 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee Less, Drive Better: Generalizable End-to-End Autonomous Driving via Foundation Models Stochastic Patch Selection
Jan 15, 2026Recent advances in end-to-end autonomous driving show that policies trained on patch-aligned features extracted from foundation models generalize better to Out-of-Distribution (OOD). We hypothesize that due to the self-attention mechanism, each patch feature implicitly embeds/contains information from all other patches, represented in a different way and intensity, making these descriptors highly redundant. We quantify redundancy in such (BLIP2) features via PCA and cross-patch similarity: $90$% of variance is captured by $17/64$ principal components, and strong inter-token correlations are pervasive. Training on such overlapping information leads the policy to overfit spurious correlations, hurting OOD robustness. We present Stochastic-Patch-Selection (SPS), a simple yet effective approach for learning policies that are more robust, generalizable, and efficient. For every frame, SPS randomly masks a fraction of patch descriptors, not feeding them to the policy model, while preserving the spatial layout of the remaining patches. Thus, the policy is provided with different stochastic but complete views of the (same) scene: every random subset of patches acts like a different, yet still sensible, coherent projection of the world. The policy thus bases its decisions on features that are invariant to which specific tokens survive. Extensive experiments confirm that across all OOD scenarios, our method outperforms the state of the art (SOTA), achieving a $6.2$% average improvement and up to $20.4$% in closed-loop simulations, while being $2.4\times$ faster. We conduct ablations over masking rates and patch-feature reorganization, training and evaluating 9 systems, with 8 of them surpassing prior SOTA. Finally, we show that the same learned policy transfers to a physical, real-world car without any tuning.
SAFe-Copilot: Unified Shared Autonomy Framework
Nov 06, 2025Autonomous driving systems remain brittle in rare, ambiguous, and out-of-distribution scenarios, where human driver succeed through contextual reasoning. Shared autonomy has emerged as a promising approach to mitigate such failures by incorporating human input when autonomy is uncertain. However, most existing methods restrict arbitration to low-level trajectories, which represent only geometric paths and therefore fail to preserve the underlying driving intent. We propose a unified shared autonomy framework that integrates human input and autonomous planners at a higher level of abstraction. Our method leverages Vision Language Models (VLMs) to infer driver intent from multi-modal cues -- such as driver actions and environmental context -- and to synthesize coherent strategies that mediate between human and autonomous control. We first study the framework in a mock-human setting, where it achieves perfect recall alongside high accuracy and precision. A human-subject survey further shows strong alignment, with participants agreeing with arbitration outcomes in 92% of cases. Finally, evaluation on the Bench2Drive benchmark demonstrates a substantial reduction in collision rate and improvement in overall performance compared to pure autonomy. Arbitration at the level of semantic, language-based representations emerges as a design principle for shared autonomy, enabling systems to exercise common-sense reasoning and maintain continuity with human intent.
Compress to Impress: Efficient LLM Adaptation Using a Single Gradient Step on 100 Samples
Oct 23, 2025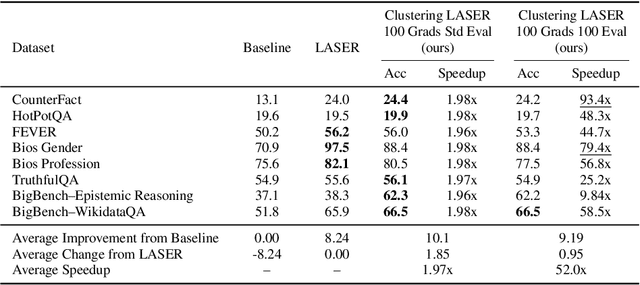
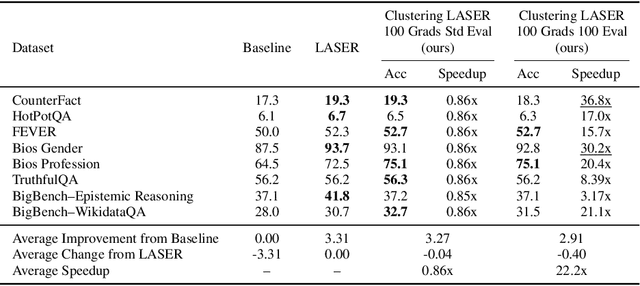
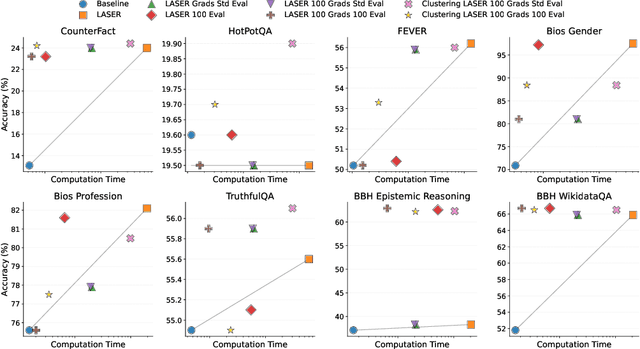
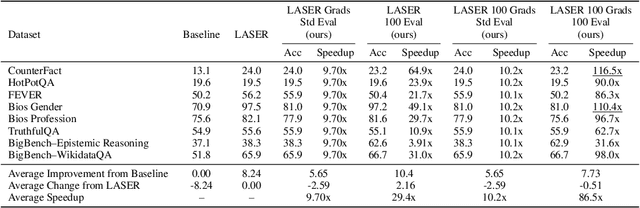
Recently, Sharma et al. suggested a method called Layer-SElective-Rank reduction (LASER) which demonstrated that pruning high-order components of carefully chosen LLM's weight matrices can boost downstream accuracy -- without any gradient-based fine-tuning. Yet LASER's exhaustive, per-matrix search (each requiring full-dataset forward passes) makes it impractical for rapid deployment. We demonstrate that this overhead can be removed and find that: (i) Only a small, carefully chosen subset of matrices needs to be inspected -- eliminating the layer-by-layer sweep, (ii) The gradient of each matrix's singular values pinpoints which matrices merit reduction, (iii) Increasing the factorization search space by allowing matrices rows to cluster around multiple subspaces and then decomposing each cluster separately further reduces overfitting on the original training data and further lifts accuracy by up to 24.6 percentage points, and finally, (iv) we discover that evaluating on just 100 samples rather than the full training data -- both for computing the indicative gradients and for measuring the final accuracy -- suffices to further reduce the search time; we explain that as adaptation to downstream tasks is dominated by prompting style, not dataset size. As a result, we show that combining these findings yields a fast and robust adaptation algorithm for downstream tasks. Overall, with a single gradient step on 100 examples and a quick scan of the top candidate layers and factorization techniques, we can adapt LLMs to new datasets -- entirely without fine-tuning.
Generating Out-Of-Distribution Scenarios Using Language Models
Nov 25, 2024
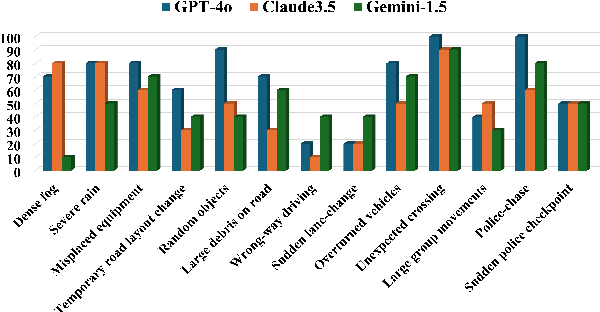
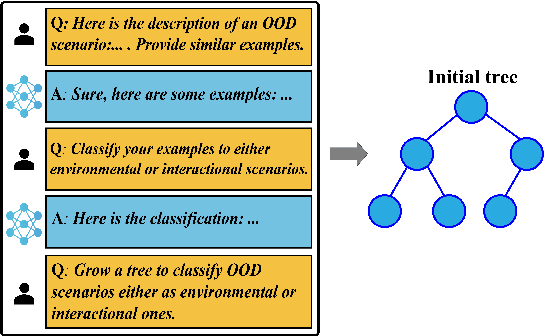
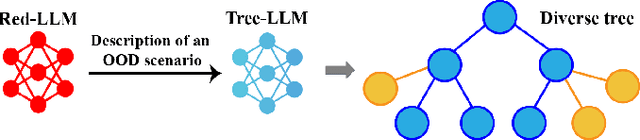
The deployment of autonomous vehicles controlled by machine learning techniques requires extensive testing in diverse real-world environments, robust handling of edge cases and out-of-distribution scenarios, and comprehensive safety validation to ensure that these systems can navigate safely and effectively under unpredictable conditions. Addressing Out-Of-Distribution (OOD) driving scenarios is essential for enhancing safety, as OOD scenarios help validate the reliability of the models within the vehicle's autonomy stack. However, generating OOD scenarios is challenging due to their long-tailed distribution and rarity in urban driving dataset. Recently, Large Language Models (LLMs) have shown promise in autonomous driving, particularly for their zero-shot generalization and common-sense reasoning capabilities. In this paper, we leverage these LLM strengths to introduce a framework for generating diverse OOD driving scenarios. Our approach uses LLMs to construct a branching tree, where each branch represents a unique OOD scenario. These scenarios are then simulated in the CARLA simulator using an automated framework that aligns scene augmentation with the corresponding textual descriptions. We evaluate our framework through extensive simulations, and assess its performance via a diversity metric that measures the richness of the scenarios. Additionally, we introduce a new "OOD-ness" metric, which quantifies how much the generated scenarios deviate from typical urban driving conditions. Furthermore, we explore the capacity of modern Vision-Language Models (VLMs) to interpret and safely navigate through the simulated OOD scenarios. Our findings offer valuable insights into the reliability of language models in addressing OOD scenarios within the context of urban driving.
Probing Multimodal LLMs as World Models for Driving
May 09, 2024



We provide a sober look at the application of Multimodal Large Language Models (MLLMs) within the domain of autonomous driving and challenge/verify some common assumptions, focusing on their ability to reason and interpret dynamic driving scenarios through sequences of images/frames in a closed-loop control environment. Despite the significant advancements in MLLMs like GPT-4V, their performance in complex, dynamic driving environments remains largely untested and presents a wide area of exploration. We conduct a comprehensive experimental study to evaluate the capability of various MLLMs as world models for driving from the perspective of a fixed in-car camera. Our findings reveal that, while these models proficiently interpret individual images, they struggle significantly with synthesizing coherent narratives or logical sequences across frames depicting dynamic behavior. The experiments demonstrate considerable inaccuracies in predicting (i) basic vehicle dynamics (forward/backward, acceleration/deceleration, turning right or left), (ii) interactions with other road actors (e.g., identifying speeding cars or heavy traffic), (iii) trajectory planning, and (iv) open-set dynamic scene reasoning, suggesting biases in the models' training data. To enable this experimental study we introduce a specialized simulator, DriveSim, designed to generate diverse driving scenarios, providing a platform for evaluating MLLMs in the realms of driving. Additionally, we contribute the full open-source code and a new dataset, "Eval-LLM-Drive", for evaluating MLLMs in driving. Our results highlight a critical gap in the current capabilities of state-of-the-art MLLMs, underscoring the need for enhanced foundation models to improve their applicability in real-world dynamic environments.
Infrastructure-based End-to-End Learning and Prevention of Driver Failure
Mar 21, 2023



Intelligent intersection managers can improve safety by detecting dangerous drivers or failure modes in autonomous vehicles, warning oncoming vehicles as they approach an intersection. In this work, we present FailureNet, a recurrent neural network trained end-to-end on trajectories of both nominal and reckless drivers in a scaled miniature city. FailureNet observes the poses of vehicles as they approach an intersection and detects whether a failure is present in the autonomy stack, warning cross-traffic of potentially dangerous drivers. FailureNet can accurately identify control failures, upstream perception errors, and speeding drivers, distinguishing them from nominal driving. The network is trained and deployed with autonomous vehicles in the MiniCity. Compared to speed or frequency-based predictors, FailureNet's recurrent neural network structure provides improved predictive power, yielding upwards of 84% accuracy when deployed on hardware.