 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparentize the Internal and External Knowledge Utilization in LLMs with Trustworthy Citation
Apr 21, 2025While hallucinations of large language models could been alleviated through retrieval-augmented generation and citation generation, how the model utilizes internal knowledge is still opaque, and the trustworthiness of its generated answers remains questionable. In this work, we introduce Context-Prior Augmented Citation Generation task, requiring models to generate citations considering both external and internal knowledge while providing trustworthy references, with 5 evaluation metrics focusing on 3 aspects: answer helpfulness, citation faithfulness, and trustworthiness. We introduce RAEL, the paradigm for our task, and also design INTRALIGN, an integrated method containing customary data generation and an alignment algorithm. Our experimental results show that our method achieves a better cross-scenario performance with regard to other baselines. Our extended experiments further reveal that retrieval quality, question types, and model knowledge have considerable influence on the trustworthiness in citation generation.
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
Jan 30, 2025Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at each and every single gradient step, all devices need to be co-located using low-latency high-bandwidth communication links to support the required high volume of exchanged bits. Recently, distributed algorithms like DiLoCo have relaxed such co-location constraint: accelerators can be grouped into ``workers'', where synchronizations between workers only occur infrequently. This in turn means that workers can afford being connected by lower bandwidth communication links without affecting learning quality. However, in these methods, communication across workers still requires the same peak bandwidth as before, as the synchronizations require all parameters to be exchanged across all workers. In this paper, we improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence, rather than all at once, which greatly reduces peak bandwidth. Second, we allow workers to continue training while synchronizing, which decreases wall clock time. Third, we quantize the data exchanged by workers, which further reduces bandwidth across workers. By properly combining these modifications, we show experimentally that we can distribute training of billion-scale parameters and reach similar quality as before, but reducing required bandwidth by two orders of magnitude.
Citekit: A Modular Toolkit for Large Language Model Citation Generation
Aug 06, 2024



Enabling Large Language Models (LLMs) to generate citations in Question-Answering (QA) tasks is an emerging paradigm aimed at enhancing the verifiability of their responses when LLMs are utilizing external references to generate an answer. However, there is currently no unified framework to standardize and fairly compare different citation generation methods, leading to difficulties in reproducing different methods and a comprehensive assessment. To cope with the problems above, we introduce \name, an open-source and modular toolkit designed to facilitate the implementation and evaluation of existing citation generation methods, while also fostering the development of new approaches to improve citation quality in LLM outputs. This tool is highly extensible, allowing users to utilize 4 main modules and 14 components to construct a pipeline, evaluating an existing method or innovative designs. Our experiments with two state-of-the-art LLMs and 11 citation generation baselines demonstrate varying strengths of different modules in answer accuracy and citation quality improvement, as well as the challenge of enhancing granularity. Based on our analysis of the effectiveness of components, we propose a new method, self-RAG \snippet, obtaining a balanced answer accuracy and citation quality. Citekit is released at https://github.com/SjJ1017/Citekit.
DiPaCo: Distributed Path Composition
Mar 15, 2024Progress in machine learning (ML) has been fueled by scaling neural network models. This scaling has been enabled by ever more heroic feats of engineering, necessary for accommodating ML approaches that require high bandwidth communication between devices working in parallel. In this work, we propose a co-designed modular architecture and training approach for ML models, dubbed DIstributed PAth COmposition (DiPaCo). During training, DiPaCo distributes computation by paths through a set of shared modules. Together with a Local-SGD inspired optimization (DiLoCo) that keeps modules in sync with drastically reduced communication, Our approach facilitates training across poorly connected and heterogeneous workers, with a design that ensures robustness to worker failures and preemptions. At inference time, only a single path needs to be executed for each input, without the need for any model compression. We consider this approach as a first prototype towards a new paradigm of large-scale learning, one that is less synchronous and more modular. Our experiments on the widely used C4 benchmark show that, for the same amount of training steps but less wall-clock time, DiPaCo exceeds the performance of a 1 billion-parameter dense transformer language model by choosing one of 256 possible paths, each with a size of 150 million parameters.
Exploring Federated Self-Supervised Learning for General Purpose Audio Understanding
Feb 05, 2024The integration of Federated Learning (FL) and Self-supervised Learning (SSL) offers a unique and synergetic combination to exploit the audio data for general-purpose audio understanding, without compromising user data privacy. However, rare efforts have been made to investigate the SSL models in the FL regime for general-purpose audio understanding, especially when the training data is generated by large-scale heterogeneous audio sources. In this paper, we evaluate the performance of feature-matching and predictive audio-SSL techniques when integrated into large-scale FL settings simulated with non-independently identically distributed (non-iid) data. We propose a novel Federated SSL (F-SSL) framework, dubbed FASSL, that enables learning intermediate feature representations from large-scale decentralized heterogeneous clients, holding unlabelled audio data. Our study has found that audio F-SSL approaches perform on par with the centralized audio-SSL approaches on the audio-retrieval task. Extensive experiments demonstrate the effectiveness and significance of FASSL as it assists in obtaining the optimal global model for state-of-the-art FL aggregation methods.
Asynchronous Local-SGD Training for Language Modeling
Jan 17, 2024



Local stochastic gradient descent (Local-SGD), also referred to as federated averaging, is an approach to distributed optimization where each device performs more than one SGD update per communication. This work presents an empirical study of {\it asynchronous} Local-SGD for training language models; that is, each worker updates the global parameters as soon as it has finished its SGD steps. We conduct a comprehensive investigation by examining how worker hardware heterogeneity, model size, number of workers, and optimizer could impact the learning performance. We find that with naive implementations, asynchronous Local-SGD takes more iterations to converge than its synchronous counterpart despite updating the (global) model parameters more frequently. We identify momentum acceleration on the global parameters when worker gradients are stale as a key challenge. We propose a novel method that utilizes a delayed Nesterov momentum update and adjusts the workers' local training steps based on their computation speed. This approach, evaluated with models up to 150M parameters on the C4 dataset, matches the performance of synchronous Local-SGD in terms of perplexity per update step, and significantly surpasses it in terms of wall clock time.
A Simple Recipe for Contrastively Pre-training Video-First Encoders Beyond 16 Frames
Dec 12, 2023



Understanding long, real-world videos requires modeling of long-range visual dependencies. To this end, we explore video-first architectures, building on the common paradigm of transferring large-scale, image--text models to video via shallow temporal fusion. However, we expose two limitations to the approach: (1) decreased spatial capabilities, likely due to poor video--language alignment in standard video datasets, and (2) higher memory consumption, bottlenecking the number of frames that can be processed. To mitigate the memory bottleneck, we systematically analyze the memory/accuracy trade-off of various efficient methods: factorized attention, parameter-efficient image-to-video adaptation, input masking, and multi-resolution patchification. Surprisingly, simply masking large portions of the video (up to 75%) during contrastive pre-training proves to be one of the most robust ways to scale encoders to videos up to 4.3 minutes at 1 FPS. Our simple approach for training long video-to-text models, which scales to 1B parameters, does not add new architectural complexity and is able to outperform the popular paradigm of using much larger LLMs as an information aggregator over segment-based information on benchmarks with long-range temporal dependencies (YouCook2, EgoSchema).
DiLoCo: Distributed Low-Communication Training of Language Models
Nov 14, 2023



Large language models (LLM) have become a critical component in many applications of machine learning. However, standard approaches to training LLM require a large number of tightly interconnected accelerators, with devices exchanging gradients and other intermediate states at each optimization step. While it is difficult to build and maintain a single computing cluster hosting many accelerators, it might be easier to find several computing clusters each hosting a smaller number of devices. In this work, we propose a distributed optimization algorithm, Distributed Low-Communication (DiLoCo), that enables training of language models on islands of devices that are poorly connected. The approach is a variant of federated averaging, where the number of inner steps is large, the inner optimizer is AdamW, and the outer optimizer is Nesterov momentum. On the widely used C4 dataset, we show that DiLoCo on 8 workers performs as well as fully synchronous optimization while communicating 500 times less. DiLoCo exhibits great robustness to the data distribution of each worker. It is also robust to resources becoming unavailable over time, and vice versa, it can seamlessly leverage resources that become available during training.
Adaptive Uncertainty Estimation via High-Dimensional Testing on Latent Representations
Oct 25, 2023Uncertainty estimation aims to evaluate the confidence of a trained deep neural network. However, existing uncertainty estimation approaches rely on low-dimensional distributional assumptions and thus suffer from the high dimensionality of latent features. Existing approaches tend to focus on uncertainty on discrete classification probabilities, which leads to poor generalizability to uncertainty estimation for other tasks. Moreover, most of the literature requires seeing the out-of-distribution (OOD) data in the training for better estimation of uncertainty, which limits the uncertainty estimation performance in practice because the OOD data are typically unseen. To overcome these limitations, we propose a new framework using data-adaptive high-dimensional hypothesis testing for uncertainty estimation, which leverages the statistical properties of the feature representations. Our method directly operates on latent representations and thus does not require retraining the feature encoder under a modified objective. The test statistic relaxes the feature distribution assumptions to high dimensionality, and it is more discriminative to uncertainties in the latent representations. We demonstrate that encoding features with Bayesian neural networks can enhance testing performance and lead to more accurate uncertainty estimation. We further introduce a family-wise testing procedure to determine the optimal threshold of OOD detection, which minimizes the false discovery rate (FDR). Extensive experiments validate the satisfactory performance of our framework on uncertainty estimation and task-specific prediction over a variety of competitors. The experiments on the OOD detection task also show satisfactory performance of our method when the OOD data are unseen in the training. Codes are available at https://github.com/HKU-MedAI/bnn_uncertainty.
L-DAWA: Layer-wise Divergence Aware Weight Aggregation in Federated Self-Supervised Visual Representation Learning
Jul 14, 2023
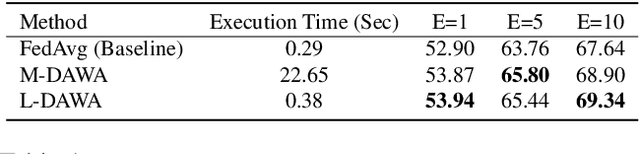
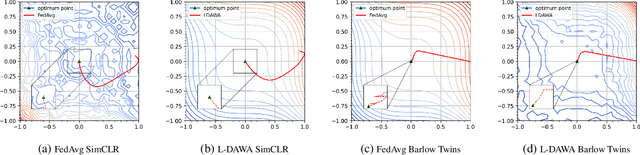
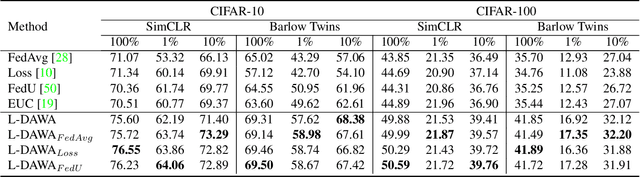
The ubiquity of camera-enabled devices has led to large amounts of unlabeled image data being produced at the edge. The integration of self-supervised learning (SSL) and federated learning (FL) into one coherent system can potentially offer data privacy guarantees while also advancing the quality and robustness of the learned visual representations without needing to move data around. However, client bias and divergence during FL aggregation caused by data heterogeneity limits the performance of learned visual representations on downstream tasks. In this paper, we propose a new aggregation strategy termed Layer-wise Divergence Aware Weight Aggregation (L-DAWA) to mitigate the influence of client bias and divergence during FL aggregation. The proposed method aggregates weights at the layer-level according to the measure of angular divergence between the clients' model and the global model. Extensive experiments with cross-silo and cross-device settings on CIFAR-10/100 and Tiny ImageNet datasets demonstrate that our methods are effective and obtain new SOTA performance on both contrastive and non-contrastive SSL approaches.