 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Human-Robot Communication for Physical Human-Robot Interaction
Jan 15, 2026Effective physical human-robot interaction requires systems that are not only adaptable to user preferences but also transparent about their actions. This paper introduces BRIDGE, a system for bidirectional human-robot communication in physical assistance. Our method allows users to modify a robot's planned trajectory -- position, velocity, and force -- in real time using natural language. We utilize a large language model (LLM) to interpret any trajectory modifications implied by user commands in the context of the planned motion and conversation history. Importantly, our system provides verbal feedback in response to the user, either assuring any resulting changes or posing a clarifying question. We evaluated our method in a user study with 18 older adults across three assistive tasks, comparing BRIDGE to an ablation without verbal feedback and a baseline. Results show that participants successfully used the system to modify trajectories in real time. Moreover, the bidirectional feedback led to significantly higher ratings of interactivity and transparency, demonstrating that the robot's verbal response is critical for a more intuitive user experience. Videos and code can be found on our project website: https://bidir-comm.github.io/
Embodied Tree of Thoughts: Deliberate Manipulation Planning with Embodied World Model
Dec 09, 2025World models have emerged as a pivotal component in robot manipulation planning, enabling agents to predict future environmental states and reason about the consequences of actions before execution. While video-generation models are increasingly adopted, they often lack rigorous physical grounding, leading to hallucinations and a failure to maintain consistency in long-horizon physical constraints. To address these limitations, we propose Embodied Tree of Thoughts (EToT), a novel Real2Sim2Real planning framework that leverages a physics-based interactive digital twin as an embodied world model. EToT formulates manipulation planning as a tree search expanded through two synergistic mechanisms: (1) Priori Branching, which generates diverse candidate execution paths based on semantic and spatial analysis; and (2) Reflective Branching, which utilizes VLMs to diagnose execution failures within the simulator and iteratively refine the planning tree with corrective actions. By grounding high-level reasoning in a physics simulator, our framework ensures that generated plans adhere to rigid-body dynamics and collision constraints. We validate EToT on a suite of short- and long-horizon manipulation tasks, where it consistently outperforms baselines by effectively predicting physical dynamics and adapting to potential failures. Website at https://embodied-tree-of-thoughts.github.io .
Generation, Distillation and Evaluation of Motivational Interviewing-Style Reflections with a Foundational Language Model
Feb 01, 2024



Large Foundational Language Models are capable of performing many tasks at a high level but are difficult to deploy in many applications because of their size and proprietary ownership. Many will be motivated to distill specific capabilities of foundational models into smaller models that can be owned and controlled. In the development of a therapeutic chatbot, we wish to distill a capability known as reflective listening, in which a therapist produces reflections of client speech. These reflections either restate what a client has said, or connect what was said to a relevant observation, idea or guess that encourages and guides the client to continue contemplation. In this paper, we present a method for distilling the generation of reflections from a Foundational Language Model (GPT-4) into smaller models. We first show that GPT-4, using zero-shot prompting, can generate reflections at near 100% success rate, superior to all previous methods. Using reflections generated by GPT-4, we fine-tune different sizes of the GPT-2 family. The GPT-2-small model achieves 83% success on a hold-out test set and the GPT-2 XL achieves 90% success. We also show that GPT-4 can help in the labor-intensive task of evaluating the quality of the distilled models, using it as a zero-shot classifier. Using triple-human review as a guide, the classifier achieves a Cohen-Kappa of 0.66, a substantial inter-rater reliability figure.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Labrador: Exploring the Limits of Masked Language Modeling for Laboratory Data
Dec 09, 2023
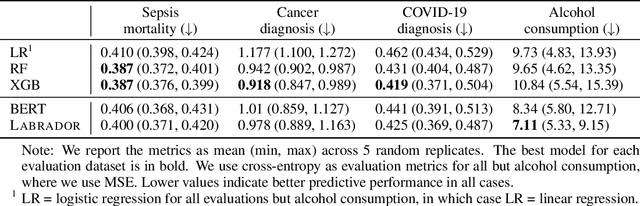


In this work we introduce Labrador, a pre-trained Transformer model for laboratory data. Labrador and BERT were pre-trained on a corpus of 100 million lab test results from electronic health records (EHRs) and evaluated on various downstream outcome prediction tasks. Both models demonstrate mastery of the pre-training task but neither consistently outperform XGBoost on downstream supervised tasks. Our ablation studies reveal that transfer learning shows limited effectiveness for BERT and achieves marginal success with Labrador. We explore the reasons for the failure of transfer learning and suggest that the data generating process underlying each patient cannot be characterized sufficiently using labs alone, among other factors. We encourage future work to focus on joint modeling of multiple EHR data categories and to include tree-based baselines in their evaluations.