 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Generators are Generalist Vision Learners
Apr 22, 2026Recent works show that image and video generators exhibit zero-shot visual understanding behaviors, in a way reminiscent of how LLMs develop emergent capabilities of language understanding and reasoning from generative pretraining. While it has long been conjectured that the ability to create visual content implies an ability to understand it, there has been limited evidence that generative vision models have developed strong understanding capabilities. In this work, we demonstrate that image generation training serves a role similar to LLM pretraining, and lets models learn powerful and general visual representations that enable SOTA performance on various vision tasks. We introduce Vision Banana, a generalist model built by instruction-tuning Nano Banana Pro (NBP) on a mixture of its original training data alongside a small amount of vision task data. By parameterizing the output space of vision tasks as RGB images, we seamlessly reframe perception as image generation. Our generalist model, Vision Banana, achieves SOTA results on a variety of vision tasks involving both 2D and 3D understanding, beating or rivaling zero-shot domain-specialists, including Segment Anything Model 3 on segmentation tasks, and the Depth Anything series on metric depth estimation. We show that these results can be achieved with lightweight instruction-tuning without sacrificing the base model's image generation capabilities. The superior results suggest that image generation pretraining is a generalist vision learner. It also shows that image generation serves as a unified and universal interface for vision tasks, similar to text generation's role in language understanding and reasoning. We could be witnessing a major paradigm shift for computer vision, where generative vision pretraining takes a central role in building Foundational Vision Models for both generation and understanding.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Making the Most of What You Have: Adapting Pre-trained Visual Language Models in the Low-data Regime
May 03, 2023



Large-scale visual language models are widely used as pre-trained models and then adapted for various downstream tasks. While humans are known to efficiently learn new tasks from a few examples, deep learning models struggle with adaptation from few examples. In this work, we look into task adaptation in the low-data regime, and provide a thorough study of the existing adaptation methods for generative Visual Language Models. And we show important benefits of self-labelling, i.e. using the model's own predictions to self-improve when having access to a larger number of unlabelled images of the same distribution. Our study demonstrates significant gains using our proposed task adaptation pipeline across a wide range of visual language tasks such as visual classification (ImageNet), visual captioning (COCO), detailed visual captioning (Localised Narratives) and visual question answering (VQAv2).
Three ways to improve feature alignment for open vocabulary detection
Mar 23, 2023
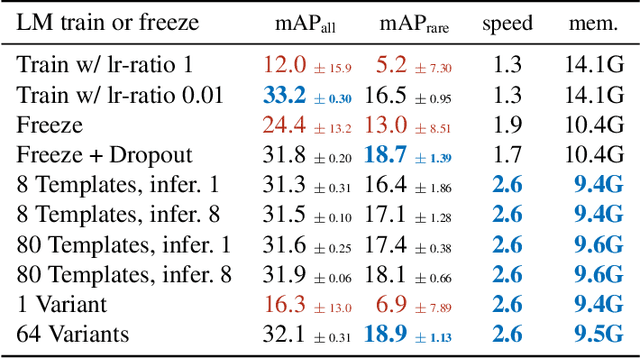
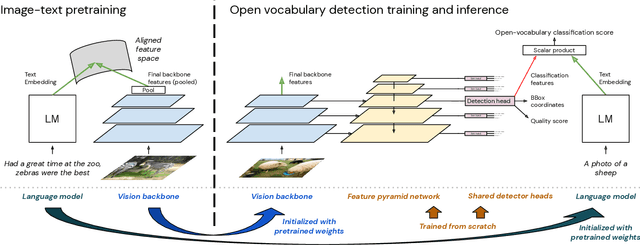
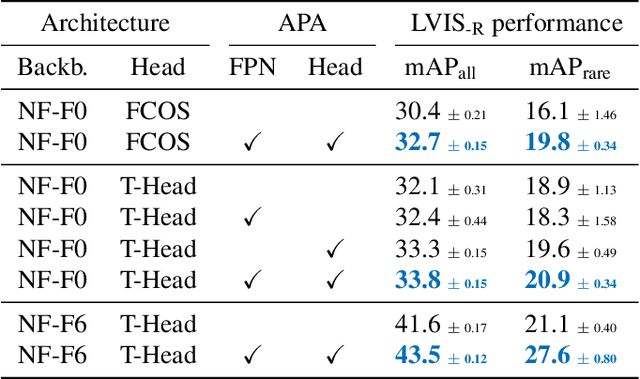
The core problem in zero-shot open vocabulary detection is how to align visual and text features, so that the detector performs well on unseen classes. Previous approaches train the feature pyramid and detection head from scratch, which breaks the vision-text feature alignment established during pretraining, and struggles to prevent the language model from forgetting unseen classes. We propose three methods to alleviate these issues. Firstly, a simple scheme is used to augment the text embeddings which prevents overfitting to a small number of classes seen during training, while simultaneously saving memory and computation. Secondly, the feature pyramid network and the detection head are modified to include trainable gated shortcuts, which encourages vision-text feature alignment and guarantees it at the start of detection training. Finally, a self-training approach is used to leverage a larger corpus of image-text pairs thus improving detection performance on classes with no human annotated bounding boxes. Our three methods are evaluated on the zero-shot version of the LVIS benchmark, each of them showing clear and significant benefits. Our final network achieves the new stateof-the-art on the mAP-all metric and demonstrates competitive performance for mAP-rare, as well as superior transfer to COCO and Objects365.
Multi-Task Learning of Object State Changes from Uncurated Videos
Nov 24, 2022



We aim to learn to temporally localize object state changes and the corresponding state-modifying actions by observing people interacting with objects in long uncurated web videos. We introduce three principal contributions. First, we explore alternative multi-task network architectures and identify a model that enables efficient joint learning of multiple object states and actions such as pouring water and pouring coffee. Second, we design a multi-task self-supervised learning procedure that exploits different types of constraints between objects and state-modifying actions enabling end-to-end training of a model for temporal localization of object states and actions in videos from only noisy video-level supervision. Third, we report results on the large-scale ChangeIt and COIN datasets containing tens of thousands of long (un)curated web videos depicting various interactions such as hole drilling, cream whisking, or paper plane folding. We show that our multi-task model achieves a relative improvement of 40% over the prior single-task methods and significantly outperforms both image-based and video-based zero-shot models for this problem. We also test our method on long egocentric videos of the EPIC-KITCHENS and the Ego4D datasets in a zero-shot setup demonstrating the robustness of our learned model.
Flamingo: a Visual Language Model for Few-Shot Learning
Apr 29, 2022
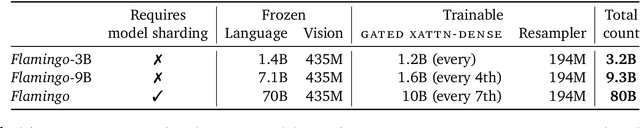
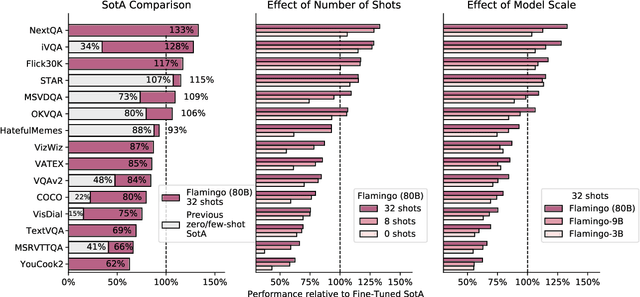
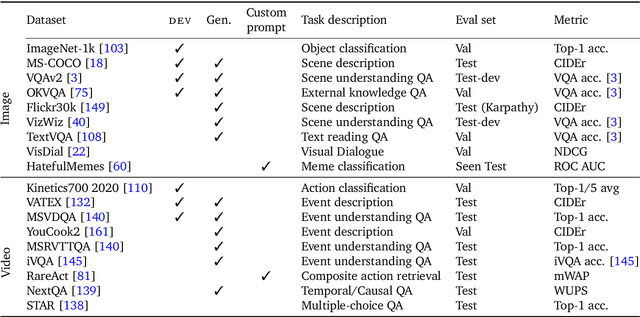
Building models that can be rapidly adapted to numerous tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. Flamingo models include key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. We perform a thorough evaluation of the proposed Flamingo models, exploring and measuring their ability to rapidly adapt to a variety of image and video understanding benchmarks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer, captioning tasks, which evaluate the ability to describe a scene or an event, and close-ended tasks such as multiple choice visual question-answering. For tasks lying anywhere on this spectrum, we demonstrate that a single Flamingo model can achieve a new state of the art for few-shot learning, simply by prompting the model with task-specific examples. On many of these benchmarks, Flamingo actually surpasses the performance of models that are fine-tuned on thousands of times more task-specific data.
Look for the Change: Learning Object States and State-Modifying Actions from Untrimmed Web Videos
Mar 22, 2022
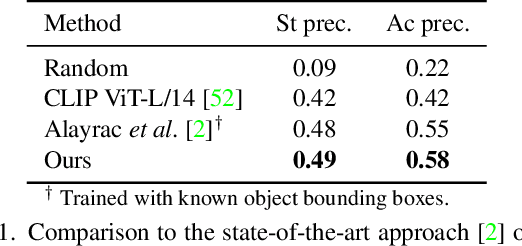
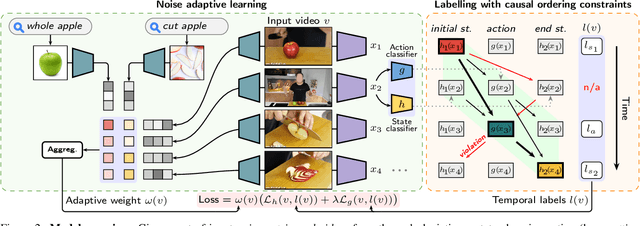

Human actions often induce changes of object states such as "cutting an apple", "cleaning shoes" or "pouring coffee". In this paper, we seek to temporally localize object states (e.g. "empty" and "full" cup) together with the corresponding state-modifying actions ("pouring coffee") in long uncurated videos with minimal supervision. The contributions of this work are threefold. First, we develop a self-supervised model for jointly learning state-modifying actions together with the corresponding object states from an uncurated set of videos from the Internet. The model is self-supervised by the causal ordering signal, i.e. initial object state $\rightarrow$ manipulating action $\rightarrow$ end state. Second, to cope with noisy uncurated training data, our model incorporates a noise adaptive weighting module supervised by a small number of annotated still images, that allows to efficiently filter out irrelevant videos during training. Third, we collect a new dataset with more than 2600 hours of video and 34 thousand changes of object states, and manually annotate a part of this data to validate our approach. Our results demonstrate substantial improvements over prior work in both action and object state-recognition in video.
General-purpose, long-context autoregressive modeling with Perceiver AR
Feb 15, 2022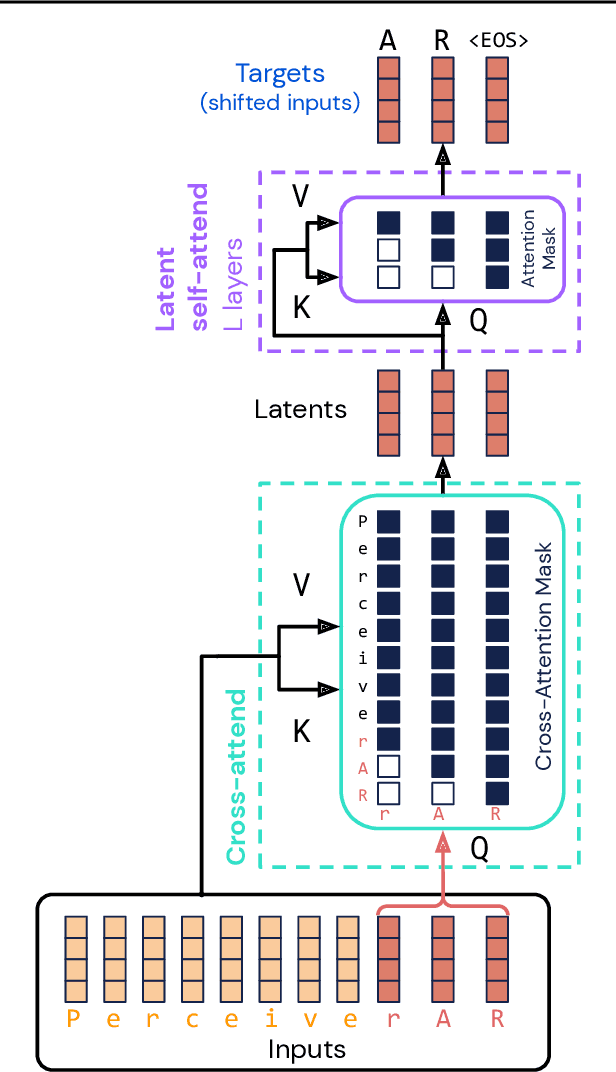
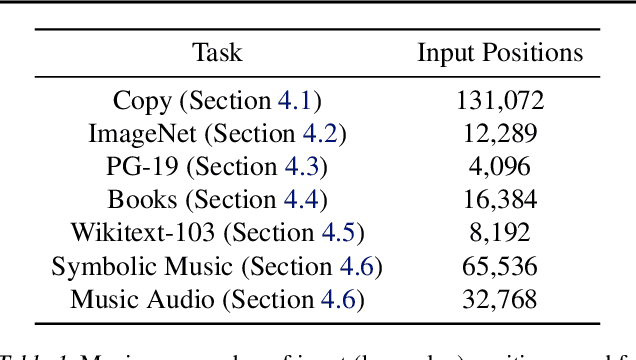
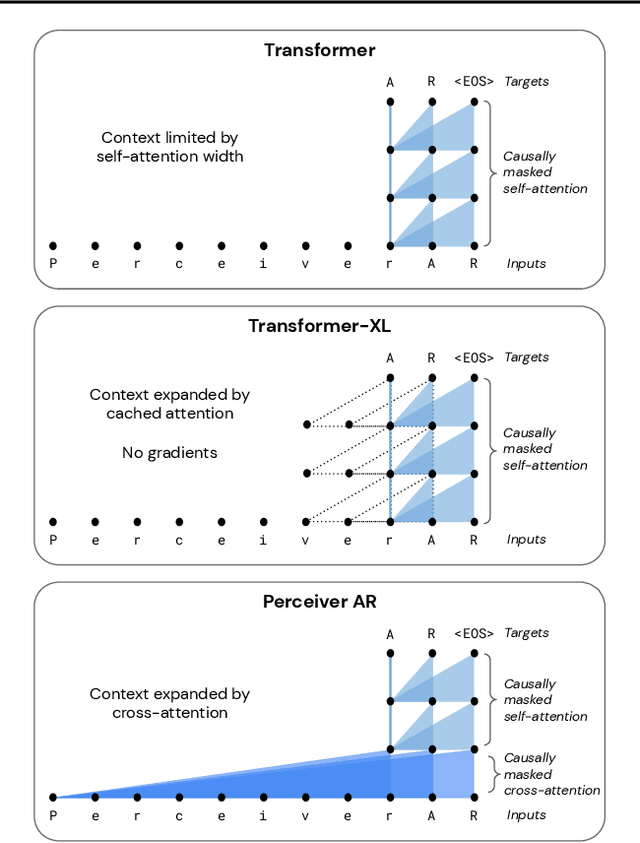
Real-world data is high-dimensional: a book, image, or musical performance can easily contain hundreds of thousands of elements even after compression. However, the most commonly used autoregressive models, Transformers, are prohibitively expensive to scale to the number of inputs and layers needed to capture this long-range structure. We develop Perceiver AR, an autoregressive, modality-agnostic architecture which uses cross-attention to map long-range inputs to a small number of latents while also maintaining end-to-end causal masking. Perceiver AR can directly attend to over a hundred thousand tokens, enabling practical long-context density estimation without the need for hand-crafted sparsity patterns or memory mechanisms. When trained on images or music, Perceiver AR generates outputs with clear long-term coherence and structure. Our architecture also obtains state-of-the-art likelihood on long-sequence benchmarks, including 64 x 64 ImageNet images and PG-19 books.