 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNERFIFY: A Multi-Agent Framework for Turning NeRF Papers into Code
Feb 28, 2026The proliferation of neural radiance field (NeRF) research requires significant efforts to reimplement papers before building upon them. We introduce NERFIFY, a multi-agent framework that reliably converts NeRF research papers into trainable Nerfstudio plugins, in contrast to generic paper-to-code methods and frontier models like GPT-5 that usually fail to produce runnable code. NERFIFY achieves domain-specific executability through six key innovations: (1) Context-free grammar (CFG): LLM synthesis is constrained by Nerfstudio formalized as a CFG, ensuring generated code satisfies architectural invariants. (2) Graph-of-Thought code synthesis: Specialized multi-file-agents generate repositories in topological dependency order, validating contracts and errors at each node. (3) Compositional citation recovery: Agents automatically retrieve and integrate components (samplers, encoders, proposal networks) from citation graphs of references. (4) Visual feedback: Artifacts are diagnosed through PSNR-minima ROI analysis, cross-view geometric validation, and VLM-guided patching to iteratively improve quality. (5) Knowledge enhancement: Beyond reproduction, methods can be improved with novel optimizations. (6) Benchmarking: An evaluation framework is designed for NeRF paper-to-code synthesis across 30 diverse papers. On papers without public implementations, NERFIFY achieves visual quality matching expert human code (+/-0.5 dB PSNR, +/-0.2 SSIM) while reducing implementation time from weeks to minutes. NERFIFY demonstrates that a domain-aware design enables code translation for complex vision papers, potentiating accelerated and democratized reproducible research. Code, data and implementations will be publicly released.
SymGS : Leveraging Local Symmetries for 3D Gaussian Splatting Compression
Nov 19, 2025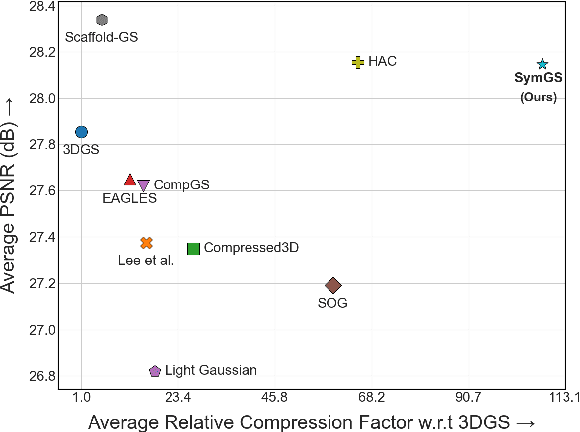



3D Gaussian Splatting has emerged as a transformative technique in novel view synthesis, primarily due to its high rendering speed and photorealistic fidelity. However, its memory footprint scales rapidly with scene complexity, often reaching several gigabytes. Existing methods address this issue by introducing compression strategies that exploit primitive-level redundancy through similarity detection and quantization. We aim to surpass the compression limits of such methods by incorporating symmetry-aware techniques, specifically targeting mirror symmetries to eliminate redundant primitives. We propose a novel compression framework, SymGS, introducing learnable mirrors into the scene, thereby eliminating local and global reflective redundancies for compression. Our framework functions as a plug-and-play enhancement to state-of-the-art compression methods, (e.g. HAC) to achieve further compression. Compared to HAC, we achieve $1.66 \times$ compression across benchmark datasets (upto $3\times$ on large-scale scenes). On an average, SymGS enables $\bf{108\times}$ compression of a 3DGS scene, while preserving rendering quality. The project page and supplementary can be found at symgs.github.io
Large Language Models Acing Chartered Accountancy
Jun 26, 2025Advanced intelligent systems, particularly Large Language Models (LLMs), are significantly reshaping financial practices through advancements in Natural Language Processing (NLP). However, the extent to which these models effectively capture and apply domain-specific financial knowledge remains uncertain. Addressing a critical gap in the expansive Indian financial context, this paper introduces CA-Ben, a Chartered Accountancy benchmark specifically designed to evaluate the financial, legal, and quantitative reasoning capabilities of LLMs. CA-Ben comprises structured question-answer datasets derived from the rigorous examinations conducted by the Institute of Chartered Accountants of India (ICAI), spanning foundational, intermediate, and advanced CA curriculum stages. Six prominent LLMs i.e. GPT 4o, LLAMA 3.3 70B, LLAMA 3.1 405B, MISTRAL Large, Claude 3.5 Sonnet, and Microsoft Phi 4 were evaluated using standardized protocols. Results indicate variations in performance, with Claude 3.5 Sonnet and GPT-4o outperforming others, especially in conceptual and legal reasoning. Notable challenges emerged in numerical computations and legal interpretations. The findings emphasize the strengths and limitations of current LLMs, suggesting future improvements through hybrid reasoning and retrieval-augmented generation methods, particularly for quantitative analysis and accurate legal interpretation.
Domain Generalization In Robust Invariant Representation
Apr 07, 2023
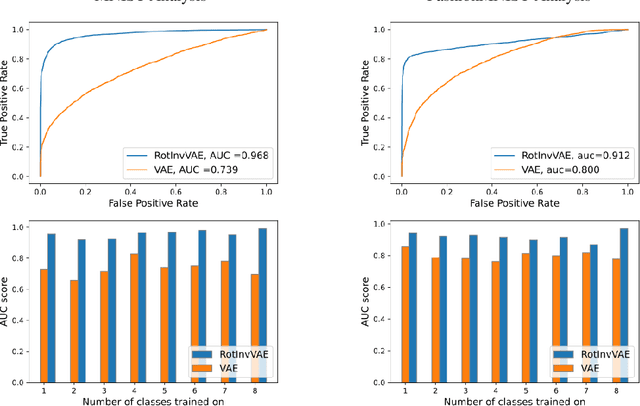


Unsupervised approaches for learning representations invariant to common transformations are used quite often for object recognition. Learning invariances makes models more robust and practical to use in real-world scenarios. Since data transformations that do not change the intrinsic properties of the object cause the majority of the complexity in recognition tasks, models that are invariant to these transformations help reduce the amount of training data required. This further increases the model's efficiency and simplifies training. In this paper, we investigate the generalization of invariant representations on out-of-distribution data and try to answer the question: Do model representations invariant to some transformations in a particular seen domain also remain invariant in previously unseen domains? Through extensive experiments, we demonstrate that the invariant model learns unstructured latent representations that are robust to distribution shifts, thus making invariance a desirable property for training in resource-constrained settings.
Efficient Computation of Map-scale Continuous Mutual Information on Chip in Real Time
Oct 07, 2022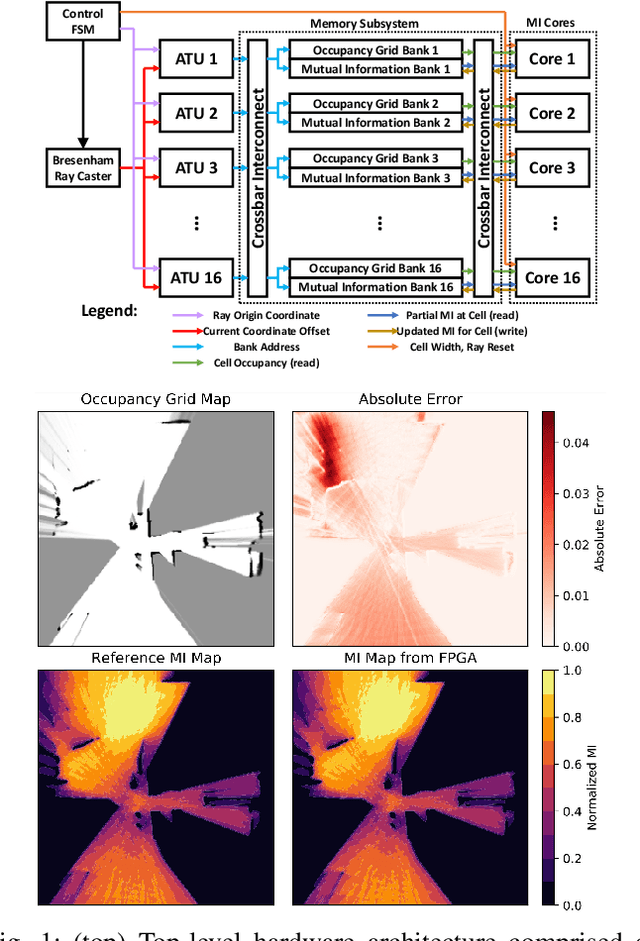
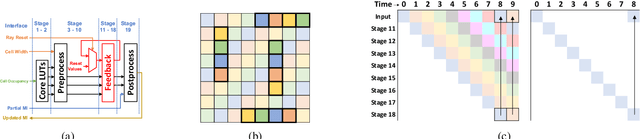
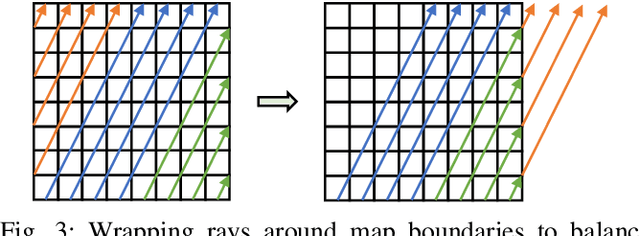
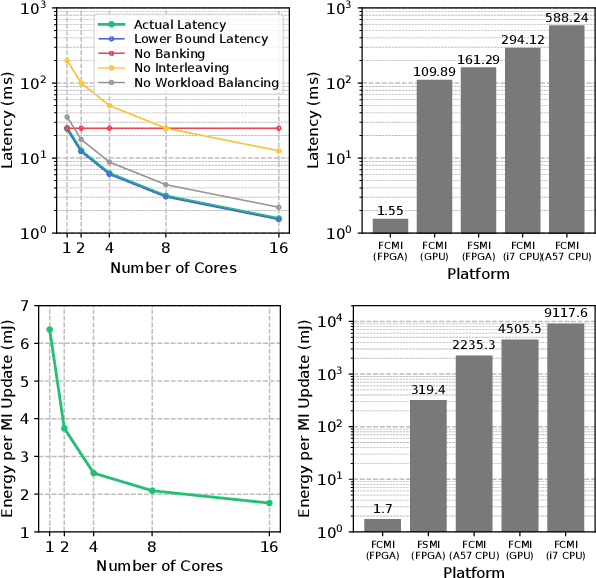
Exploration tasks are essential to many emerging robotics applications, ranging from search and rescue to space exploration. The planning problem for exploration requires determining the best locations for future measurements that will enhance the fidelity of the map, for example, by reducing its total entropy. A widely-studied technique involves computing the Mutual Information (MI) between the current map and future measurements, and utilizing this MI metric to decide the locations for future measurements. However, computing MI for reasonably-sized maps is slow and power hungry, which has been a bottleneck towards fast and efficient robotic exploration. In this paper, we introduce a new hardware accelerator architecture for MI computation that features a low-latency, energy-efficient MI compute core and an optimized memory subsystem that provides sufficient bandwidth to keep the cores fully utilized. The core employs interleaving to counter the recursive algorithm, and workload balancing and numerical approximations to reduce latency and energy consumption. We demonstrate this optimized architecture with a Field-Programmable Gate Array (FPGA) implementation, which can compute MI for all cells in an entire 201-by-201 occupancy grid ({\em e.g.}, representing a 20.1m-by-20.1m map at 0.1m resolution) in 1.55 ms while consuming 1.7 mJ of energy, thus finally rendering MI computation for the whole map real time and at a fraction of the energy cost of traditional compute platforms. For comparison, this particular FPGA implementation running on the Xilinx Zynq-7000 platform is two orders of magnitude faster and consumes three orders of magnitude less energy per MI map compute, when compared to a baseline GPU implementation running on an NVIDIA GeForce GTX 980 platform. The improvements are more pronounced when compared to CPU implementations of equivalent algorithms.