 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagLink: A Dual-User Diagnostic Assistance System by Synergizing Experts with LLMs and Knowledge Graphs
Jan 28, 2026The global shortage and uneven distribution of medical expertise continue to hinder equitable access to accurate diagnostic care. While existing intelligent diagnostic system have shown promise, most struggle with dual-user interaction, and dynamic knowledge integration -- limiting their real-world applicability. In this study, we present DiagLink, a dual-user diagnostic assistance system that synergizes large language models (LLMs), knowledge graphs (KGs), and medical experts to support both patients and physicians. DiagLink uses guided dialogues to elicit patient histories, leverages LLMs and KGs for collaborative reasoning, and incorporates physician oversight for continuous knowledge validation and evolution. The system provides a role-adaptive interface, dynamically visualized history, and unified multi-source evidence to improve both trust and usability. We evaluate DiagLink through user study, use cases and expert interviews, demonstrating its effectiveness in improving user satisfaction and diagnostic efficiency, while offering insights for the design of future AI-assisted diagnostic systems.
Deep-Learning-Based Pre-Layout Parasitic Capacitance Prediction on SRAM Designs
Jul 09, 2025To achieve higher system energy efficiency, SRAM in SoCs is often customized. The parasitic effects cause notable discrepancies between pre-layout and post-layout circuit simulations, leading to difficulty in converging design parameters and excessive design iterations. Is it possible to well predict the parasitics based on the pre-layout circuit, so as to perform parasitic-aware pre-layout simulation? In this work, we propose a deep-learning-based 2-stage model to accurately predict these parasitics in pre-layout stages. The model combines a Graph Neural Network (GNN) classifier and Multi-Layer Perceptron (MLP) regressors, effectively managing class imbalance of the net parasitics in SRAM circuits. We also employ Focal Loss to mitigate the impact of abundant internal net samples and integrate subcircuit information into the graph to abstract the hierarchical structure of schematics. Experiments on 4 real SRAM designs show that our approach not only surpasses the state-of-the-art model in parasitic prediction by a maximum of 19X reduction of error but also significantly boosts the simulation process by up to 598X speedup.
FSSUAVL: A Discriminative Framework using Vision Models for Federated Self-Supervised Audio and Image Understanding
Apr 13, 2025Recent studies have demonstrated that vision models can effectively learn multimodal audio-image representations when paired. However, the challenge of enabling deep models to learn representations from unpaired modalities remains unresolved. This issue is especially pertinent in scenarios like Federated Learning (FL), where data is often decentralized, heterogeneous, and lacks a reliable guarantee of paired data. Previous attempts tackled this issue through the use of auxiliary pretrained encoders or generative models on local clients, which invariably raise computational cost with increasing number modalities. Unlike these approaches, in this paper, we aim to address the task of unpaired audio and image recognition using \texttt{FSSUAVL}, a single deep model pretrained in FL with self-supervised contrastive learning (SSL). Instead of aligning the audio and image modalities, \texttt{FSSUAVL} jointly discriminates them by projecting them into a common embedding space using contrastive SSL. This extends the utility of \texttt{FSSUAVL} to paired and unpaired audio and image recognition tasks. Our experiments with CNN and ViT demonstrate that \texttt{FSSUAVL} significantly improves performance across various image- and audio-based downstream tasks compared to using separate deep models for each modality. Additionally, \texttt{FSSUAVL}'s capacity to learn multimodal feature representations allows for integrating auxiliary information, if available, to enhance recognition accuracy.
FedRepOpt: Gradient Re-parameterized Optimizers in Federated Learning
Sep 25, 2024Federated Learning (FL) has emerged as a privacy-preserving method for training machine learning models in a distributed manner on edge devices. However, on-device models face inherent computational power and memory limitations, potentially resulting in constrained gradient updates. As the model's size increases, the frequency of gradient updates on edge devices decreases, ultimately leading to suboptimal training outcomes during any particular FL round. This limits the feasibility of deploying advanced and large-scale models on edge devices, hindering the potential for performance enhancements. To address this issue, we propose FedRepOpt, a gradient re-parameterized optimizer for FL. The gradient re-parameterized method allows training a simple local model with a similar performance as a complex model by modifying the optimizer's gradients according to a set of model-specific hyperparameters obtained from the complex models. In this work, we focus on VGG-style and Ghost-style models in the FL environment. Extensive experiments demonstrate that models using FedRepOpt obtain a significant boost in performance of 16.7% and 11.4% compared to the RepGhost-style and RepVGG-style networks, while also demonstrating a faster convergence time of 11.7% and 57.4% compared to their complex structure.
R-Eval: A Unified Toolkit for Evaluating Domain Knowledge of Retrieval Augmented Large Language Models
Jun 17, 2024Large language models have achieved remarkable success on general NLP tasks, but they may fall short for domain-specific problems. Recently, various Retrieval-Augmented Large Language Models (RALLMs) are proposed to address this shortcoming. However, existing evaluation tools only provide a few baselines and evaluate them on various domains without mining the depth of domain knowledge. In this paper, we address the challenges of evaluating RALLMs by introducing the R-Eval toolkit, a Python toolkit designed to streamline the evaluation of different RAG workflows in conjunction with LLMs. Our toolkit, which supports popular built-in RAG workflows and allows for the incorporation of customized testing data on the specific domain, is designed to be user-friendly, modular, and extensible. We conduct an evaluation of 21 RALLMs across three task levels and two representative domains, revealing significant variations in the effectiveness of RALLMs across different tasks and domains. Our analysis emphasizes the importance of considering both task and domain requirements when choosing a RAG workflow and LLM combination. We are committed to continuously maintaining our platform at https://github.com/THU-KEG/R-Eval to facilitate both the industry and the researchers.
A Solution-based LLM API-using Methodology for Academic Information Seeking
May 24, 2024Applying large language models (LLMs) for academic API usage shows promise in reducing researchers' academic information seeking efforts. However, current LLM API-using methods struggle with complex API coupling commonly encountered in academic queries. To address this, we introduce SoAy, a solution-based LLM API-using methodology for academic information seeking. It uses code with a solution as the reasoning method, where a solution is a pre-constructed API calling sequence. The addition of the solution reduces the difficulty for the model to understand the complex relationships between APIs. Code improves the efficiency of reasoning. To evaluate SoAy, we introduce SoAyBench, an evaluation benchmark accompanied by SoAyEval, built upon a cloned environment of APIs from AMiner. Experimental results demonstrate a 34.58-75.99\% performance improvement compared to state-of-the-art LLM API-based baselines. All datasets, codes, tuned models, and deployed online services are publicly accessible at https://github.com/RUCKBReasoning/SoAy.
Exploring Federated Self-Supervised Learning for General Purpose Audio Understanding
Feb 05, 2024The integration of Federated Learning (FL) and Self-supervised Learning (SSL) offers a unique and synergetic combination to exploit the audio data for general-purpose audio understanding, without compromising user data privacy. However, rare efforts have been made to investigate the SSL models in the FL regime for general-purpose audio understanding, especially when the training data is generated by large-scale heterogeneous audio sources. In this paper, we evaluate the performance of feature-matching and predictive audio-SSL techniques when integrated into large-scale FL settings simulated with non-independently identically distributed (non-iid) data. We propose a novel Federated SSL (F-SSL) framework, dubbed FASSL, that enables learning intermediate feature representations from large-scale decentralized heterogeneous clients, holding unlabelled audio data. Our study has found that audio F-SSL approaches perform on par with the centralized audio-SSL approaches on the audio-retrieval task. Extensive experiments demonstrate the effectiveness and significance of FASSL as it assists in obtaining the optimal global model for state-of-the-art FL aggregation methods.
AudioInceptionNeXt: TCL AI LAB Submission to EPIC-SOUND Audio-Based-Interaction-Recognition Challenge 2023
Jul 14, 2023This report presents the technical details of our submission to the 2023 Epic-Kitchen EPIC-SOUNDS Audio-Based Interaction Recognition Challenge. The task is to learn the mapping from audio samples to their corresponding action labels. To achieve this goal, we propose a simple yet effective single-stream CNN-based architecture called AudioInceptionNeXt that operates on the time-frequency log-mel-spectrogram of the audio samples. Motivated by the design of the InceptionNeXt, we propose parallel multi-scale depthwise separable convolutional kernels in the AudioInceptionNeXt block, which enable the model to learn the time and frequency information more effectively. The large-scale separable kernels capture the long duration of activities and the global frequency semantic information, while the small-scale separable kernels capture the short duration of activities and local details of frequency information. Our approach achieved 55.43% of top-1 accuracy on the challenge test set, ranked as 1st on the public leaderboard. Codes are available anonymously at https://github.com/StevenLauHKHK/AudioInceptionNeXt.git.
Efficient Model-Based Collaborative Filtering with Fast Adaptive PCA
Sep 04, 2020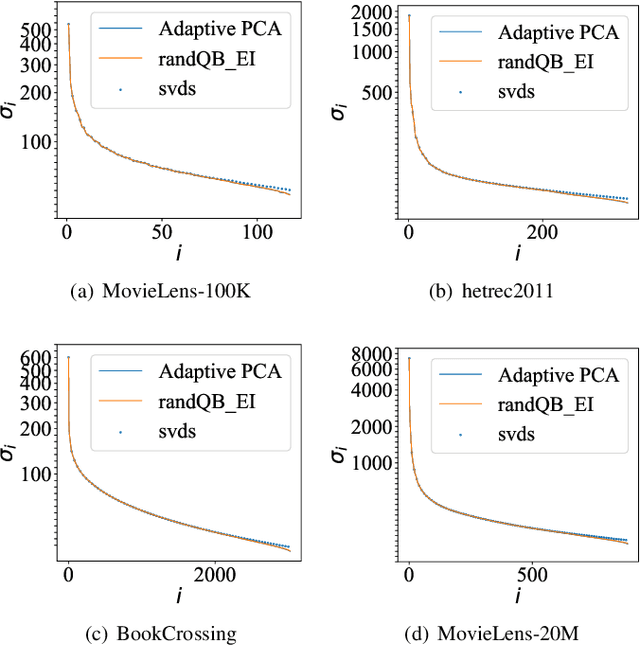
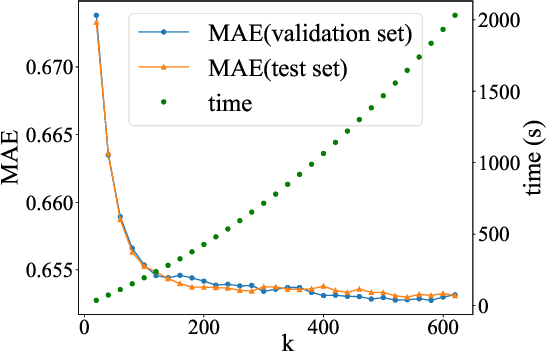
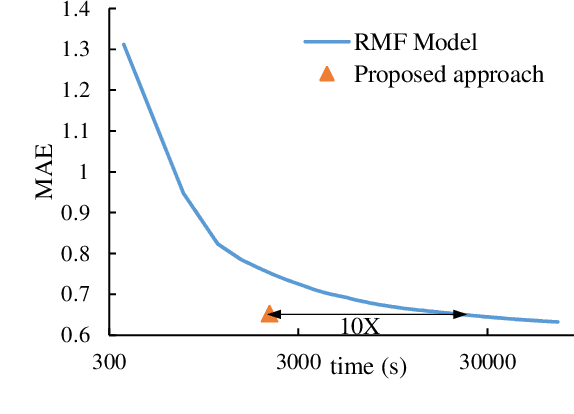
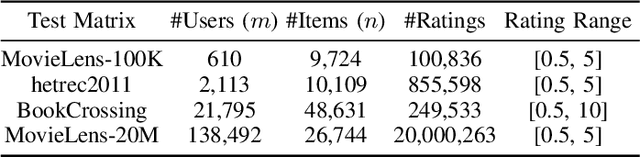
A model-based collaborative filtering (CF) approach utilizing fast adaptive randomized singular value decomposition (SVD) is proposed for the matrix completion problem in recommender system. Firstly, a fast adaptive PCA frameworkis presented which combines the fixed-precision randomized matrix factorization algorithm [1] and accelerating skills for handling large sparse data. Then, a novel termination mechanism for the adaptive PCA is proposed to automatically determine a number of latent factors for achieving the near optimal prediction accuracy during the subsequent model-based CF. The resulted CF approach has good accuracy while inheriting high runtime efficiency. Experiments on real data show that, the proposed adaptive PCA is up to 2.7X and 6.7X faster than the original fixed-precision SVD approach [1] and svds in Matlab repsectively, while preserving accuracy. The proposed model-based CF approach is able to efficiently process the MovieLens data with 20M ratings and exhibits more than 10X speedup over the regularized matrix factorization based approach [2] and the fast singular value thresholding approach [3] with comparable or better accuracy. It also owns the advantage of parameter free. Compared with the deep-learning-based CF approach, the proposed approach is much more computationally efficient, with just marginal performance loss.
Fast Randomized PCA for Sparse Data
Oct 16, 2018
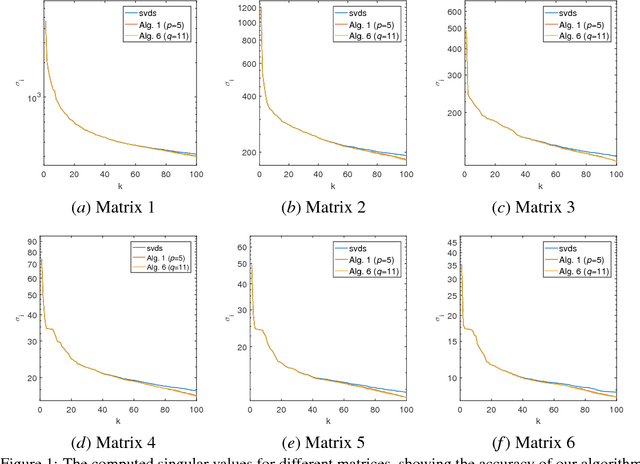

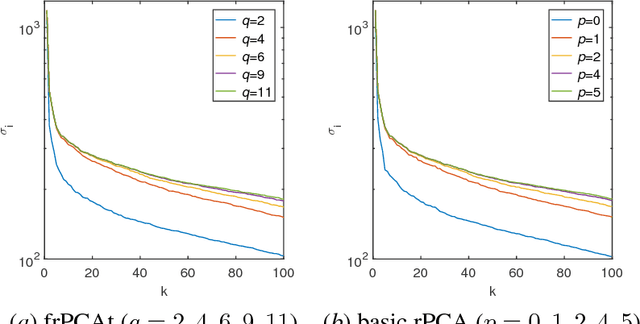
Principal component analysis (PCA) is widely used for dimension reduction and embedding of real data in social network analysis, information retrieval, and natural language processing, etc. In this work we propose a fast randomized PCA algorithm for processing large sparse data. The algorithm has similar accuracy to the basic randomized SVD (rPCA) algorithm (Halko et al., 2011), but is largely optimized for sparse data. It also has good flexibility to trade off runtime against accuracy for practical usage. Experiments on real data show that the proposed algorithm is up to 9.1X faster than the basic rPCA algorithm without accuracy loss, and is up to 20X faster than the svds in Matlab with little error. The algorithm computes the first 100 principal components of a large information retrieval data with 12,869,521 persons and 323,899 keywords in less than 400 seconds on a 24-core machine, while all conventional methods fail due to the out-of-memory issue.