 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDream: Exchanging dreams instead of models for federated aggregation with heterogeneous models
Feb 27, 2024Federated Learning (FL) enables collaborative optimization of machine learning models across decentralized data by aggregating model parameters. Our approach extends this concept by aggregating "knowledge" derived from models, instead of model parameters. We present a novel framework called CoDream, where clients collaboratively optimize randomly initialized data using federated optimization in the input data space, similar to how randomly initialized model parameters are optimized in FL. Our key insight is that jointly optimizing this data can effectively capture the properties of the global data distribution. Sharing knowledge in data space offers numerous benefits: (1) model-agnostic collaborative learning, i.e., different clients can have different model architectures; (2) communication that is independent of the model size, eliminating scalability concerns with model parameters; (3) compatibility with secure aggregation, thus preserving the privacy benefits of federated learning; (4) allowing of adaptive optimization of knowledge shared for personalized learning. We empirically validate CoDream on standard FL tasks, demonstrating competitive performance despite not sharing model parameters. Our code: https://mitmedialab.github.io/codream.github.io/
First 100 days of pandemic; an interplay of pharmaceutical, behavioral and digital interventions -- A study using agent based modeling
Jan 09, 2024



Pandemics, notably the recent COVID-19 outbreak, have impacted both public health and the global economy. A profound understanding of disease progression and efficient response strategies is thus needed to prepare for potential future outbreaks. In this paper, we emphasize the potential of Agent-Based Models (ABM) in capturing complex infection dynamics and understanding the impact of interventions. We simulate realistic pharmaceutical, behavioral, and digital interventions that mirror challenges in real-world policy adoption and suggest a holistic combination of these interventions for pandemic response. Using these simulations, we study the trends of emergent behavior on a large-scale population based on real-world socio-demographic and geo-census data from Kings County in Washington. Our analysis reveals the pivotal role of the initial 100 days in dictating a pandemic's course, emphasizing the importance of quick decision-making and efficient policy development. Further, we highlight that investing in behavioral and digital interventions can reduce the burden on pharmaceutical interventions by reducing the total number of infections and hospitalizations, and by delaying the pandemic's peak. We also infer that allocating the same amount of dollars towards extensive testing with contact tracing and self-quarantine offers greater cost efficiency compared to spending the entire budget on vaccinations.
Conformal Prediction with Large Language Models for Multi-Choice Question Answering
Jun 01, 2023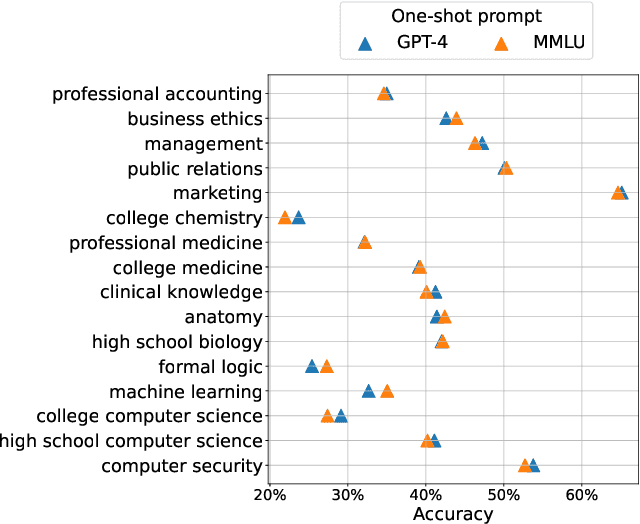
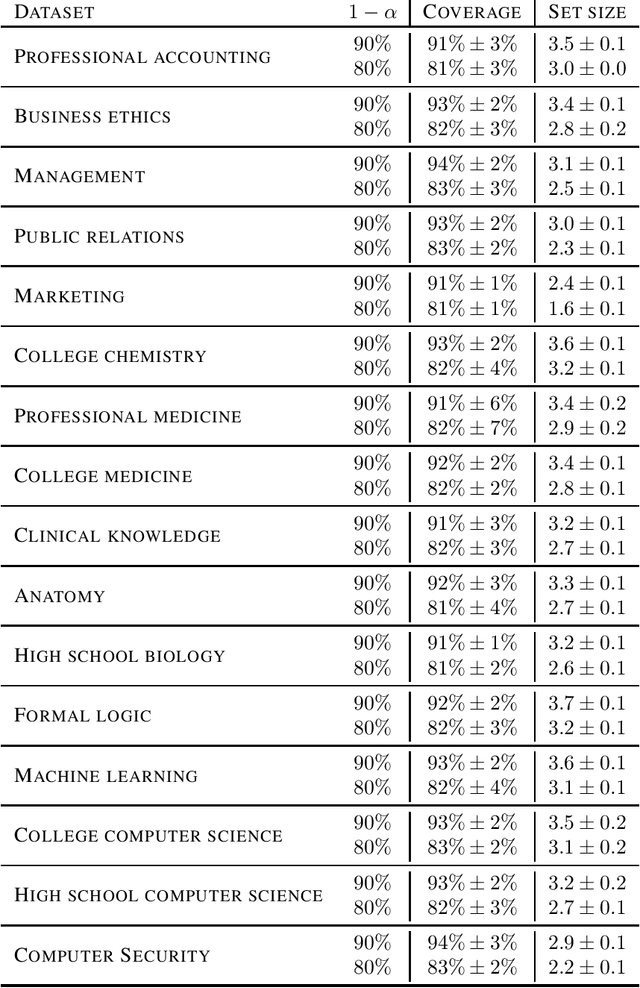
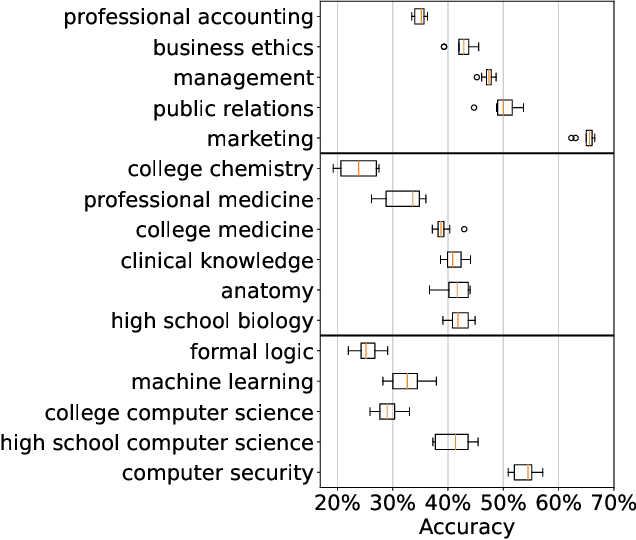
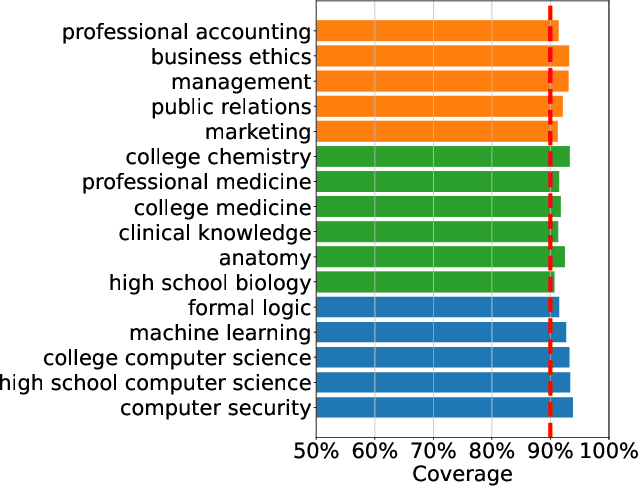
As large language models continue to be widely developed, robust uncertainty quantification techniques will become crucial for their safe deployment in high-stakes scenarios. In this work, we explore how conformal prediction can be used to provide uncertainty quantification in language models for the specific task of multiple-choice question-answering. We find that the uncertainty estimates from conformal prediction are tightly correlated with prediction accuracy. This observation can be useful for downstream applications such as selective classification and filtering out low-quality predictions. We also investigate the exchangeability assumption required by conformal prediction to out-of-subject questions, which may be a more realistic scenario for many practical applications. Our work contributes towards more trustworthy and reliable usage of large language models in safety-critical situations, where robust guarantees of error rate are required.
Domain Generalization In Robust Invariant Representation
Apr 07, 2023
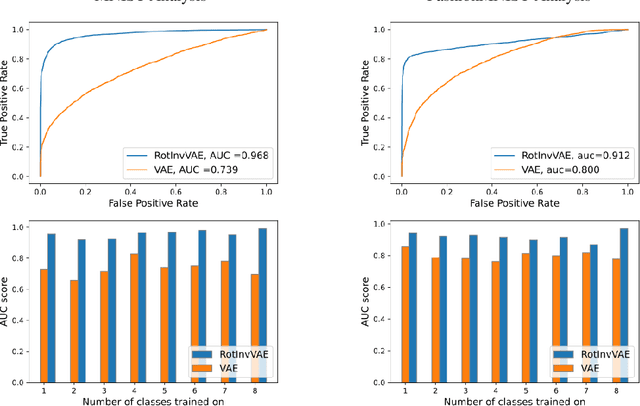


Unsupervised approaches for learning representations invariant to common transformations are used quite often for object recognition. Learning invariances makes models more robust and practical to use in real-world scenarios. Since data transformations that do not change the intrinsic properties of the object cause the majority of the complexity in recognition tasks, models that are invariant to these transformations help reduce the amount of training data required. This further increases the model's efficiency and simplifies training. In this paper, we investigate the generalization of invariant representations on out-of-distribution data and try to answer the question: Do model representations invariant to some transformations in a particular seen domain also remain invariant in previously unseen domains? Through extensive experiments, we demonstrate that the invariant model learns unstructured latent representations that are robust to distribution shifts, thus making invariance a desirable property for training in resource-constrained settings.
Curb Your Carbon Emissions: Benchmarking Carbon Emissions in Machine Translation
Oct 11, 2021
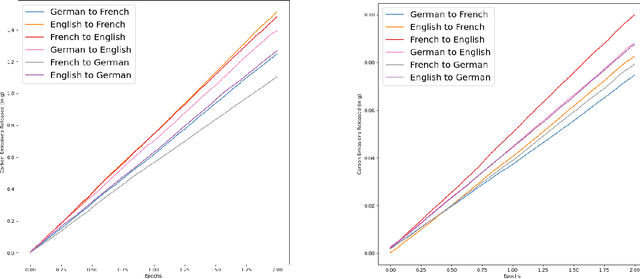
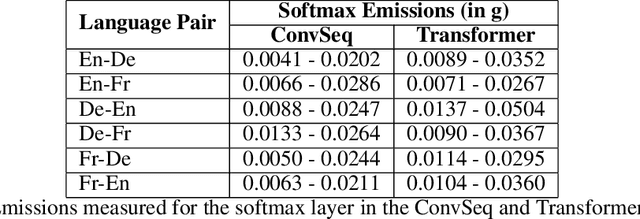

In recent times, there has been definitive progress in the field of NLP, with its applications growing as the utility of our language models increases with advances in their performance. However, these models require a large amount of computational power and data to train, consequently leading to large carbon footprints. Therefore, it is imperative that we study the carbon efficiency and look for alternatives to reduce the overall environmental impact of training models, in particular large language models. In our work, we assess the performance of models for machine translation, across multiple language pairs to assess the difference in computational power required to train these models for each of these language pairs and examine the various components of these models to analyze aspects of our pipeline that can be optimized to reduce these carbon emissions.
Evaluating Gender Bias in Hindi-English Machine Translation
Jun 16, 2021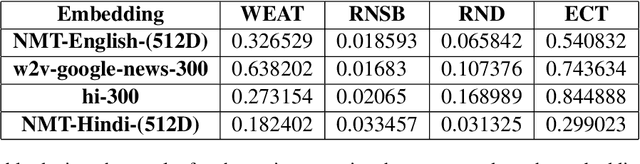
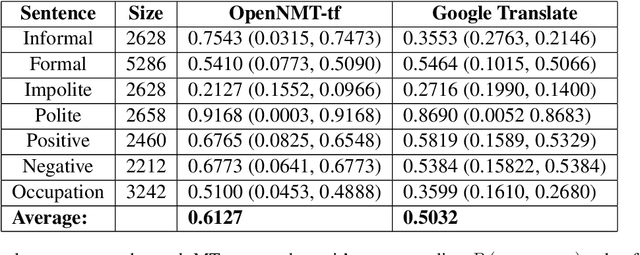
With language models being deployed increasingly in the real world, it is essential to address the issue of the fairness of their outputs. The word embedding representations of these language models often implicitly draw unwanted associations that form a social bias within the model. The nature of gendered languages like Hindi, poses an additional problem to the quantification and mitigation of bias, owing to the change in the form of the words in the sentence, based on the gender of the subject. Additionally, there is sparse work done in the realm of measuring and debiasing systems for Indic languages. In our work, we attempt to evaluate and quantify the gender bias within a Hindi-English machine translation system. We implement a modified version of the existing TGBI metric based on the grammatical considerations for Hindi. We also compare and contrast the resulting bias measurements across multiple metrics for pre-trained embeddings and the ones learned by our machine translation model.
GupShup: An Annotated Corpus for Abstractive Summarization of Open-Domain Code-Switched Conversations
Apr 17, 2021



Code-switching is the communication phenomenon where speakers switch between different languages during a conversation. With the widespread adoption of conversational agents and chat platforms, code-switching has become an integral part of written conversations in many multi-lingual communities worldwide. This makes it essential to develop techniques for summarizing and understanding these conversations. Towards this objective, we introduce abstractive summarization of Hindi-English code-switched conversations and develop the first code-switched conversation summarization dataset - GupShup, which contains over 6,831 conversations in Hindi-English and their corresponding human-annotated summaries in English and Hindi-English. We present a detailed account of the entire data collection and annotation processes. We analyze the dataset using various code-switching statistics. We train state-of-the-art abstractive summarization models and report their performances using both automated metrics and human evaluation. Our results show that multi-lingual mBART and multi-view seq2seq models obtain the best performances on the new dataset