 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpliceOut: A Simple and Efficient Audio Augmentation Method
Paper and Code

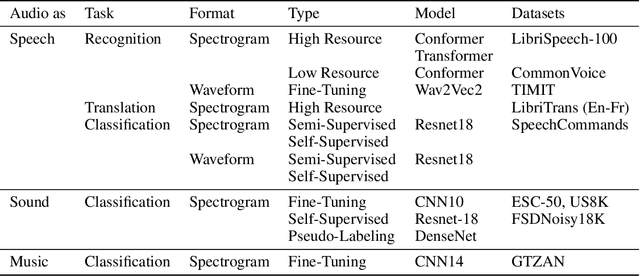
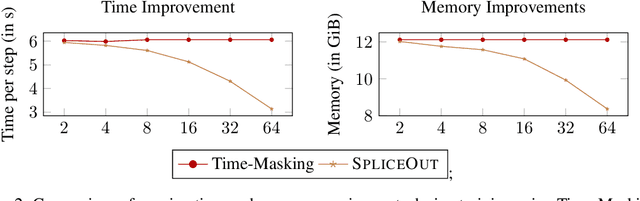
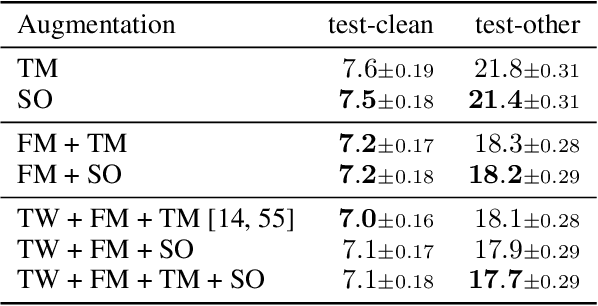
Time masking has become a de facto augmentation technique for speech and audio tasks, including automatic speech recognition (ASR) and audio classification, most notably as a part of SpecAugment. In this work, we propose SpliceOut, a simple modification to time masking which makes it computationally more efficient. SpliceOut performs comparably to (and sometimes outperforms) SpecAugment on a wide variety of speech and audio tasks, including ASR for seven different languages using varying amounts of training data, as well as on speech translation, sound and music classification, thus establishing itself as a broadly applicable audio augmentation method. SpliceOut also provides additional gains when used in conjunction with other augmentation techniques. Apart from the fully-supervised setting, we also demonstrate that SpliceOut can complement unsupervised representation learning with performance gains in the semi-supervised and self-supervised settings.