthetic maximally activating images are a widely used explanation method to better understand the information processing of convolutional neural networks (CNNs). At the same time, there are concerns that these visualizations might not accurately represent CNNs' inner workings. Here, we measure how much extremely activating images help humans to predict CNN activations. Using a well-controlled psychophysical paradigm, we compare the informativeness of synthetic images (Olah et al., 2017) with a simple baseline visualization, namely exemplary natural images that also strongly activate a specific feature map. Given either synthetic or natural reference images, human participants choose which of two query images leads to strong positive activation. The experiment is designed to maximize participants' performance, and is the first to probe intermediate instead of final layer representations. We find that synthetic images indeed provide helpful information about feature map activations (82% accuracy; chance would be 50%). However, natural images-originally intended to be a baseline-outperform synthetic images by a wide margin (92% accuracy). Additionally, participants are faster and more confident for natural images, whereas subjective impressions about the interpretability of feature visualization are mixed. The higher informativeness of natural images holds across most layers, for both expert and lay participants as well as for hand- and randomly-picked feature visualizations. Even if only a single reference image is given, synthetic images provide less information than natural images (65% vs. 73%). In summary, popular synthetic images from feature visualizations are significantly less informative for assessing CNN activations than natural images. We argue that future visualization methods should improve over this simple baseline.
The Notorious Difficulty of Comparing Human and Machine Perception
Apr 20, 2020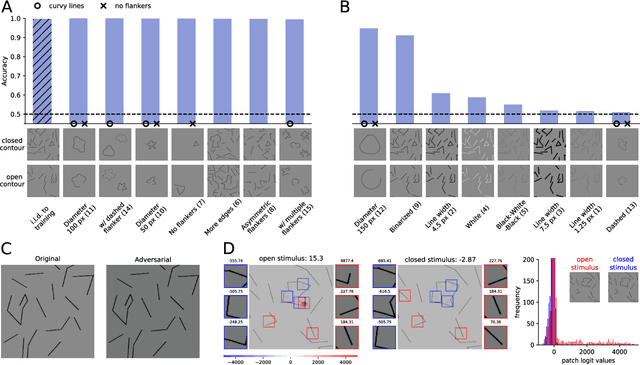


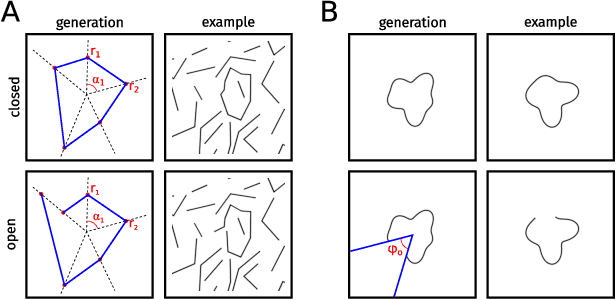
With the rise of machines to human-level performance in complex recognition tasks, a growing amount of work is directed towards comparing information processing in humans and machines. These works have the potential to deepen our understanding of the inner mechanisms of human perception and to improve machine learning. Drawing robust conclusions from comparison studies, however, turns out to be difficult. Here, we highlight common shortcomings that can easily lead to fragile conclusions. First, if a model does achieve high performance on a task similar to humans, its decision-making process is not necessarily human-like. Moreover, further analyses can reveal differences. Second, the performance of neural networks is sensitive to training procedures and architectural details. Thus, generalizing conclusions from specific architectures is difficult. Finally, when comparing humans and machines, equivalent experimental settings are crucial in order to identify innate differences. Addressing these shortcomings alters or refines the conclusions of studies. We show that, despite their ability to solve closed-contour tasks, our neural networks use different decision-making strategies than humans. We further show that there is no fundamental difference between same-different and spatial tasks for common feed-forward neural networks and finally, that neural networks do experience a "recognition gap" on minimal recognizable images. All in all, care has to be taken to not impose our human systematic bias when comparing human and machine perception.