 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Computation of Map-scale Continuous Mutual Information on Chip in Real Time
Paper and Code
Oct 07, 2022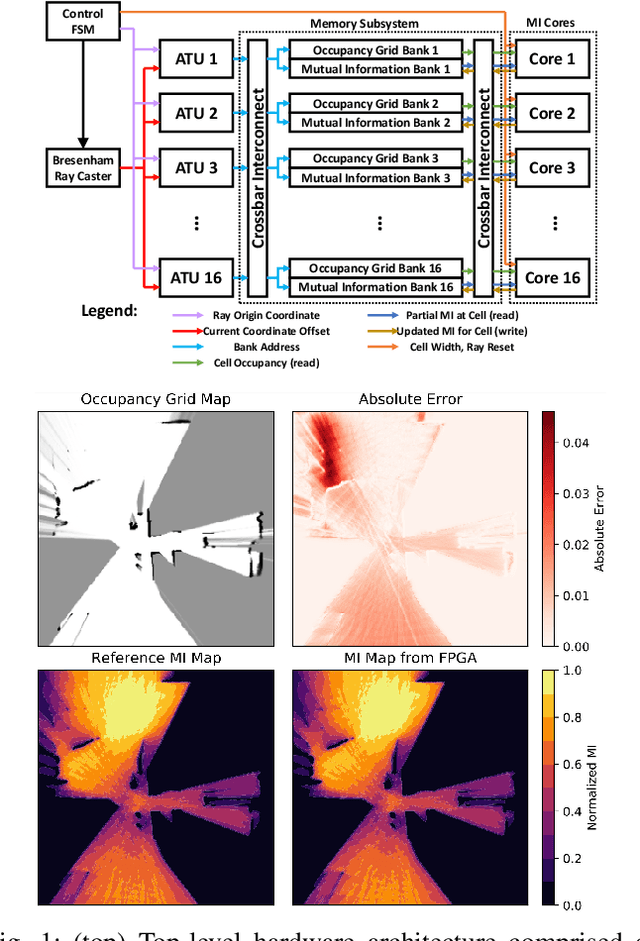
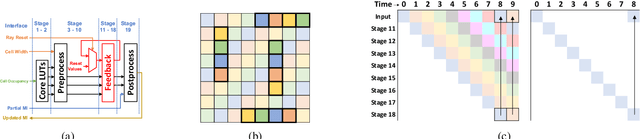
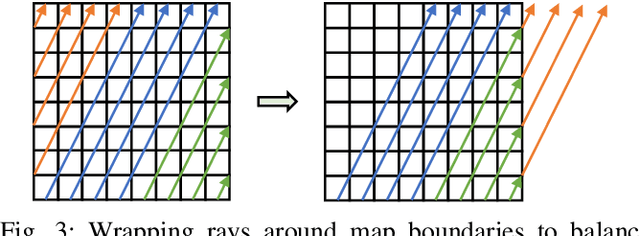
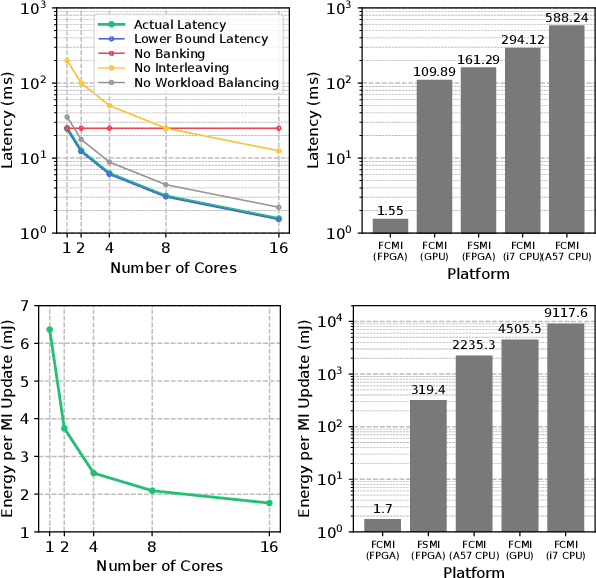
Exploration tasks are essential to many emerging robotics applications, ranging from search and rescue to space exploration. The planning problem for exploration requires determining the best locations for future measurements that will enhance the fidelity of the map, for example, by reducing its total entropy. A widely-studied technique involves computing the Mutual Information (MI) between the current map and future measurements, and utilizing this MI metric to decide the locations for future measurements. However, computing MI for reasonably-sized maps is slow and power hungry, which has been a bottleneck towards fast and efficient robotic exploration. In this paper, we introduce a new hardware accelerator architecture for MI computation that features a low-latency, energy-efficient MI compute core and an optimized memory subsystem that provides sufficient bandwidth to keep the cores fully utilized. The core employs interleaving to counter the recursive algorithm, and workload balancing and numerical approximations to reduce latency and energy consumption. We demonstrate this optimized architecture with a Field-Programmable Gate Array (FPGA) implementation, which can compute MI for all cells in an entire 201-by-201 occupancy grid ({\em e.g.}, representing a 20.1m-by-20.1m map at 0.1m resolution) in 1.55 ms while consuming 1.7 mJ of energy, thus finally rendering MI computation for the whole map real time and at a fraction of the energy cost of traditional compute platforms. For comparison, this particular FPGA implementation running on the Xilinx Zynq-7000 platform is two orders of magnitude faster and consumes three orders of magnitude less energy per MI map compute, when compared to a baseline GPU implementation running on an NVIDIA GeForce GTX 980 platform. The improvements are more pronounced when compared to CPU implementations of equivalent algorithms.