 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpliceOut: A Simple and Efficient Audio Augmentation Method
Oct 13, 2021
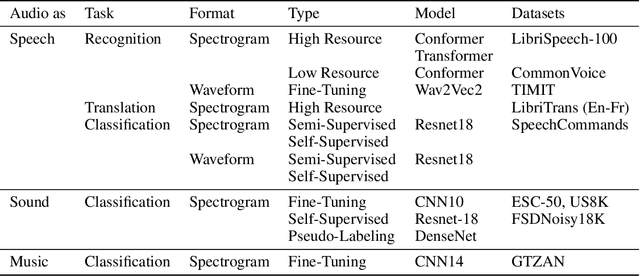
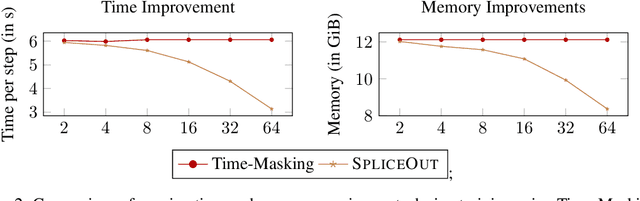
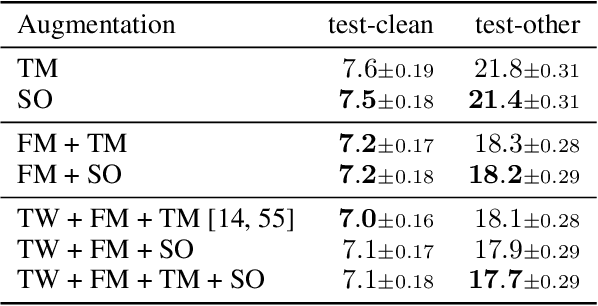
Time masking has become a de facto augmentation technique for speech and audio tasks, including automatic speech recognition (ASR) and audio classification, most notably as a part of SpecAugment. In this work, we propose SpliceOut, a simple modification to time masking which makes it computationally more efficient. SpliceOut performs comparably to (and sometimes outperforms) SpecAugment on a wide variety of speech and audio tasks, including ASR for seven different languages using varying amounts of training data, as well as on speech translation, sound and music classification, thus establishing itself as a broadly applicable audio augmentation method. SpliceOut also provides additional gains when used in conjunction with other augmentation techniques. Apart from the fully-supervised setting, we also demonstrate that SpliceOut can complement unsupervised representation learning with performance gains in the semi-supervised and self-supervised settings.
MemStream: Memory-Based Anomaly Detection in Multi-Aspect Streams with Concept Drift
Jun 07, 2021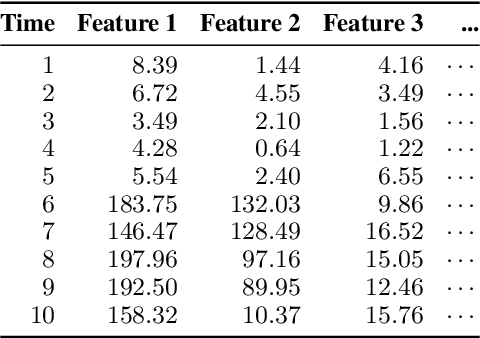
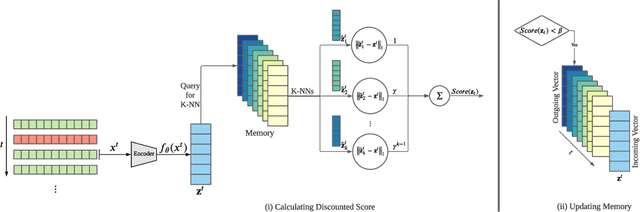
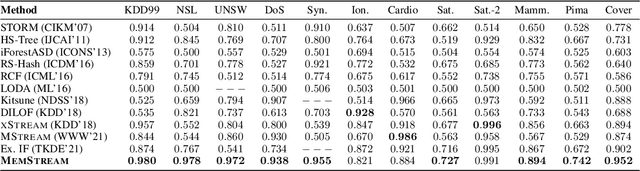
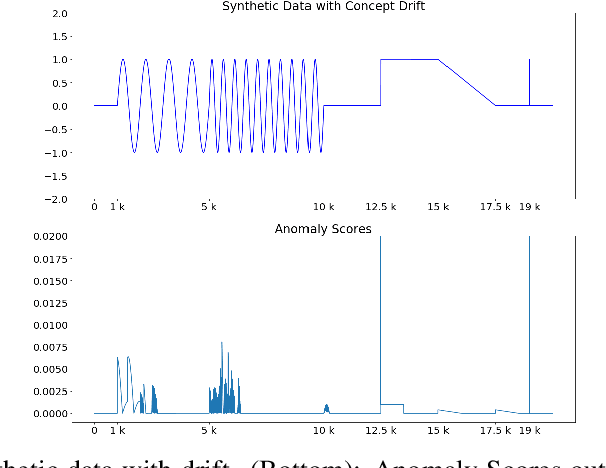
Given a stream of entries over time in a multi-aspect data setting where concept drift is present, how can we detect anomalous activities? Most of the existing unsupervised anomaly detection approaches seek to detect anomalous events in an offline fashion and require a large amount of data for training. This is not practical in real-life scenarios where we receive the data in a streaming manner and do not know the size of the stream beforehand. Thus, we need a data-efficient method that can detect and adapt to changing data trends, or concept drift, in an online manner. In this work, we propose MemStream, a streaming multi-aspect anomaly detection framework, allowing us to detect unusual events as they occur while being resilient to concept drift. We leverage the power of a denoising autoencoder to learn representations and a memory module to learn the dynamically changing trend in data without the need for labels. We prove the optimum memory size required for effective drift handling. Furthermore, MemStream makes use of two architecture design choices to be robust to memory poisoning. Experimental results show the effectiveness of our approach compared to state-of-the-art streaming baselines using 2 synthetic datasets and 11 real-world datasets.
Deep Indexed Active Learning for Matching Heterogeneous Entity Representations
Apr 08, 2021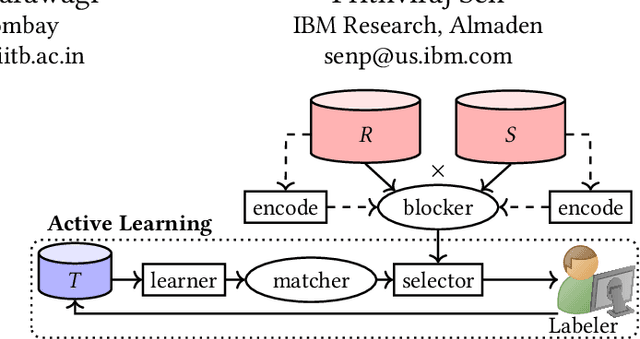
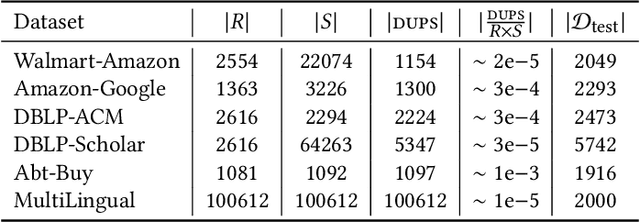
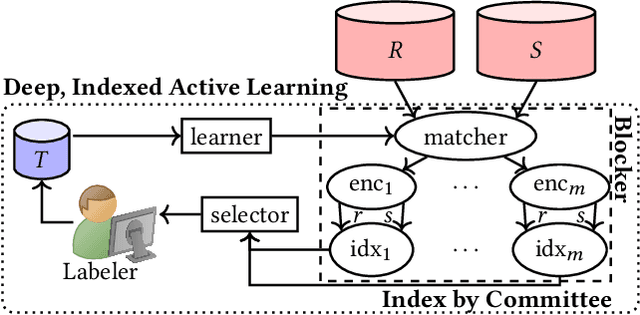
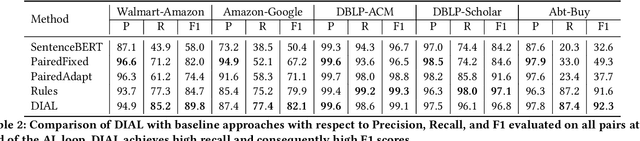
Given two large lists of records, the task in entity resolution (ER) is to find the pairs from the Cartesian product of the lists that correspond to the same real world entity. Typically, passive learning methods on tasks like ER require large amounts of labeled data to yield useful models. Active Learning is a promising approach for ER in low resource settings. However, the search space, to find informative samples for the user to label, grows quadratically for instance-pair tasks making active learning hard to scale. Previous works, in this setting, rely on hand-crafted predicates, pre-trained language model embeddings, or rule learning to prune away unlikely pairs from the Cartesian product. This blocking step can miss out on important regions in the product space leading to low recall. We propose DIAL, a scalable active learning approach that jointly learns embeddings to maximize recall for blocking and accuracy for matching blocked pairs. DIAL uses an Index-By-Committee framework, where each committee member learns representations based on powerful transformer models. We highlight surprising differences between the matcher and the blocker in the creation of the training data and the objective used to train their parameters. Experiments on five benchmark datasets and a multilingual record matching dataset show the effectiveness of our approach in terms of precision, recall and running time. Code is available at https://github.com/ArjitJ/DIAL
ExGAN: Adversarial Generation of Extreme Samples
Sep 17, 2020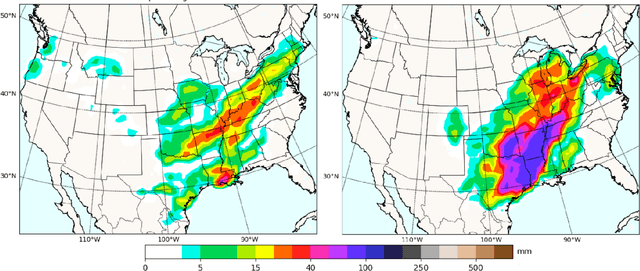

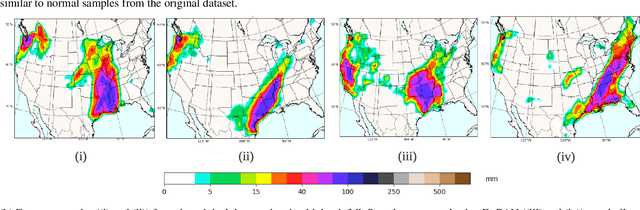
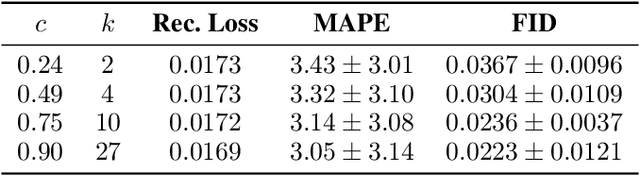
Mitigating the risk arising from extreme events is a fundamental goal with many applications, such as the modelling of natural disasters, financial crashes, epidemics, and many others. To manage this risk, a vital step is to be able to understand or generate a wide range of extreme scenarios. Existing approaches based on Generative Adversarial Networks (GANs) excel at generating realistic samples, but seek to generate typical samples, rather than extreme samples. Hence, in this work, we propose ExGAN, a GAN-based approach to generate realistic and extreme samples. To model the extremes of the training distribution in a principled way, our work draws from Extreme Value Theory (EVT), a probabilistic approach for modelling the extreme tails of distributions. For practical utility, our framework allows the user to specify both the desired extremeness measure, as well as the desired extremeness probability they wish to sample at. Experiments on real US Precipitation data show that our method generates realistic samples, based on visual inspection and quantitative measures, in an efficient manner. Moreover, generating increasingly extreme examples using ExGAN can be done in constant time (with respect to the extremeness probability), as opposed to the exponential time required by the baseline approach.
MStream: Fast Streaming Multi-Aspect Group Anomaly Detection
Sep 17, 2020

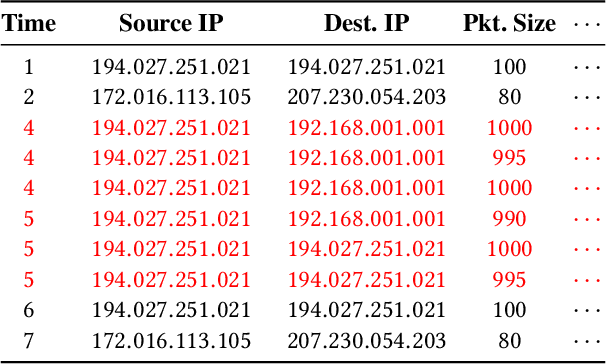
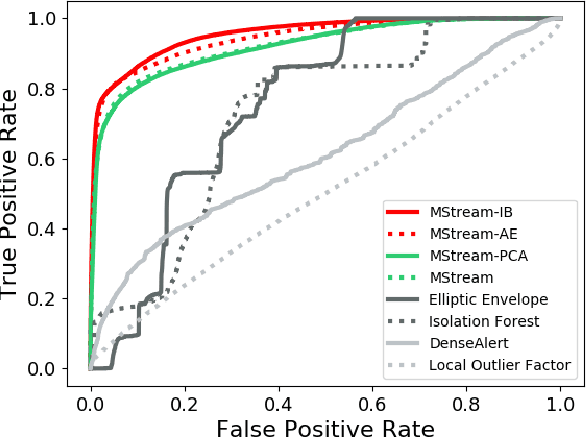
Given a stream of entries in a multi-aspect data setting i.e., entries having multiple dimensions, how can we detect anomalous activities? For example, in the intrusion detection setting, existing work seeks to detect anomalous events or edges in dynamic graph streams, but this does not allow us to take into account additional attributes of each entry. Our work aims to define a streaming multi-aspect data anomaly detection framework, termed MStream, which can detect unusual group anomalies as they occur, in a dynamic manner. MStream has the following properties: (a) it detects anomalies in multi-aspect data including both categorical and numeric attributes; (b) it is online, thus processing each record in constant time and constant memory; (c) it can capture the correlation between multiple aspects of the data. MStream is evaluated over the KDDCUP99, CICIDS-DoS, UNSW-NB 15 and CICIDS-DDoS datasets, and outperforms state-of-the-art baselines.