 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapBench: A Multi-PDK Dataset for Machine-Learning-Based Post-Layout Capacitance Extraction
Apr 13, 2026We present CapBench, a fully reproducible, multi-PDK dataset for capacitance extraction. The dataset is derived from open-source designs, including single-core CPUs, systems-on-chip, and media accelerators. All designs are fully placed and routed using 14 independent OpenROAD flow runs spanning three technology nodes: ASAP7, NanGate45, and Sky130HD. From these layouts, we extract 61,855 3D windows across three size tiers to enable transfer learning and scalability studies. High-fidelity capacitance labels are generated using RWCap, a state-of-the-art random-walk solver, and validated against the industry-standard Raphael, achieving a mean absolute error of 0.64% for total capacitance. Each window is pre-processed into density maps, graph representations, and point clouds. We evaluate 10 machine learning architectures that illustrate dataset usage and serve as baselines, including convolutional neural networks (CNNs), point cloud transformers, and graph neural networks (GNNs). CNNs demonstrate the lowest errors (1.75%), while GNNs are up to 41.4x faster but exhibit larger errors (10.2%), illustrating a clear accuracy-speed trade-off. Code and dataset are available at https://github.com/THU-numbda/CapBench.
DeepRWCap: Neural-Guided Random-Walk Capacitance Solver for IC Design
Nov 10, 2025

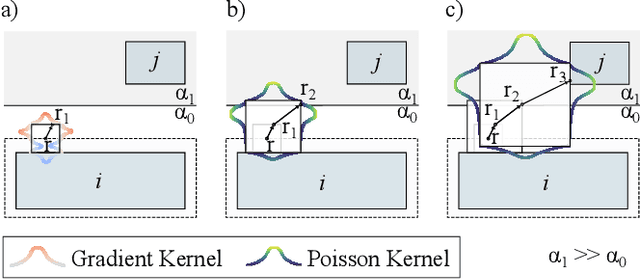
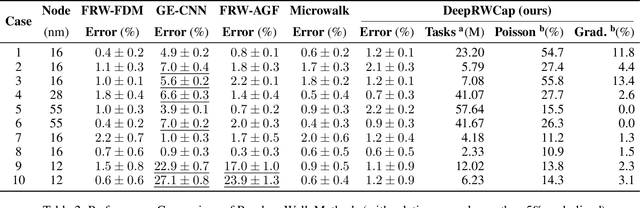
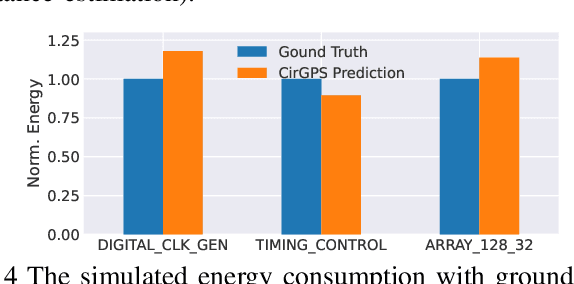
Monte Carlo random walk methods are widely used in capacitance extraction for their mesh-free formulation and inherent parallelism. However, modern semiconductor technologies with densely packed structures present significant challenges in unbiasedly sampling transition domains in walk steps with multiple high-contrast dielectric materials. We present DeepRWCap, a machine learning-guided random walk solver that predicts the transition quantities required to guide each step of the walk. These include Poisson kernels, gradient kernels, signs and magnitudes of weights. DeepRWCap employs a two-stage neural architecture that decomposes structured outputs into face-wise distributions and spatial kernels on cube faces. It uses 3D convolutional networks to capture volumetric dielectric interactions and 2D depthwise separable convolutions to model localized kernel behavior. The design incorporates grid-based positional encodings and structural design choices informed by cube symmetries to reduce learning redundancy and improve generalization. Trained on 100,000 procedurally generated dielectric configurations, DeepRWCap achieves a mean relative error of $1.24\pm0.53$\% when benchmarked against the commercial Raphael solver on the self-capacitance estimation of 10 industrial designs spanning 12 to 55 nm nodes. Compared to the state-of-the-art stochastic difference method Microwalk, DeepRWCap achieves an average 23\% speedup. On complex designs with runtimes over 10 s, it reaches an average 49\% acceleration.
Few-shot Learning on AMS Circuits and Its Application to Parasitic Capacitance Prediction
Jul 09, 2025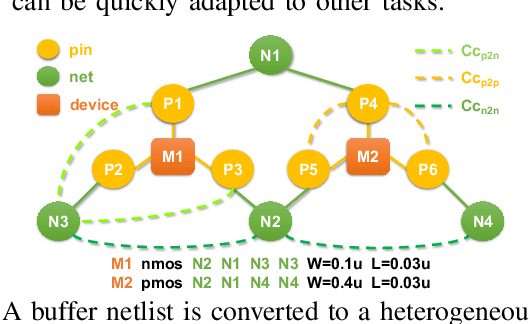
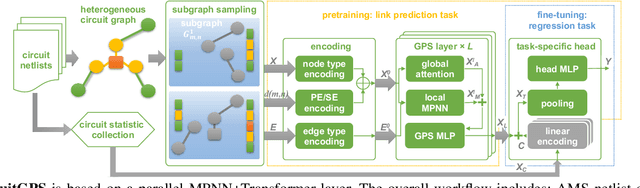
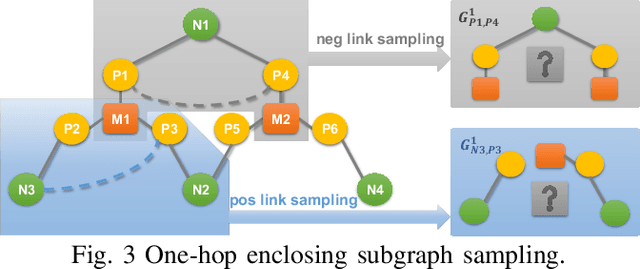
Graph representation learning is a powerful method to extract features from graph-structured data, such as analog/mixed-signal (AMS) circuits. However, training deep learning models for AMS designs is severely limited by the scarcity of integrated circuit design data. In this work, we present CircuitGPS, a few-shot learning method for parasitic effect prediction in AMS circuits. The circuit netlist is represented as a heterogeneous graph, with the coupling capacitance modeled as a link. CircuitGPS is pre-trained on link prediction and fine-tuned on edge regression. The proposed method starts with a small-hop sampling technique that converts a link or a node into a subgraph. Then, the subgraph embeddings are learned with a hybrid graph Transformer. Additionally, CircuitGPS integrates a low-cost positional encoding that summarizes the positional and structural information of the sampled subgraph. CircuitGPS improves the accuracy of coupling existence by at least 20\% and reduces the MAE of capacitance estimation by at least 0.067 compared to existing methods. Our method demonstrates strong inherent scalability, enabling direct application to diverse AMS circuit designs through zero-shot learning. Furthermore, the ablation studies provide valuable insights into graph models for representation learning.
Deep-Learning-Based Pre-Layout Parasitic Capacitance Prediction on SRAM Designs
Jul 09, 2025To achieve higher system energy efficiency, SRAM in SoCs is often customized. The parasitic effects cause notable discrepancies between pre-layout and post-layout circuit simulations, leading to difficulty in converging design parameters and excessive design iterations. Is it possible to well predict the parasitics based on the pre-layout circuit, so as to perform parasitic-aware pre-layout simulation? In this work, we propose a deep-learning-based 2-stage model to accurately predict these parasitics in pre-layout stages. The model combines a Graph Neural Network (GNN) classifier and Multi-Layer Perceptron (MLP) regressors, effectively managing class imbalance of the net parasitics in SRAM circuits. We also employ Focal Loss to mitigate the impact of abundant internal net samples and integrate subcircuit information into the graph to abstract the hierarchical structure of schematics. Experiments on 4 real SRAM designs show that our approach not only surpasses the state-of-the-art model in parasitic prediction by a maximum of 19X reduction of error but also significantly boosts the simulation process by up to 598X speedup.
Transferable Parasitic Estimation via Graph Contrastive Learning and Label Rebalancing in AMS Circuits
Jul 09, 2025Graph representation learning on Analog-Mixed Signal (AMS) circuits is crucial for various downstream tasks, e.g., parasitic estimation. However, the scarcity of design data, the unbalanced distribution of labels, and the inherent diversity of circuit implementations pose significant challenges to learning robust and transferable circuit representations. To address these limitations, we propose CircuitGCL, a novel graph contrastive learning framework that integrates representation scattering and label rebalancing to enhance transferability across heterogeneous circuit graphs. CircuitGCL employs a self-supervised strategy to learn topology-invariant node embeddings through hyperspherical representation scattering, eliminating dependency on large-scale data. Simultaneously, balanced mean squared error (MSE) and softmax cross-entropy (bsmCE) losses are introduced to mitigate label distribution disparities between circuits, enabling robust and transferable parasitic estimation. Evaluated on parasitic capacitance estimation (edge-level task) and ground capacitance classification (node-level task) across TSMC 28nm AMS designs, CircuitGCL outperforms all state-of-the-art (SOTA) methods, with the $R^2$ improvement of $33.64\% \sim 44.20\%$ for edge regression and F1-score gain of $0.9\times \sim 2.1\times$ for node classification. Our code is available at \href{https://anonymous.4open.science/r/CircuitGCL-099B/README.md}{here}.
NAS-Cap: Deep-Learning Driven 3-D Capacitance Extraction with Neural Architecture Search and Data Augmentation
Aug 23, 2024



More accurate capacitance extraction is demanded for designing integrated circuits under advanced process technology. The pattern matching approach and the field solver for capacitance extraction have the drawbacks of inaccuracy and large computational cost, respectively. Recent work \cite{yang2023cnn} proposes a grid-based data representation and a convolutional neural network (CNN) based capacitance models (called CNN-Cap), which opens the third way for 3-D capacitance extraction to get accurate results with much less time cost than field solver. In this work, the techniques of neural architecture search (NAS) and data augmentation are proposed to train better CNN models for 3-D capacitance extraction. Experimental results on datasets from different designs show that the obtained NAS-Cap models achieve remarkably higher accuracy than CNN-Cap, while consuming less runtime for inference and space for model storage. Meanwhile, the transferability of the NAS is validated, as the once searched architecture brought similar error reduction on coupling/total capacitance for the test cases from different design and/or process technology.
Cheating Suffix: Targeted Attack to Text-To-Image Diffusion Models with Multi-Modal Priors
Feb 02, 2024Diffusion models have been widely deployed in various image generation tasks, demonstrating an extraordinary connection between image and text modalities. However, they face challenges of being maliciously exploited to generate harmful or sensitive images by appending a specific suffix to the original prompt. Existing works mainly focus on using single-modal information to conduct attacks, which fails to utilize multi-modal features and results in less than satisfactory performance. Integrating multi-modal priors (MMP), i.e. both text and image features, we propose a targeted attack method named MMP-Attack in this work. Specifically, the goal of MMP-Attack is to add a target object into the image content while simultaneously removing the original object. The MMP-Attack shows a notable advantage over existing works with superior universality and transferability, which can effectively attack commercial text-to-image (T2I) models such as DALL-E 3. To the best of our knowledge, this marks the first successful attempt of transfer-based attack to commercial T2I models. Our code is publicly available at \url{https://github.com/ydc123/MMP-Attack}.
Generating Adversarial Examples with Better Transferability via Masking Unimportant Parameters of Surrogate Model
Apr 14, 2023Deep neural networks (DNNs) have been shown to be vulnerable to adversarial examples. Moreover, the transferability of the adversarial examples has received broad attention in recent years, which means that adversarial examples crafted by a surrogate model can also attack unknown models. This phenomenon gave birth to the transfer-based adversarial attacks, which aim to improve the transferability of the generated adversarial examples. In this paper, we propose to improve the transferability of adversarial examples in the transfer-based attack via masking unimportant parameters (MUP). The key idea in MUP is to refine the pretrained surrogate models to boost the transfer-based attack. Based on this idea, a Taylor expansion-based metric is used to evaluate the parameter importance score and the unimportant parameters are masked during the generation of adversarial examples. This process is simple, yet can be naturally combined with various existing gradient-based optimizers for generating adversarial examples, thus further improving the transferability of the generated adversarial examples. Extensive experiments are conducted to validate the effectiveness of the proposed MUP-based methods.
Boosting the Adversarial Transferability of Surrogate Model with Dark Knowledge
Jun 16, 2022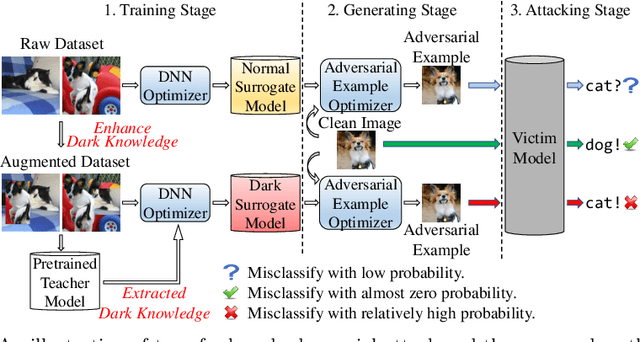
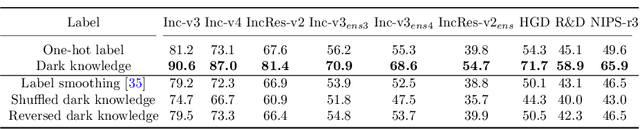
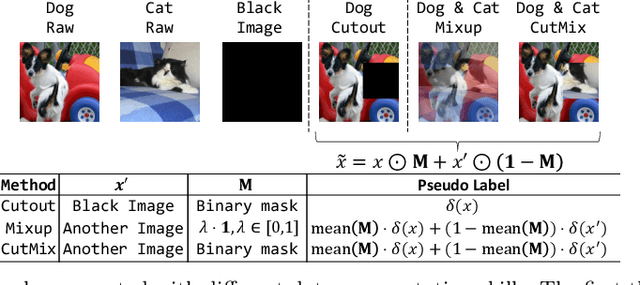
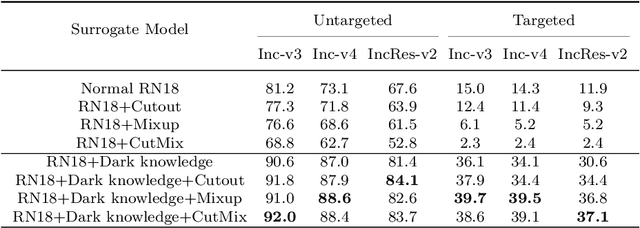
Deep neural networks (DNNs) for image classification are known to be vulnerable to adversarial examples. And, the adversarial examples have transferability, which means an adversarial example for a DNN model can fool another black-box model with a non-trivial probability. This gave birth of the transfer-based adversarial attack where the adversarial examples generated by a pretrained or known model (called surrogate model) are used to conduct black-box attack. There are some work on how to generate the adversarial examples from a given surrogate model to achieve better transferability. However, training a special surrogate model to generate adversarial examples with better transferability is relatively under-explored. In this paper, we propose a method of training a surrogate model with abundant dark knowledge to boost the adversarial transferability of the adversarial examples generated by the surrogate model. This trained surrogate model is named dark surrogate model (DSM), and the proposed method to train DSM consists of two key components: a teacher model extracting dark knowledge and providing soft labels, and the mixing augmentation skill which enhances the dark knowledge of training data. Extensive experiments have been conducted to show that the proposed method can substantially improve the adversarial transferability of surrogate model across different architectures of surrogate model and optimizers for generating adversarial examples. We also show that the proposed method can be applied to other scenarios of transfer-based attack that contain dark knowledge, like face verification.
CNN-Cap: Effective Convolutional Neural Network Based Capacitance Models for Full-Chip Parasitic Extraction
Jul 14, 2021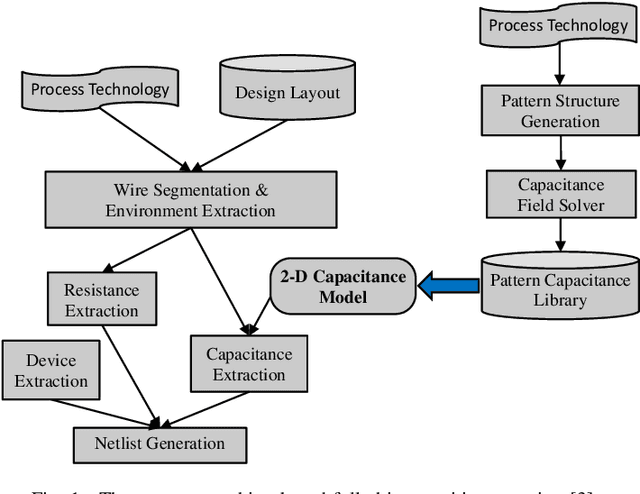
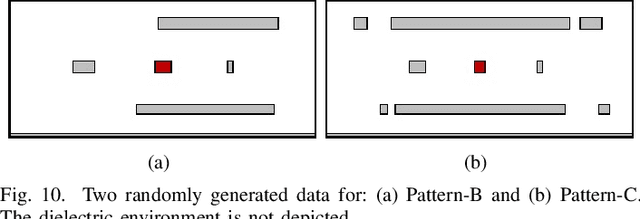
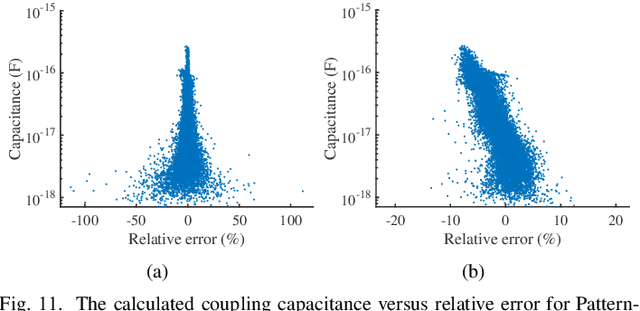
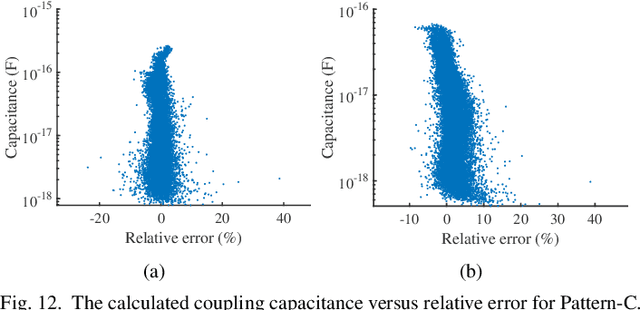
Accurate capacitance extraction is becoming more important for designing integrated circuits under advanced process technology. The pattern matching based full-chip extraction methodology delivers fast computational speed, but suffers from large error, and tedious efforts on building capacitance models of the increasing structure patterns. In this work, we propose an effective method for building convolutional neural network (CNN) based capacitance models (called CNN-Cap) for two-dimensional (2-D) structures in full-chip capacitance extraction. With a novel grid-based data representation, the proposed method is able to model the pattern with a variable number of conductors, so that largely reduce the number of patterns. Based on the ability of ResNet architecture on capturing spatial information and the proposed training skills, the obtained CNN-Cap exhibits much better performance over the multilayer perception neural network based capacitance model while being more versatile. Extensive experiments on a 55nm and a 15nm process technologies have demonstrated that the error of total capacitance produced with CNN-Cap is always within 1.3% and the error of produced coupling capacitance is less than 10% in over 99.5% probability. CNN-Cap runs more than 4000X faster than 2-D field solver on a GPU server, while it consumes negligible memory compared to the look-up table based capacitance model.