 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAI Gym for Science: Training Liquid Foundation Models for Drug Discovery
Mar 03, 2026General-purpose large language models (LLMs) that rely on in-context learning do not reliably deliver the scientific understanding and performance required for drug discovery tasks. Simply increasing model size or introducing reasoning tokens does not yield significant performance gains. To address this gap, we introduce the MMAI Gym for Science, a one-stop shop molecular data formats and modalities as well as task-specific reasoning, training, and benchmarking recipes designed to teach foundation models the 'language of molecules' in order to solve practical drug discovery problems. We use MMAI Gym to train an efficient Liquid Foundation Model (LFM) for these applications, demonstrating that smaller, purpose-trained foundation models can outperform substantially larger general-purpose or specialist models on molecular benchmarks. Across essential drug discovery tasks - including molecular optimization, ADMET property prediction, retrosynthesis, drug-target activity prediction, and functional group reasoning - the resulting model achieves near specialist-level performance and, in the majority of settings, surpasses larger models, while remaining more efficient and broadly applicable in the domain.
Holistic Surgical Phase Recognition with Hierarchical Input Dependent State Space Models
Jun 26, 2025Surgical workflow analysis is essential in robot-assisted surgeries, yet the long duration of such procedures poses significant challenges for comprehensive video analysis. Recent approaches have predominantly relied on transformer models; however, their quadratic attention mechanism restricts efficient processing of lengthy surgical videos. In this paper, we propose a novel hierarchical input-dependent state space model that leverages the linear scaling property of state space models to enable decision making on full-length videos while capturing both local and global dynamics. Our framework incorporates a temporally consistent visual feature extractor, which appends a state space model head to a visual feature extractor to propagate temporal information. The proposed model consists of two key modules: a local-aggregation state space model block that effectively captures intricate local dynamics, and a global-relation state space model block that models temporal dependencies across the entire video. The model is trained using a hybrid discrete-continuous supervision strategy, where both signals of discrete phase labels and continuous phase progresses are propagated through the network. Experiments have shown that our method outperforms the current state-of-the-art methods by a large margin (+2.8% on Cholec80, +4.3% on MICCAI2016, and +12.9% on Heichole datasets). Code will be publicly available after paper acceptance.
State-Free Inference of State-Space Models: The Transfer Function Approach
May 10, 2024We approach designing a state-space model for deep learning applications through its dual representation, the transfer function, and uncover a highly efficient sequence parallel inference algorithm that is state-free: unlike other proposed algorithms, state-free inference does not incur any significant memory or computational cost with an increase in state size. We achieve this using properties of the proposed frequency domain transfer function parametrization, which enables direct computation of its corresponding convolutional kernel's spectrum via a single Fast Fourier Transform. Our experimental results across multiple sequence lengths and state sizes illustrates, on average, a 35% training speed improvement over S4 layers -- parametrized in time-domain -- on the Long Range Arena benchmark, while delivering state-of-the-art downstream performances over other attention-free approaches. Moreover, we report improved perplexity in language modeling over a long convolutional Hyena baseline, by simply introducing our transfer function parametrization. Our code is available at https://github.com/ruke1ire/RTF.
Compositional Policy Learning in Stochastic Control Systems with Formal Guarantees
Dec 03, 2023



Reinforcement learning has shown promising results in learning neural network policies for complicated control tasks. However, the lack of formal guarantees about the behavior of such policies remains an impediment to their deployment. We propose a novel method for learning a composition of neural network policies in stochastic environments, along with a formal certificate which guarantees that a specification over the policy's behavior is satisfied with the desired probability. Unlike prior work on verifiable RL, our approach leverages the compositional nature of logical specifications provided in SpectRL, to learn over graphs of probabilistic reach-avoid specifications. The formal guarantees are provided by learning neural network policies together with reach-avoid supermartingales (RASM) for the graph's sub-tasks and then composing them into a global policy. We also derive a tighter lower bound compared to previous work on the probability of reach-avoidance implied by a RASM, which is required to find a compositional policy with an acceptable probabilistic threshold for complex tasks with multiple edge policies. We implement a prototype of our approach and evaluate it on a Stochastic Nine Rooms environment.
Leveraging Low-Rank and Sparse Recurrent Connectivity for Robust Closed-Loop Control
Oct 05, 2023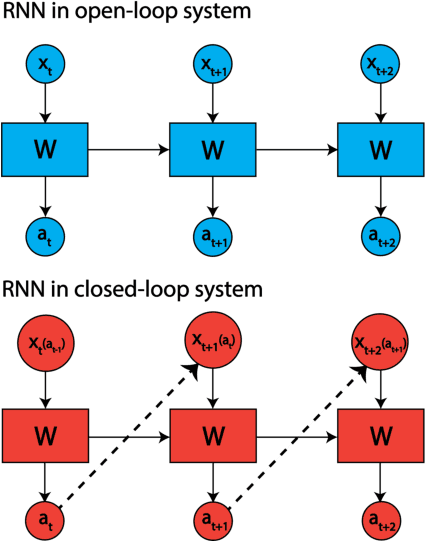

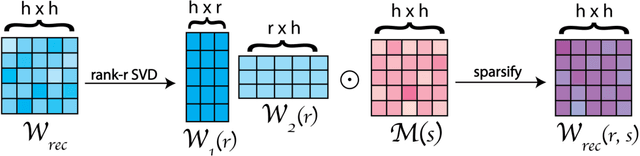

Developing autonomous agents that can interact with changing environments is an open challenge in machine learning. Robustness is particularly important in these settings as agents are often fit offline on expert demonstrations but deployed online where they must generalize to the closed feedback loop within the environment. In this work, we explore the application of recurrent neural networks to tasks of this nature and understand how a parameterization of their recurrent connectivity influences robustness in closed-loop settings. Specifically, we represent the recurrent connectivity as a function of rank and sparsity and show both theoretically and empirically that modulating these two variables has desirable effects on network dynamics. The proposed low-rank, sparse connectivity induces an interpretable prior on the network that proves to be most amenable for a class of models known as closed-form continuous-time neural networks (CfCs). We find that CfCs with fewer parameters can outperform their full-rank, fully-connected counterparts in the online setting under distribution shift. This yields memory-efficient and robust agents while opening a new perspective on how we can modulate network dynamics through connectivity.
On the Size and Approximation Error of Distilled Sets
May 23, 2023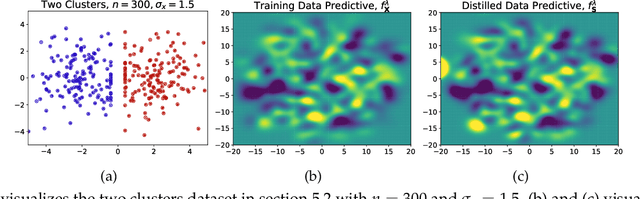
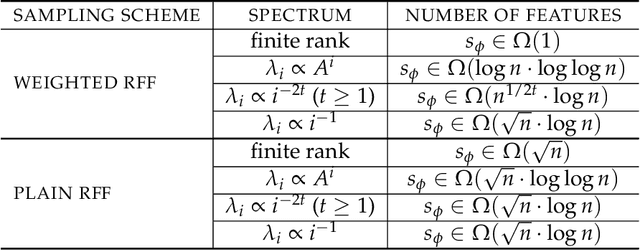
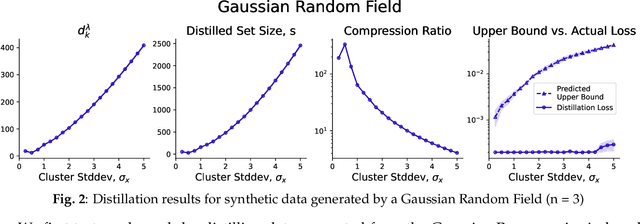
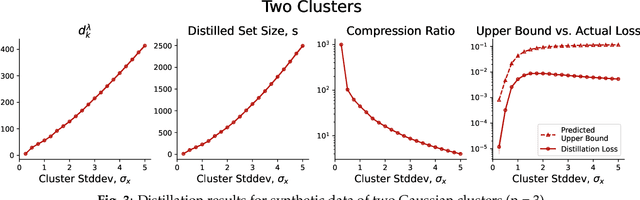
Dataset Distillation is the task of synthesizing small datasets from large ones while still retaining comparable predictive accuracy to the original uncompressed dataset. Despite significant empirical progress in recent years, there is little understanding of the theoretical limitations/guarantees of dataset distillation, specifically, what excess risk is achieved by distillation compared to the original dataset, and how large are distilled datasets? In this work, we take a theoretical view on kernel ridge regression (KRR) based methods of dataset distillation such as Kernel Inducing Points. By transforming ridge regression in random Fourier features (RFF) space, we provide the first proof of the existence of small (size) distilled datasets and their corresponding excess risk for shift-invariant kernels. We prove that a small set of instances exists in the original input space such that its solution in the RFF space coincides with the solution of the original data. We further show that a KRR solution can be generated using this distilled set of instances which gives an approximation towards the KRR solution optimized on the full input data. The size of this set is linear in the dimension of the RFF space of the input set or alternatively near linear in the number of effective degrees of freedom, which is a function of the kernel, number of datapoints, and the regularization parameter $\lambda$. The error bound of this distilled set is also a function of $\lambda$. We verify our bounds analytically and empirically.
Infrastructure-based End-to-End Learning and Prevention of Driver Failure
Mar 21, 2023



Intelligent intersection managers can improve safety by detecting dangerous drivers or failure modes in autonomous vehicles, warning oncoming vehicles as they approach an intersection. In this work, we present FailureNet, a recurrent neural network trained end-to-end on trajectories of both nominal and reckless drivers in a scaled miniature city. FailureNet observes the poses of vehicles as they approach an intersection and detects whether a failure is present in the autonomy stack, warning cross-traffic of potentially dangerous drivers. FailureNet can accurately identify control failures, upstream perception errors, and speeding drivers, distinguishing them from nominal driving. The network is trained and deployed with autonomous vehicles in the MiniCity. Compared to speed or frequency-based predictors, FailureNet's recurrent neural network structure provides improved predictive power, yielding upwards of 84% accuracy when deployed on hardware.
Dataset Distillation with Convexified Implicit Gradients
Feb 13, 2023We propose a new dataset distillation algorithm using reparameterization and convexification of implicit gradients (RCIG), that substantially improves the state-of-the-art. To this end, we first formulate dataset distillation as a bi-level optimization problem. Then, we show how implicit gradients can be effectively used to compute meta-gradient updates. We further equip the algorithm with a convexified approximation that corresponds to learning on top of a frozen finite-width neural tangent kernel. Finally, we improve bias in implicit gradients by parameterizing the neural network to enable analytical computation of final-layer parameters given the body parameters. RCIG establishes the new state-of-the-art on a diverse series of dataset distillation tasks. Notably, with one image per class, on resized ImageNet, RCIG sees on average a 108% improvement over the previous state-of-the-art distillation algorithm. Similarly, we observed a 66% gain over SOTA on Tiny-ImageNet and 37% on CIFAR-100.
Dataset Distillation Fixes Dataset Reconstruction Attacks
Feb 02, 2023

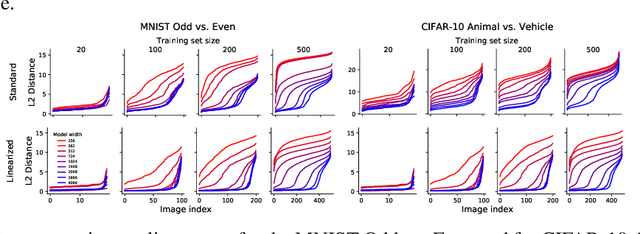
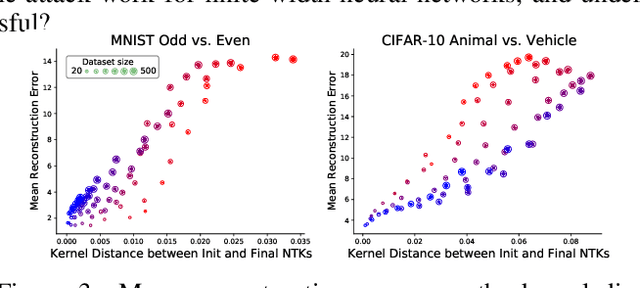
Modern deep learning requires large volumes of data, which could contain sensitive or private information which cannot be leaked. Recent work has shown for homogeneous neural networks a large portion of this training data could be reconstructed with only access to the trained network parameters. While the attack was shown to work empirically, there exists little formal understanding of its effectiveness regime, and ways to defend against it. In this work, we first build a stronger version of the dataset reconstruction attack and show how it can provably recover its entire training set in the infinite width regime. We then empirically study the characteristics of this attack on two-layer networks and reveal that its success heavily depends on deviations from the frozen infinite-width Neural Tangent Kernel limit. More importantly, we formally show for the first time that dataset reconstruction attacks are a variation of dataset distillation. This key theoretical result on the unification of dataset reconstruction and distillation not only sheds more light on the characteristics of the attack but enables us to design defense mechanisms against them via distillation algorithms.
Cooperative Flight Control Using Visual-Attention -- Air-Guardian
Dec 21, 2022



The cooperation of a human pilot with an autonomous agent during flight control realizes parallel autonomy. A parallel-autonomous system acts as a guardian that significantly enhances the robustness and safety of flight operations in challenging circumstances. Here, we propose an air-guardian concept that facilitates cooperation between an artificial pilot agent and a parallel end-to-end neural control system. Our vision-based air-guardian system combines a causal continuous-depth neural network model with a cooperation layer to enable parallel autonomy between a pilot agent and a control system based on perceived differences in their attention profile. The attention profiles are obtained by computing the networks' saliency maps (feature importance) through the VisualBackProp algorithm. The guardian agent is trained via reinforcement learning in a fixed-wing aircraft simulated environment. When the attention profile of the pilot and guardian agents align, the pilot makes control decisions. If the attention map of the pilot and the guardian do not align, the air-guardian makes interventions and takes over the control of the aircraft. We show that our attention-based air-guardian system can balance the trade-off between its level of involvement in the flight and the pilot's expertise and attention. We demonstrate the effectivness of our methods in simulated flight scenarios with a fixed-wing aircraft and on a real drone platform.