 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGleanmer: A 6 mW SoC for Real-Time 3D Gaussian Occupancy Mapping
Mar 30, 2026High-fidelity 3D occupancy mapping is essential for many edge-based applications (such as AR/VR and autonomous navigation) but is limited by power constraints. We present Gleanmer, a system on chip (SoC) with an accelerator for GMMap, a 3D occupancy map using Gaussians. Through algorithm-hardware co-optimizations for direct computation and efficient reuse of these compact Gaussians, Gleanmer reduces construction and query energy by up to 63% and 81%, respectively. Approximate computation on Gaussians reduces accelerator area by 38%. Using 16nm CMOS, Gleanmer processes 640x480 images in real time beyond 88 fps during map construction and processes over 540K coordinates per second during map query. To our knowledge, Gleanmer is the first fabricated SoC to achieve real-time 3D occupancy mapping under 6 mW for edge-based applications.
Flow Matching with Uncertainty Quantification and Guidance
Feb 10, 2026Despite the remarkable success of sampling-based generative models such as flow matching, they can still produce samples of inconsistent or degraded quality. To assess sample reliability and generate higher-quality outputs, we propose uncertainty-aware flow matching (UA-Flow), a lightweight extension of flow matching that predicts the velocity field together with heteroscedastic uncertainty. UA-Flow estimates per-sample uncertainty by propagating velocity uncertainty through the flow dynamics. These uncertainty estimates act as a reliability signal for individual samples, and we further use them to steer generation via uncertainty-aware classifier guidance and classifier-free guidance. Experiments on image generation show that UA-Flow produces uncertainty signals more highly correlated with sample fidelity than baseline methods, and that uncertainty-guided sampling further improves generation quality.
SAFe-Copilot: Unified Shared Autonomy Framework
Nov 06, 2025Autonomous driving systems remain brittle in rare, ambiguous, and out-of-distribution scenarios, where human driver succeed through contextual reasoning. Shared autonomy has emerged as a promising approach to mitigate such failures by incorporating human input when autonomy is uncertain. However, most existing methods restrict arbitration to low-level trajectories, which represent only geometric paths and therefore fail to preserve the underlying driving intent. We propose a unified shared autonomy framework that integrates human input and autonomous planners at a higher level of abstraction. Our method leverages Vision Language Models (VLMs) to infer driver intent from multi-modal cues -- such as driver actions and environmental context -- and to synthesize coherent strategies that mediate between human and autonomous control. We first study the framework in a mock-human setting, where it achieves perfect recall alongside high accuracy and precision. A human-subject survey further shows strong alignment, with participants agreeing with arbitration outcomes in 92% of cases. Finally, evaluation on the Bench2Drive benchmark demonstrates a substantial reduction in collision rate and improvement in overall performance compared to pure autonomy. Arbitration at the level of semantic, language-based representations emerges as a design principle for shared autonomy, enabling systems to exercise common-sense reasoning and maintain continuity with human intent.
ReGen: Generative Robot Simulation via Inverse Design
Nov 06, 2025Simulation plays a key role in scaling robot learning and validating policies, but constructing simulations remains a labor-intensive process. This paper introduces ReGen, a generative simulation framework that automates simulation design via inverse design. Given a robot's behavior -- such as a motion trajectory or an objective function -- and its textual description, ReGen infers plausible scenarios and environments that could have caused the behavior. ReGen leverages large language models to synthesize scenarios by expanding a directed graph that encodes cause-and-effect relationships, relevant entities, and their properties. This structured graph is then translated into a symbolic program, which configures and executes a robot simulation environment. Our framework supports (i) augmenting simulations based on ego-agent behaviors, (ii) controllable, counterfactual scenario generation, (iii) reasoning about agent cognition and mental states, and (iv) reasoning with distinct sensing modalities, such as braking due to faulty GPS signals. We demonstrate ReGen in autonomous driving and robot manipulation tasks, generating more diverse, complex simulated environments compared to existing simulations with high success rates, and enabling controllable generation for corner cases. This approach enhances the validation of robot policies and supports data or simulation augmentation, advancing scalable robot learning for improved generalization and robustness. We provide code and example videos at: https://regen-sim.github.io/
SCREP: Scene Coordinate Regression and Evidential Learning-based Perception-Aware Trajectory Generation
Jul 10, 2025Autonomous flight in GPS denied indoor spaces requires trajectories that keep visual localization error tightly bounded across varied missions. Whereas visual inertial odometry (VIO) accumulates drift over time, scene coordinate regression (SCR) yields drift-free, high accuracy absolute pose estimation. We present a perception-aware framework that couples an evidential learning-based SCR pose estimator with a receding horizon trajectory optimizer. The optimizer steers the onboard camera toward pixels whose uncertainty predicts reliable scene coordinates, while a fixed-lag smoother fuses the low rate SCR stream with high rate IMU data to close the perception control loop in real time. In simulation, our planner reduces translation (rotation) mean error by 54% / 15% (40% / 31%) relative to yaw fixed and forward-looking baselines, respectively. Moreover, hardware in the loop experiment validates the feasibility of our proposed framework.
Real-Time Sampling-based Online Planning for Drone Interception
Feb 20, 2025This paper studies high-speed online planning in dynamic environments. The problem requires finding time-optimal trajectories that conform to system dynamics, meeting computational constraints for real-time adaptation, and accounting for uncertainty from environmental changes. To address these challenges, we propose a sampling-based online planning algorithm that leverages neural network inference to replace time-consuming nonlinear trajectory optimization, enabling rapid exploration of multiple trajectory options under uncertainty. The proposed method is applied to the drone interception problem, where a defense drone must intercept a target while avoiding collisions and handling imperfect target predictions. The algorithm efficiently generates trajectories toward multiple potential target drone positions in parallel. It then assesses trajectory reachability by comparing traversal times with the target drone's predicted arrival time, ultimately selecting the minimum-time reachable trajectory. Through extensive validation in both simulated and real-world environments, we demonstrate our method's capability for high-rate online planning and its adaptability to unpredictable movements in unstructured settings.
Generating Out-Of-Distribution Scenarios Using Language Models
Nov 25, 2024
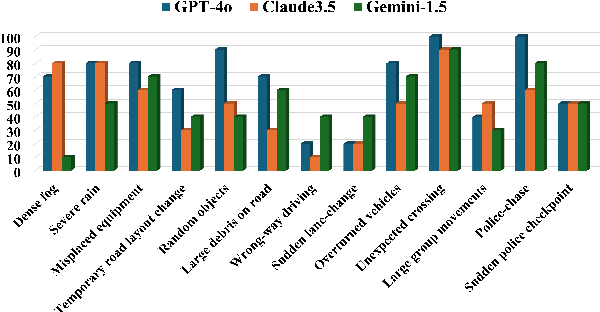
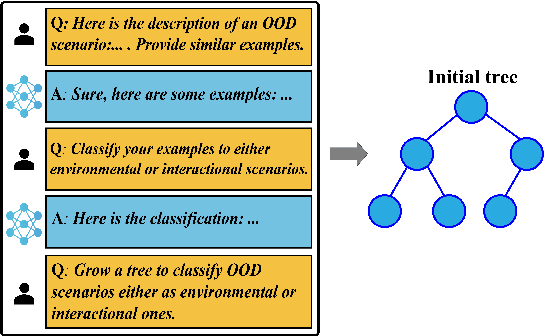
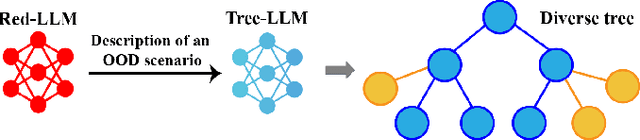
The deployment of autonomous vehicles controlled by machine learning techniques requires extensive testing in diverse real-world environments, robust handling of edge cases and out-of-distribution scenarios, and comprehensive safety validation to ensure that these systems can navigate safely and effectively under unpredictable conditions. Addressing Out-Of-Distribution (OOD) driving scenarios is essential for enhancing safety, as OOD scenarios help validate the reliability of the models within the vehicle's autonomy stack. However, generating OOD scenarios is challenging due to their long-tailed distribution and rarity in urban driving dataset. Recently, Large Language Models (LLMs) have shown promise in autonomous driving, particularly for their zero-shot generalization and common-sense reasoning capabilities. In this paper, we leverage these LLM strengths to introduce a framework for generating diverse OOD driving scenarios. Our approach uses LLMs to construct a branching tree, where each branch represents a unique OOD scenario. These scenarios are then simulated in the CARLA simulator using an automated framework that aligns scene augmentation with the corresponding textual descriptions. We evaluate our framework through extensive simulations, and assess its performance via a diversity metric that measures the richness of the scenarios. Additionally, we introduce a new "OOD-ness" metric, which quantifies how much the generated scenarios deviate from typical urban driving conditions. Furthermore, we explore the capacity of modern Vision-Language Models (VLMs) to interpret and safely navigate through the simulated OOD scenarios. Our findings offer valuable insights into the reliability of language models in addressing OOD scenarios within the context of urban driving.
Learning autonomous driving from aerial imagery
Oct 18, 2024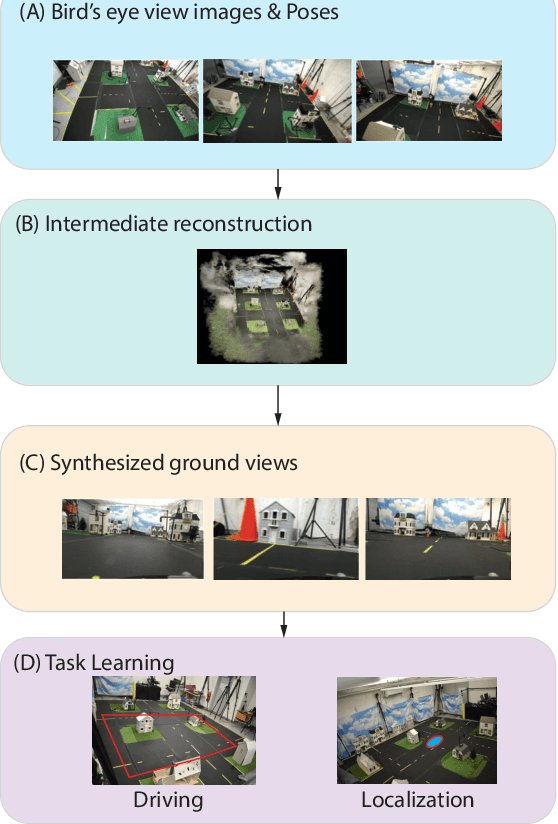
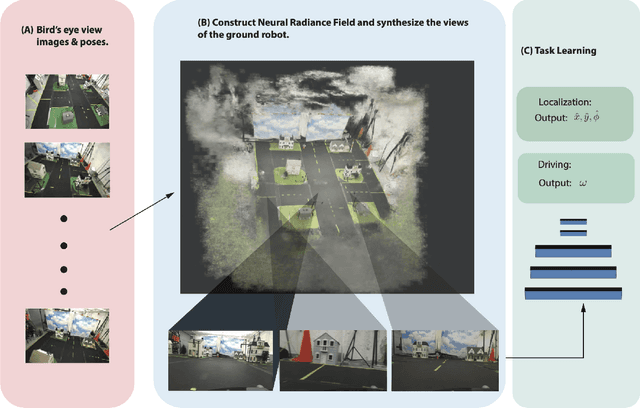
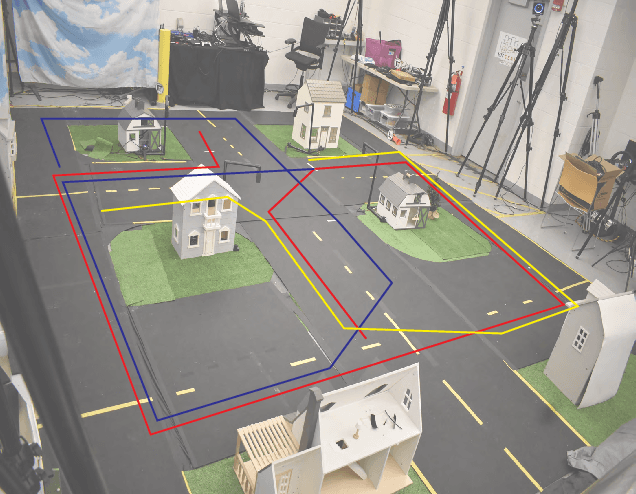

In this work, we consider the problem of learning end to end perception to control for ground vehicles solely from aerial imagery. Photogrammetric simulators allow the synthesis of novel views through the transformation of pre-generated assets into novel views.However, they have a large setup cost, require careful collection of data and often human effort to create usable simulators. We use a Neural Radiance Field (NeRF) as an intermediate representation to synthesize novel views from the point of view of a ground vehicle. These novel viewpoints can then be used for several downstream autonomous navigation applications. In this work, we demonstrate the utility of novel view synthesis though the application of training a policy for end to end learning from images and depth data. In a traditional real to sim to real framework, the collected data would be transformed into a visual simulator which could then be used to generate novel views. In contrast, using a NeRF allows a compact representation and the ability to optimize over the parameters of the visual simulator as more data is gathered in the environment. We demonstrate the efficacy of our method in a custom built mini-city environment through the deployment of imitation policies on robotic cars. We additionally consider the task of place localization and demonstrate that our method is able to relocalize the car in the real world.
DecTrain: Deciding When to Train a DNN Online
Oct 03, 2024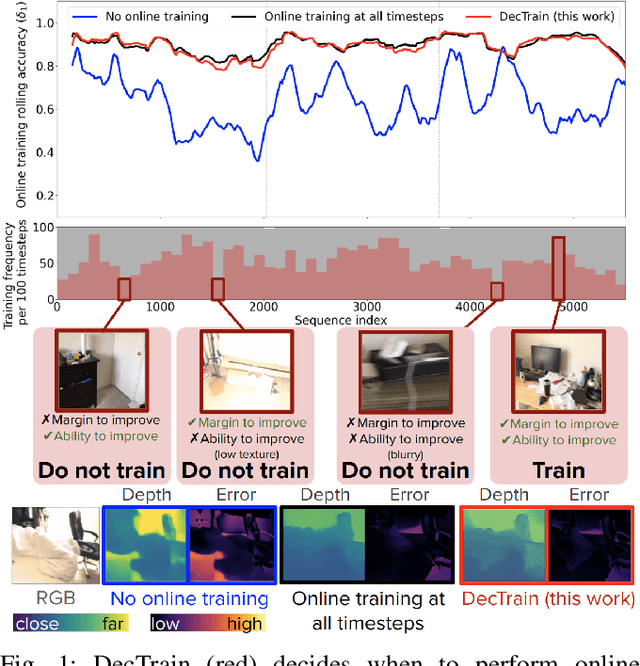
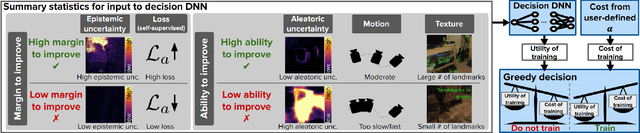


Deep neural networks (DNNs) can deteriorate in accuracy when deployment data differs from training data. While performing online training at all timesteps can improve accuracy, it is computationally expensive. We propose DecTrain, a new algorithm that decides when to train a monocular depth DNN online using self-supervision with low overhead. To make the decision at each timestep, DecTrain compares the cost of training with the predicted accuracy gain. We evaluate DecTrain on out-of-distribution data, and find DecTrain maintains accuracy compared to online training at all timesteps, while training only 44% of the time on average. We also compare the recovery of a low inference cost DNN using DecTrain and a more generalizable high inference cost DNN on various sequences. DecTrain recovers the majority (97%) of the accuracy gain of online training at all timesteps while reducing computation compared to the high inference cost DNN which recovers only 66%. With an even smaller DNN, we achieve 89% recovery while reducing computation by 56%. DecTrain enables low-cost online training for a smaller DNN to have competitive accuracy with a larger, more generalizable DNN at a lower overall computational cost.
GEVO: Memory-Efficient Monocular Visual Odometry Using Gaussians
Sep 14, 2024Constructing a high-fidelity representation of the 3D scene using a monocular camera can enable a wide range of applications on mobile devices, such as micro-robots, smartphones, and AR/VR headsets. On these devices, memory is often limited in capacity and its access often dominates the consumption of compute energy. Although Gaussian Splatting (GS) allows for high-fidelity reconstruction of 3D scenes, current GS-based SLAM is not memory efficient as a large number of past images is stored to retrain Gaussians for reducing catastrophic forgetting. These images often require two-orders-of-magnitude higher memory than the map itself and thus dominate the total memory usage. In this work, we present GEVO, a GS-based monocular SLAM framework that achieves comparable fidelity as prior methods by rendering (instead of storing) them from the existing map. Novel Gaussian initialization and optimization techniques are proposed to remove artifacts from the map and delay the degradation of the rendered images over time. Across a variety of environments, GEVO achieves comparable map fidelity while reducing the memory overhead to around 58 MBs, which is up to 94x lower than prior works.