 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGleanmer: A 6 mW SoC for Real-Time 3D Gaussian Occupancy Mapping
Mar 30, 2026High-fidelity 3D occupancy mapping is essential for many edge-based applications (such as AR/VR and autonomous navigation) but is limited by power constraints. We present Gleanmer, a system on chip (SoC) with an accelerator for GMMap, a 3D occupancy map using Gaussians. Through algorithm-hardware co-optimizations for direct computation and efficient reuse of these compact Gaussians, Gleanmer reduces construction and query energy by up to 63% and 81%, respectively. Approximate computation on Gaussians reduces accelerator area by 38%. Using 16nm CMOS, Gleanmer processes 640x480 images in real time beyond 88 fps during map construction and processes over 540K coordinates per second during map query. To our knowledge, Gleanmer is the first fabricated SoC to achieve real-time 3D occupancy mapping under 6 mW for edge-based applications.
GEVO: Memory-Efficient Monocular Visual Odometry Using Gaussians
Sep 14, 2024Constructing a high-fidelity representation of the 3D scene using a monocular camera can enable a wide range of applications on mobile devices, such as micro-robots, smartphones, and AR/VR headsets. On these devices, memory is often limited in capacity and its access often dominates the consumption of compute energy. Although Gaussian Splatting (GS) allows for high-fidelity reconstruction of 3D scenes, current GS-based SLAM is not memory efficient as a large number of past images is stored to retrain Gaussians for reducing catastrophic forgetting. These images often require two-orders-of-magnitude higher memory than the map itself and thus dominate the total memory usage. In this work, we present GEVO, a GS-based monocular SLAM framework that achieves comparable fidelity as prior methods by rendering (instead of storing) them from the existing map. Novel Gaussian initialization and optimization techniques are proposed to remove artifacts from the map and delay the degradation of the rendered images over time. Across a variety of environments, GEVO achieves comparable map fidelity while reducing the memory overhead to around 58 MBs, which is up to 94x lower than prior works.
GMMap: Memory-Efficient Continuous Occupancy Map Using Gaussian Mixture Model
Jun 06, 2023Energy consumption of memory accesses dominates the compute energy in energy-constrained robots which require a compact 3D map of the environment to achieve autonomy. Recent mapping frameworks only focused on reducing the map size while incurring significant memory usage during map construction due to multi-pass processing of each depth image. In this work, we present a memory-efficient continuous occupancy map, named GMMap, that accurately models the 3D environment using a Gaussian Mixture Model (GMM). Memory-efficient GMMap construction is enabled by the single-pass compression of depth images into local GMMs which are directly fused together into a globally-consistent map. By extending Gaussian Mixture Regression to model unexplored regions, occupancy probability is directly computed from Gaussians. Using a low-power ARM Cortex A57 CPU, GMMap can be constructed in real-time at up to 60 images per second. Compared with prior works, GMMap maintains high accuracy while reducing the map size by at least 56%, memory overhead by at least 88%, DRAM access by at least 78%, and energy consumption by at least 69%. Thus, GMMap enables real-time 3D mapping on energy-constrained robots.
Efficient Computation of Map-scale Continuous Mutual Information on Chip in Real Time
Oct 07, 2022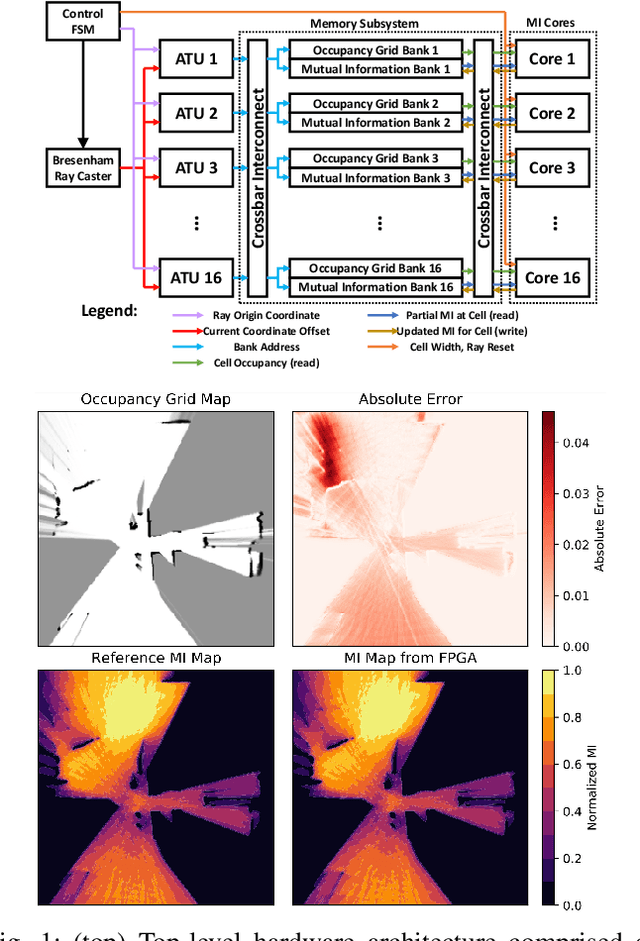
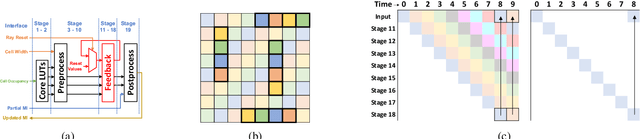
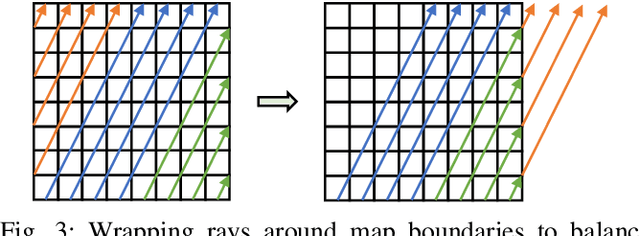
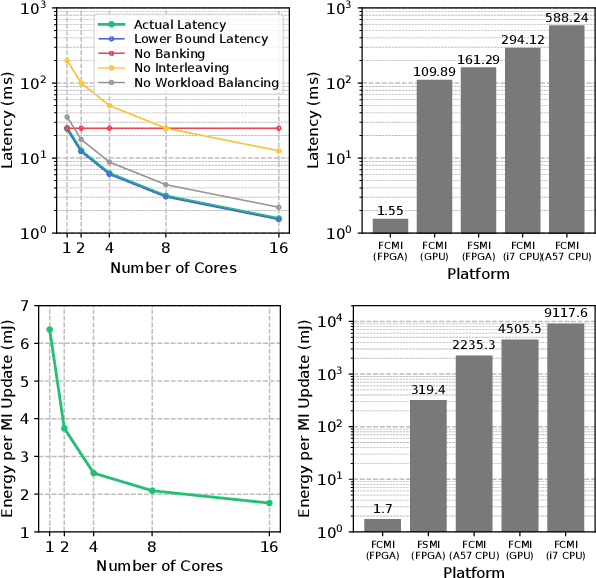
Exploration tasks are essential to many emerging robotics applications, ranging from search and rescue to space exploration. The planning problem for exploration requires determining the best locations for future measurements that will enhance the fidelity of the map, for example, by reducing its total entropy. A widely-studied technique involves computing the Mutual Information (MI) between the current map and future measurements, and utilizing this MI metric to decide the locations for future measurements. However, computing MI for reasonably-sized maps is slow and power hungry, which has been a bottleneck towards fast and efficient robotic exploration. In this paper, we introduce a new hardware accelerator architecture for MI computation that features a low-latency, energy-efficient MI compute core and an optimized memory subsystem that provides sufficient bandwidth to keep the cores fully utilized. The core employs interleaving to counter the recursive algorithm, and workload balancing and numerical approximations to reduce latency and energy consumption. We demonstrate this optimized architecture with a Field-Programmable Gate Array (FPGA) implementation, which can compute MI for all cells in an entire 201-by-201 occupancy grid ({\em e.g.}, representing a 20.1m-by-20.1m map at 0.1m resolution) in 1.55 ms while consuming 1.7 mJ of energy, thus finally rendering MI computation for the whole map real time and at a fraction of the energy cost of traditional compute platforms. For comparison, this particular FPGA implementation running on the Xilinx Zynq-7000 platform is two orders of magnitude faster and consumes three orders of magnitude less energy per MI map compute, when compared to a baseline GPU implementation running on an NVIDIA GeForce GTX 980 platform. The improvements are more pronounced when compared to CPU implementations of equivalent algorithms.