 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Anomaly Detection
Jan 30, 2023Anomaly detection is critical for finding suspicious behavior in innumerable systems. We need to detect anomalies in real-time, i.e. determine if an incoming entity is anomalous or not, as soon as we receive it, to minimize the effects of malicious activities and start recovery as soon as possible. Therefore, online algorithms that can detect anomalies in a streaming manner are essential. We first propose MIDAS which uses a count-min sketch to detect anomalous edges in dynamic graphs in an online manner, using constant time and memory. We then propose two variants, MIDAS-R which incorporates temporal and spatial relations, and MIDAS-F which aims to filter away anomalous edges to prevent them from negatively affecting the internal data structures. We then extend the count-min sketch to a Higher-Order sketch to capture complex relations in graph data, and to reduce detecting suspicious dense subgraph problem to finding a dense submatrix in constant time. Using this sketch, we propose four streaming methods to detect edge and subgraph anomalies. Next, we broaden the graph setting to multi-aspect data. We propose MStream which detects explainable anomalies in multi-aspect data streams. We further propose MStream-PCA, MStream-IB, and MStream-AE to incorporate correlation between features. Finally, we consider multi-dimensional data streams with concept drift and propose MemStream. MemStream leverages the power of a denoising autoencoder to learn representations and a memory module to learn the dynamically changing trend in data without the need for labels. We prove a theoretical bound on the size of memory for effective drift handling. In addition, we allow quick retraining when the arriving stream becomes sufficiently different from the training data. Furthermore, MemStream makes use of two architecture design choices to be robust to memory poisoning.
SSMF: Shifting Seasonal Matrix Factorization
Oct 25, 2021
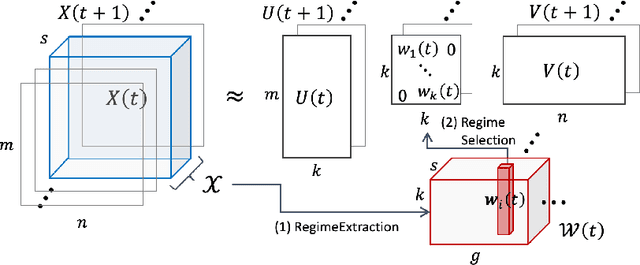

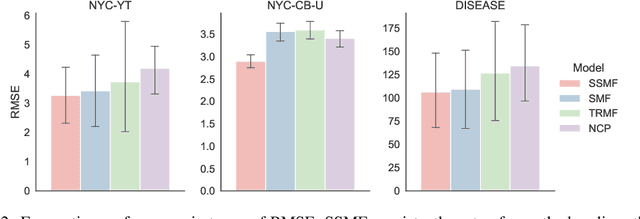
Given taxi-ride counts information between departure and destination locations, how can we forecast their future demands? In general, given a data stream of events with seasonal patterns that innovate over time, how can we effectively and efficiently forecast future events? In this paper, we propose Shifting Seasonal Matrix Factorization approach, namely SSMF, that can adaptively learn multiple seasonal patterns (called regimes), as well as switching between them. Our proposed method has the following properties: (a) it accurately forecasts future events by detecting regime shifts in seasonal patterns as the data stream evolves; (b) it works in an online setting, i.e., processes each observation in constant time and memory; (c) it effectively realizes regime shifts without human intervention by using a lossless data compression scheme. We demonstrate that our algorithm outperforms state-of-the-art baseline methods by accurately forecasting upcoming events on three real-world data streams.
GraphAnoGAN: Detecting Anomalous Snapshots from Attributed Graphs
Jun 29, 2021
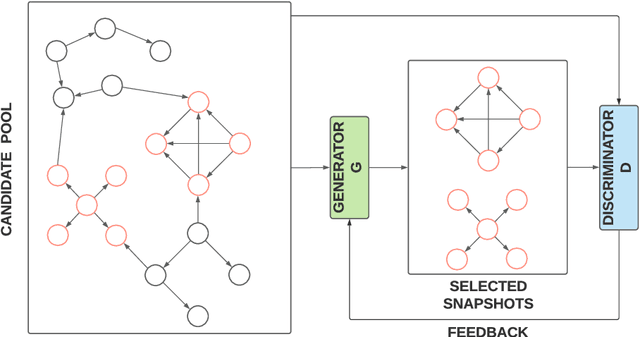
Finding anomalous snapshots from a graph has garnered huge attention recently. Existing studies address the problem using shallow learning mechanisms such as subspace selection, ego-network, or community analysis. These models do not take into account the multifaceted interactions between the structure and attributes in the network. In this paper, we propose GraphAnoGAN, an anomalous snapshot ranking framework, which consists of two core components -- generative and discriminative models. Specifically, the generative model learns to approximate the distribution of anomalous samples from the candidate set of graph snapshots, and the discriminative model detects whether the sampled snapshot is from the ground-truth or not. Experiments on 4 real-world networks show that GraphAnoGAN outperforms 6 baselines with a significant margin (28.29% and 22.01% higher precision and recall, respectively compared to the best baseline, averaged across all datasets).
Sketch-Based Streaming Anomaly Detection in Dynamic Graphs
Jun 08, 2021
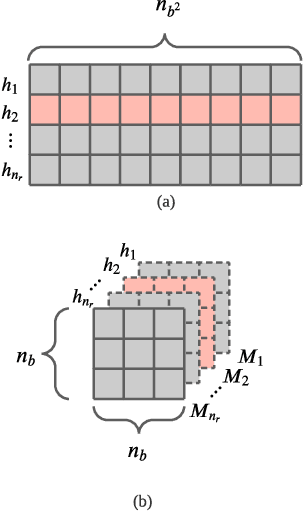
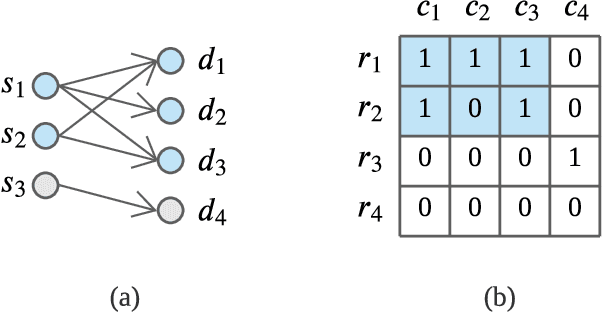

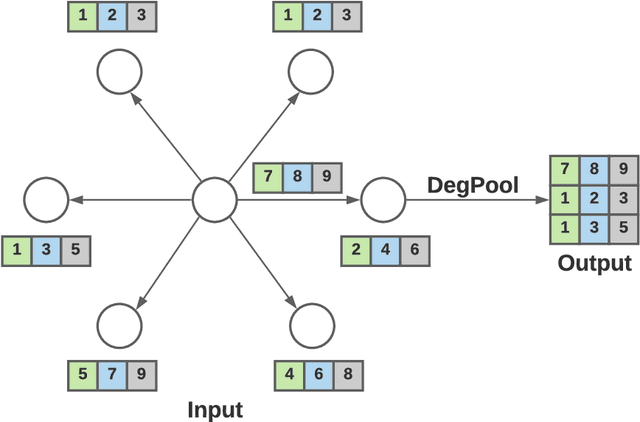
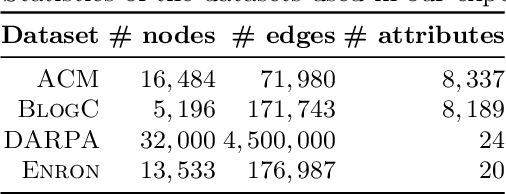
Given a stream of graph edges from a dynamic graph, how can we assign anomaly scores to edges and subgraphs in an online manner, for the purpose of detecting unusual behavior, using constant time and memory? For example, in intrusion detection, existing work seeks to detect either anomalous edges or anomalous subgraphs, but not both. In this paper, we first extend the count-min sketch data structure to a higher-order sketch. This higher-order sketch has the useful property of preserving the dense subgraph structure (dense subgraphs in the input turn into dense submatrices in the data structure). We then propose four online algorithms that utilize this enhanced data structure, which (a) detect both edge and graph anomalies; (b) process each edge and graph in constant memory and constant update time per newly arriving edge, and; (c) outperform state-of-the-art baselines on four real-world datasets. Our method is the first streaming approach that incorporates dense subgraph search to detect graph anomalies in constant memory and time.
MemStream: Memory-Based Anomaly Detection in Multi-Aspect Streams with Concept Drift
Jun 07, 2021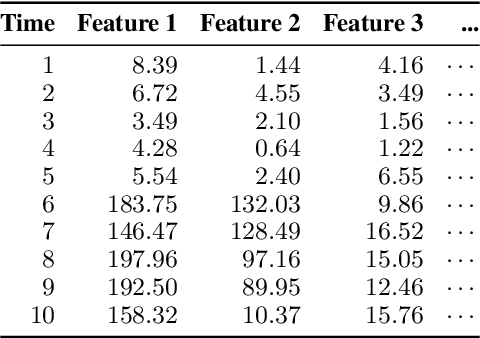
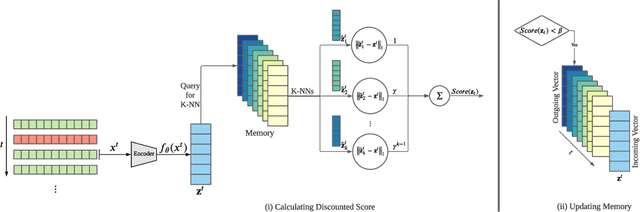
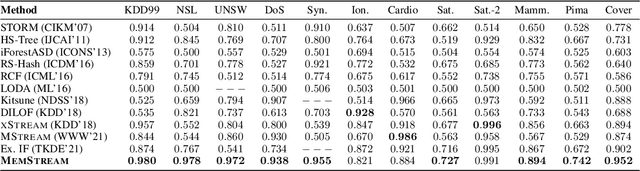
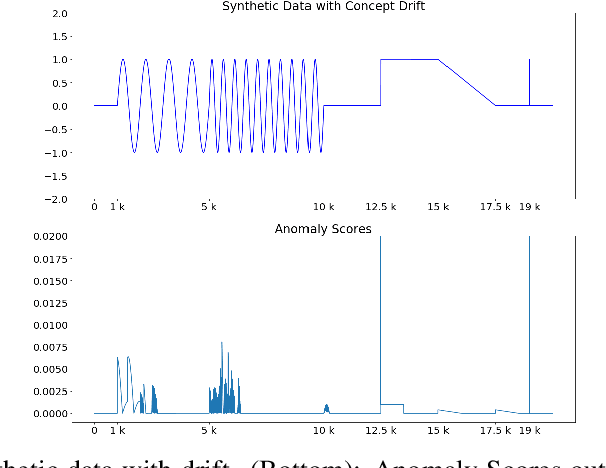
Given a stream of entries over time in a multi-aspect data setting where concept drift is present, how can we detect anomalous activities? Most of the existing unsupervised anomaly detection approaches seek to detect anomalous events in an offline fashion and require a large amount of data for training. This is not practical in real-life scenarios where we receive the data in a streaming manner and do not know the size of the stream beforehand. Thus, we need a data-efficient method that can detect and adapt to changing data trends, or concept drift, in an online manner. In this work, we propose MemStream, a streaming multi-aspect anomaly detection framework, allowing us to detect unusual events as they occur while being resilient to concept drift. We leverage the power of a denoising autoencoder to learn representations and a memory module to learn the dynamically changing trend in data without the need for labels. We prove the optimum memory size required for effective drift handling. Furthermore, MemStream makes use of two architecture design choices to be robust to memory poisoning. Experimental results show the effectiveness of our approach compared to state-of-the-art streaming baselines using 2 synthetic datasets and 11 real-world datasets.
Isconna: Streaming Anomaly Detection with Frequency and Patterns
Apr 04, 2021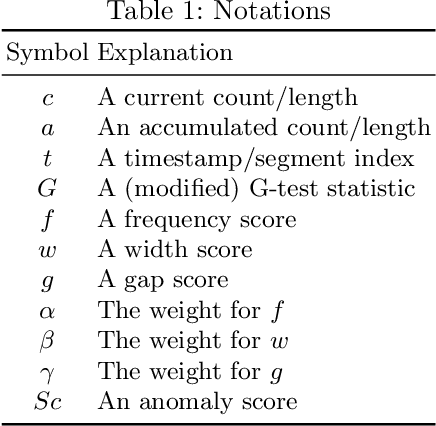
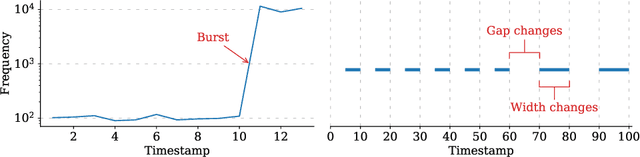
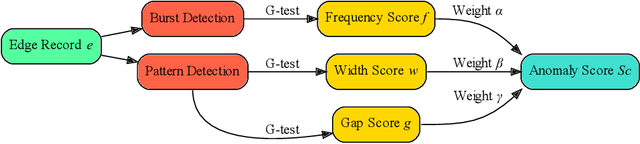
An edge stream is a common form of presentation of dynamic networks. It can evolve with time, with new types of nodes or edges being continuously added. Existing methods for anomaly detection rely on edge occurrence counts or compare pattern snippets found in historical records. In this work, we propose Isconna, which focuses on both the frequency and the pattern of edge records. The burst detection component targets anomalies between individual timestamps, while the pattern detection component highlights anomalies across segments of timestamps. These two components together produce three intermediate scores, which are aggregated into the final anomaly score. Isconna does not actively explore or maintain pattern snippets; it instead measures the consecutive presence and absence of edge records. Isconna is an online algorithm, it does not keep the original information of edge records; only statistical values are maintained in a few count-min sketches (CMS). Isconna's space complexity $O(rc)$ is determined by two user-specific parameters, the size of CMSs. In worst case, Isconna's time complexity can be up to $O(rc)$, but it can be amortized in practice. Experiments show that Isconna outperforms five state-of-the-art frequency- and/or pattern-based baselines on six real-world datasets with up to 20 million edge records.
CAC: A Clustering Based Framework for Classification
Feb 23, 2021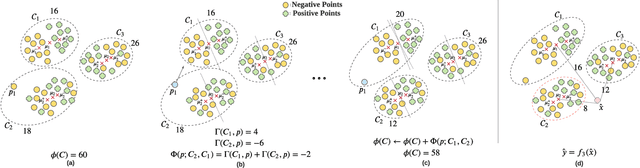
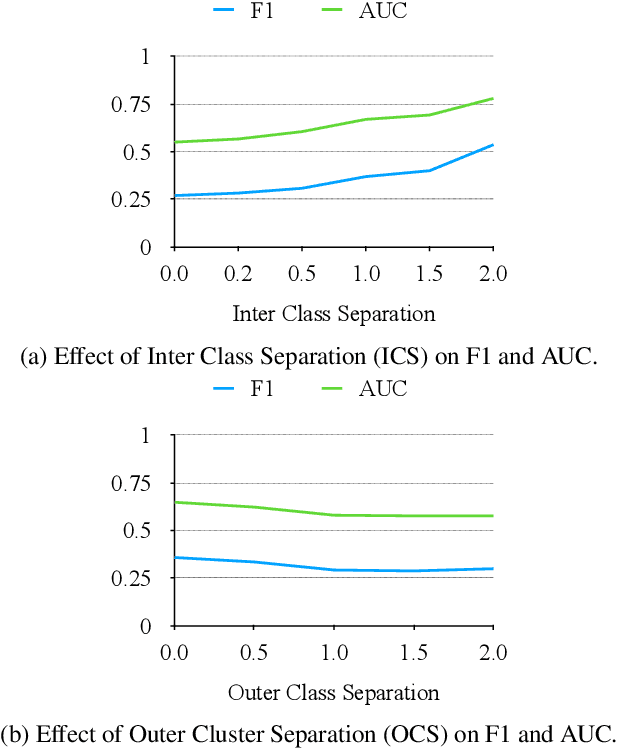
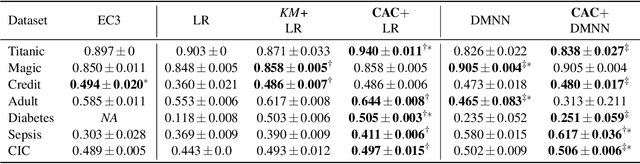
In data containing heterogeneous subpopulations, classification performance benefits from incorporating the knowledge of cluster structure in the classifier. Previous methods for such combined clustering and classification either are classifier-specific and not generic or independently perform clustering and classifier training, which may not form clusters that can potentially benefit classifier performance. The question of how to perform clustering to improve the performance of classifiers trained on the clusters has received scant attention in previous literature despite its importance in several real-world applications. In this paper, we theoretically analyze when and how clustering may help in obtaining accurate classifiers. We design a simple, efficient, and generic framework called Classification Aware Clustering (CAC), to find clusters that are well suited for being used as training datasets by classifiers for each underlying subpopulation. Our experiments on synthetic and real benchmark datasets demonstrate the efficacy of CAC over previous methods for combined clustering and classification.
AugSplicing: Synchronized Behavior Detection in Streaming Tensors
Jan 05, 2021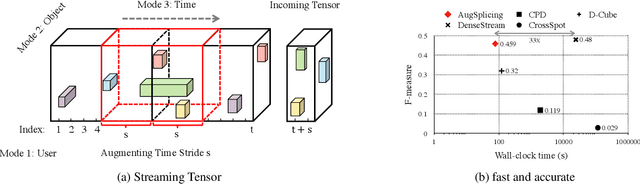
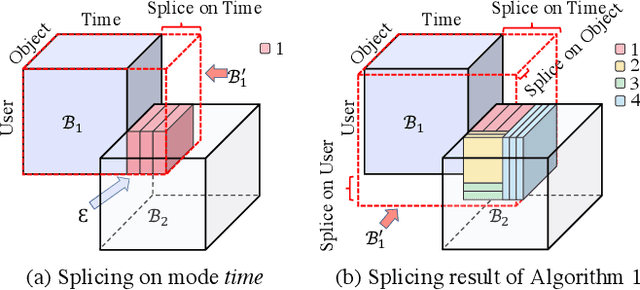
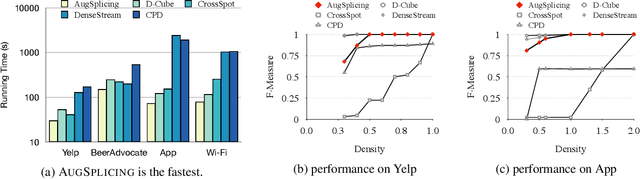
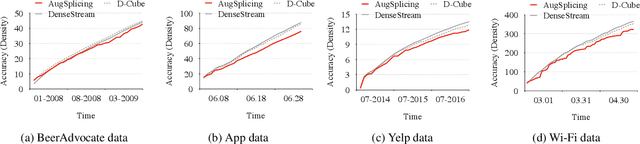
How can we track synchronized behavior in a stream of time-stamped tuples, such as mobile devices installing and uninstalling applications in the lockstep, to boost their ranks in the app store? We model such tuples as entries in a streaming tensor, which augments attribute sizes in its modes over time. Synchronized behavior tends to form dense blocks (i.e. subtensors) in such a tensor, signaling anomalous behavior, or interesting communities. However, existing dense block detection methods are either based on a static tensor, or lack an efficient algorithm in a streaming setting. Therefore, we propose a fast streaming algorithm, AugSplicing, which can detect the top dense blocks by incrementally splicing the previous detection with the incoming ones in new tuples, avoiding re-runs over all the history data at every tracking time step. AugSplicing is based on a splicing condition that guides the algorithm (Section 4). Compared to the state-of-the-art methods, our method is (1) effective to detect fraudulent behavior in installing data of real-world apps and find a synchronized group of students with interesting features in campus Wi-Fi data; (2) robust with splicing theory for dense block detection; (3) streaming and faster than the existing streaming algorithm, with closely comparable accuracy.
ExGAN: Adversarial Generation of Extreme Samples
Sep 17, 2020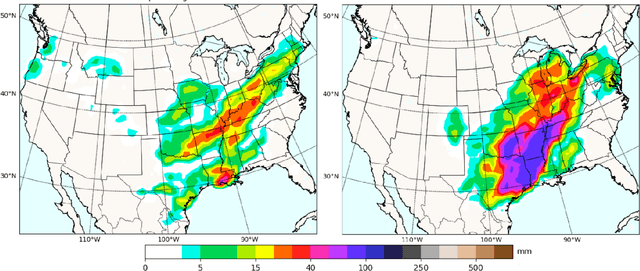

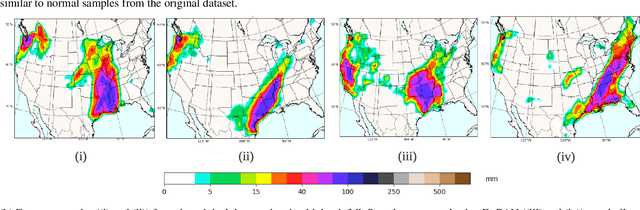
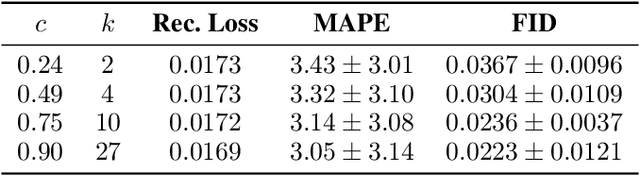
Mitigating the risk arising from extreme events is a fundamental goal with many applications, such as the modelling of natural disasters, financial crashes, epidemics, and many others. To manage this risk, a vital step is to be able to understand or generate a wide range of extreme scenarios. Existing approaches based on Generative Adversarial Networks (GANs) excel at generating realistic samples, but seek to generate typical samples, rather than extreme samples. Hence, in this work, we propose ExGAN, a GAN-based approach to generate realistic and extreme samples. To model the extremes of the training distribution in a principled way, our work draws from Extreme Value Theory (EVT), a probabilistic approach for modelling the extreme tails of distributions. For practical utility, our framework allows the user to specify both the desired extremeness measure, as well as the desired extremeness probability they wish to sample at. Experiments on real US Precipitation data show that our method generates realistic samples, based on visual inspection and quantitative measures, in an efficient manner. Moreover, generating increasingly extreme examples using ExGAN can be done in constant time (with respect to the extremeness probability), as opposed to the exponential time required by the baseline approach.
Real-Time Streaming Anomaly Detection in Dynamic Graphs
Sep 17, 2020
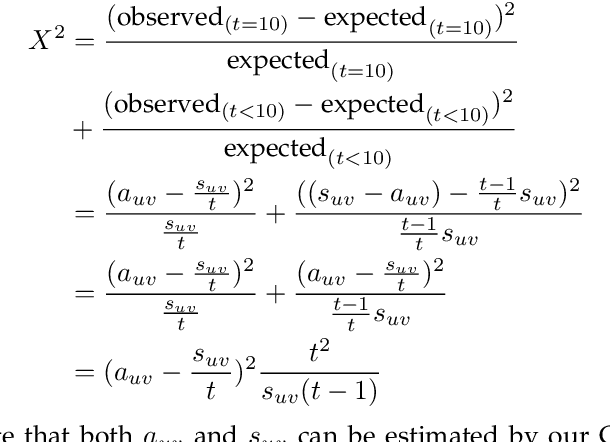
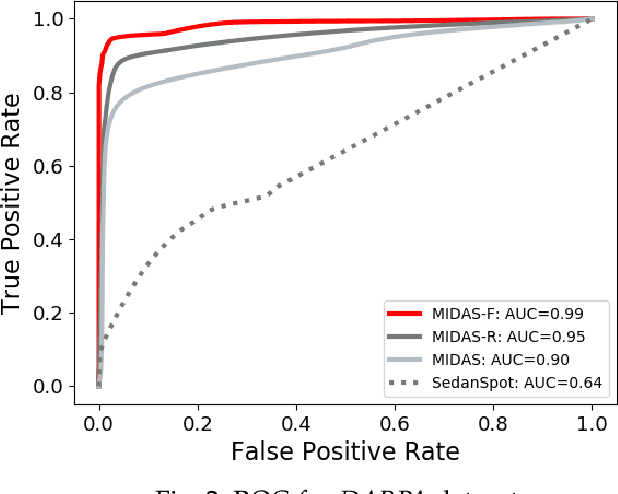
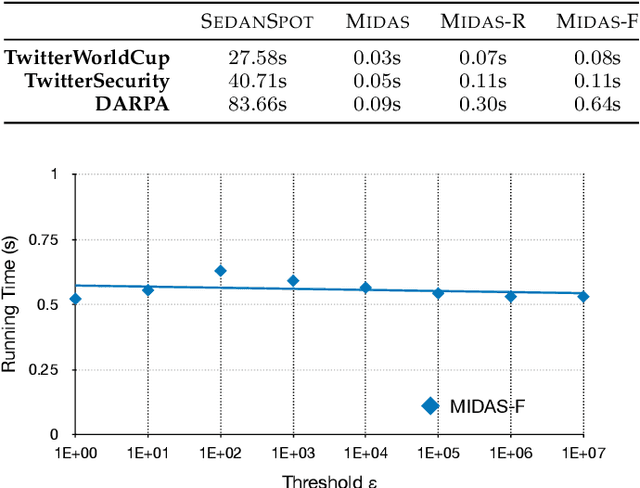
Given a stream of graph edges from a dynamic graph, how can we assign anomaly scores to edges in an online manner, for the purpose of detecting unusual behavior, using constant time and memory? Existing approaches aim to detect individually surprising edges. In this work, we propose MIDAS, which focuses on detecting microcluster anomalies, or suddenly arriving groups of suspiciously similar edges, such as lockstep behavior, including denial of service attacks in network traffic data. We further propose MIDAS-F, to solve the problem by which anomalies are incorporated into the algorithm's internal states, creating a 'poisoning' effect which can allow future anomalies to slip through undetected. MIDAS-F introduces two modifications: 1) We modify the anomaly scoring function, aiming to reduce the 'poisoning' effect of newly arriving edges; 2) We introduce a conditional merge step, which updates the algorithm's data structures after each time tick, but only if the anomaly score is below a threshold value, also to reduce the `poisoning' effect. Experiments show that MIDAS-F has significantly higher accuracy than MIDAS. MIDAS has the following properties: (a) it detects microcluster anomalies while providing theoretical guarantees about its false positive probability; (b) it is online, thus processing each edge in constant time and constant memory, and also processes the data 130 to 929 times faster than state-of-the-art approaches; (c) it provides 41% to 55% higher accuracy (in terms of ROC-AUC) than state-of-the-art approaches.