 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Barriers to Tactics: A Behavioral Science-Informed Agentic Workflow for Personalized Nutrition Coaching
Oct 17, 2024



Effective management of cardiometabolic conditions requires sustained positive nutrition habits, often hindered by complex and individualized barriers. Direct human management is simply not scalable, while previous attempts aimed at automating nutrition coaching lack the personalization needed to address these diverse challenges. This paper introduces a novel LLM-powered agentic workflow designed to provide personalized nutrition coaching by directly targeting and mitigating patient-specific barriers. Grounded in behavioral science principles, the workflow leverages a comprehensive mapping of nutrition-related barriers to corresponding evidence-based strategies. A specialized LLM agent intentionally probes for and identifies the root cause of a patient's dietary struggles. Subsequently, a separate LLM agent delivers tailored tactics designed to overcome those specific barriers with patient context. We designed and validated our approach through a user study with individuals with cardiometabolic conditions, demonstrating the system's ability to accurately identify barriers and provide personalized guidance. Furthermore, we conducted a large-scale simulation study, grounding on real patient vignettes and expert-validated metrics, to evaluate the system's performance across a wide range of scenarios. Our findings demonstrate the potential of this LLM-powered agentic workflow to improve nutrition coaching by providing personalized, scalable, and behaviorally-informed interventions.
The Geometry of Queries: Query-Based Innovations in Retrieval-Augmented Generation
Jul 25, 2024Digital health chatbots powered by Large Language Models (LLMs) have the potential to significantly improve personal health management for chronic conditions by providing accessible and on-demand health coaching and question-answering. However, these chatbots risk providing unverified and inaccurate information because LLMs generate responses based on patterns learned from diverse internet data. Retrieval Augmented Generation (RAG) can help mitigate hallucinations and inaccuracies in LLM responses by grounding it on reliable content. However, efficiently and accurately retrieving most relevant set of content for real-time user questions remains a challenge. In this work, we introduce Query-Based Retrieval Augmented Generation (QB-RAG), a novel approach that pre-computes a database of potential queries from a content base using LLMs. For an incoming patient question, QB-RAG efficiently matches it against this pre-generated query database using vector search, improving alignment between user questions and the content. We establish a theoretical foundation for QB-RAG and provide a comparative analysis of existing retrieval enhancement techniques for RAG systems. Finally, our empirical evaluation demonstrates that QB-RAG significantly improves the accuracy of healthcare question answering, paving the way for robust and trustworthy LLM applications in digital health.
Selective Fine-tuning on LLM-labeled Data May Reduce Reliance on Human Annotation: A Case Study Using Schedule-of-Event Table Detection
May 09, 2024



Large Language Models (LLMs) have demonstrated their efficacy across a broad spectrum of tasks in healthcare applications. However, often LLMs need to be fine-tuned on task-specific expert annotated data to achieve optimal performance, which can be expensive and time consuming. In this study, we fine-tune PaLM-2 with parameter efficient fine-tuning (PEFT) using noisy labels obtained from gemini-pro 1.0 for the detection of Schedule-of-Event (SoE) tables, which specify care plan in clinical trial protocols. We introduce a filtering mechanism to select high-confidence labels for this table classification task, thereby reducing the noise in the auto-generated labels. We show that fine-tuned PaLM-2 with those labels achieves performance that exceeds the gemini-pro 1.0 and other LLMs. Furthermore, its performance is close to a PaLM-2 fine-tuned on labels obtained from non-expert annotators. Our results show that leveraging LLM-generated labels through powerful models like gemini-pro can potentially serve as a viable strategy for improving LLM performance through fine-tuning in specialized tasks, particularly in domains where expert annotations are scarce, expensive, or time-consuming to obtain.
Labrador: Exploring the Limits of Masked Language Modeling for Laboratory Data
Dec 09, 2023
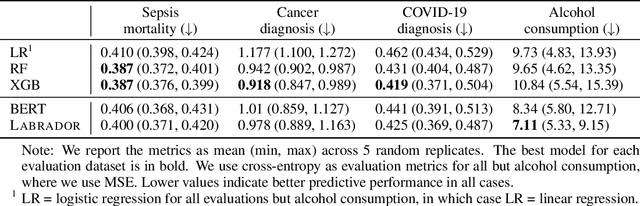


In this work we introduce Labrador, a pre-trained Transformer model for laboratory data. Labrador and BERT were pre-trained on a corpus of 100 million lab test results from electronic health records (EHRs) and evaluated on various downstream outcome prediction tasks. Both models demonstrate mastery of the pre-training task but neither consistently outperform XGBoost on downstream supervised tasks. Our ablation studies reveal that transfer learning shows limited effectiveness for BERT and achieves marginal success with Labrador. We explore the reasons for the failure of transfer learning and suggest that the data generating process underlying each patient cannot be characterized sufficiently using labs alone, among other factors. We encourage future work to focus on joint modeling of multiple EHR data categories and to include tree-based baselines in their evaluations.
Conformal Prediction with Large Language Models for Multi-Choice Question Answering
Jun 01, 2023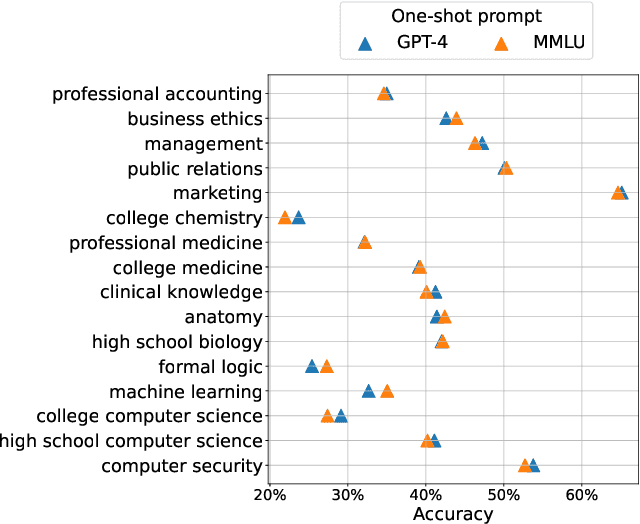
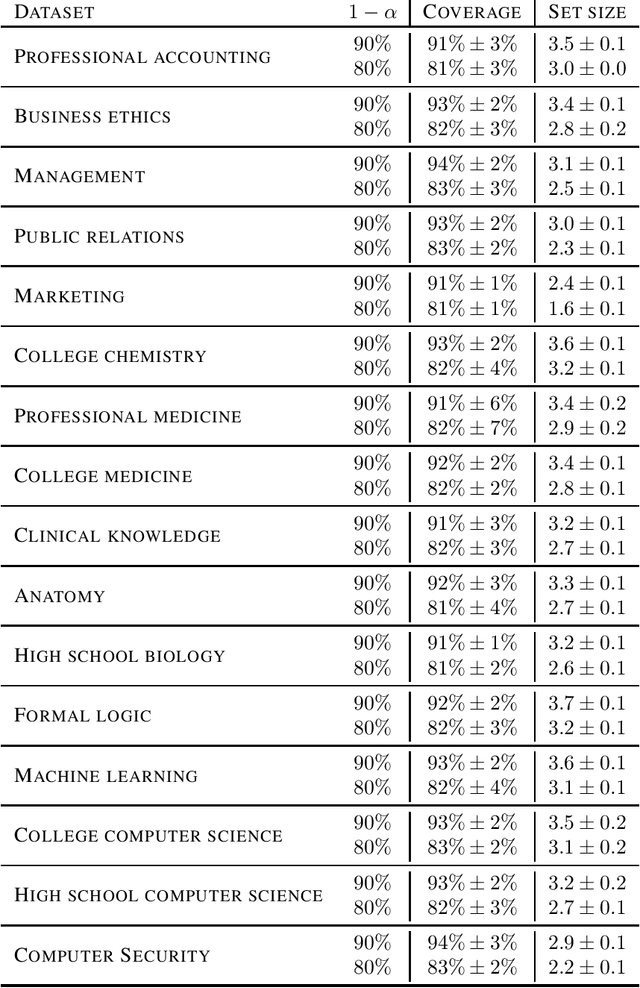
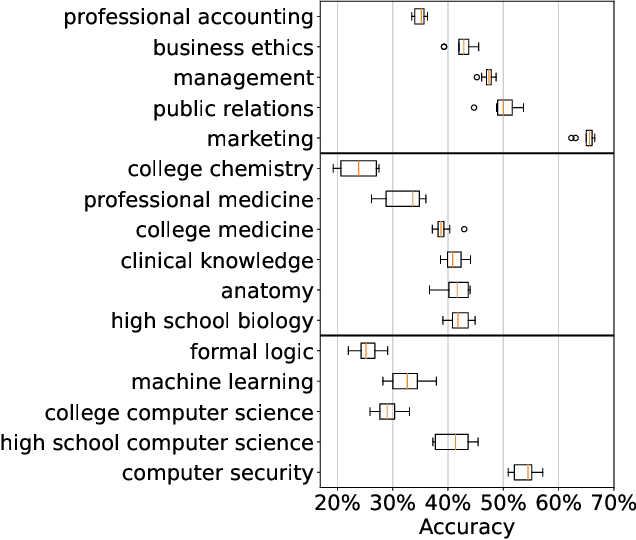
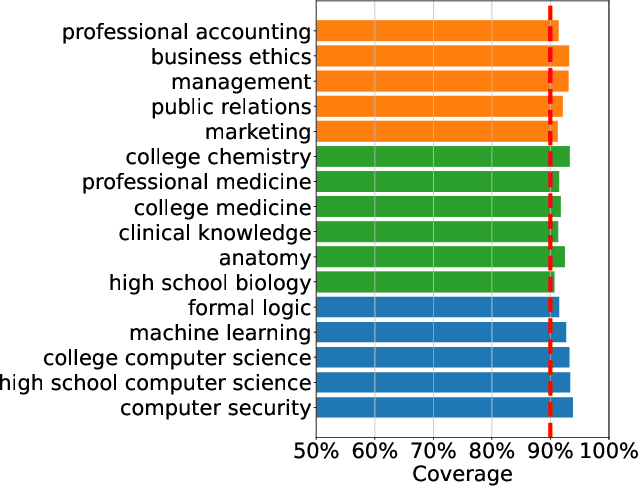
As large language models continue to be widely developed, robust uncertainty quantification techniques will become crucial for their safe deployment in high-stakes scenarios. In this work, we explore how conformal prediction can be used to provide uncertainty quantification in language models for the specific task of multiple-choice question-answering. We find that the uncertainty estimates from conformal prediction are tightly correlated with prediction accuracy. This observation can be useful for downstream applications such as selective classification and filtering out low-quality predictions. We also investigate the exchangeability assumption required by conformal prediction to out-of-subject questions, which may be a more realistic scenario for many practical applications. Our work contributes towards more trustworthy and reliable usage of large language models in safety-critical situations, where robust guarantees of error rate are required.
Towards Reliable Zero Shot Classification in Self-Supervised Models with Conformal Prediction
Oct 27, 2022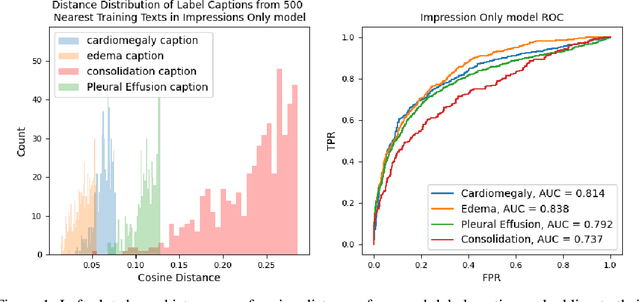
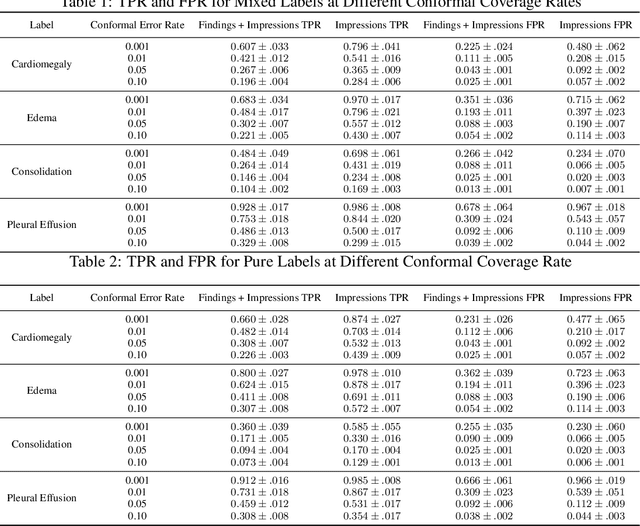
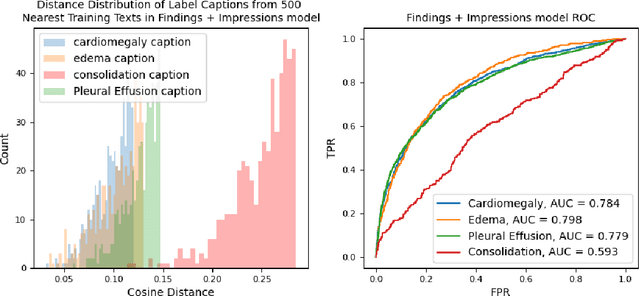

Self-supervised models trained with a contrastive loss such as CLIP have shown to be very powerful in zero-shot classification settings. However, to be used as a zero-shot classifier these models require the user to provide new captions over a fixed set of labels at test time. In many settings, it is hard or impossible to know if a new query caption is compatible with the source captions used to train the model. We address these limitations by framing the zero-shot classification task as an outlier detection problem and develop a conformal prediction procedure to assess when a given test caption may be reliably used. On a real-world medical example, we show that our proposed conformal procedure improves the reliability of CLIP-style models in the zero-shot classification setting, and we provide an empirical analysis of the factors that may affect its performance.