 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-Tuned Video-Audio Models Elucidate Functional Specialization in the Brain
Jun 09, 2025Recent voxel-wise multimodal brain encoding studies have shown that multimodal large language models (MLLMs) exhibit a higher degree of brain alignment compared to unimodal models in both unimodal and multimodal stimulus settings. More recently, instruction-tuned multimodal models have shown to generate task-specific representations that align strongly with brain activity. However, prior work evaluating the brain alignment of MLLMs has primarily focused on unimodal settings or relied on non-instruction-tuned multimodal models for multimodal stimuli. To address this gap, we investigated brain alignment, that is, measuring the degree of predictivity of neural activity recorded while participants were watching naturalistic movies (video along with audio) with representations derived from MLLMs. We utilized instruction-specific embeddings from six video and two audio instruction-tuned MLLMs. Experiments with 13 video task-specific instructions show that instruction-tuned video MLLMs significantly outperform non-instruction-tuned multimodal (by 15%) and unimodal models (by 20%). Our evaluation of MLLMs for both video and audio tasks using language-guided instructions shows clear disentanglement in task-specific representations from MLLMs, leading to precise differentiation of multimodal functional processing in the brain. We also find that MLLM layers align hierarchically with the brain, with early sensory areas showing strong alignment with early layers, while higher-level visual and language regions align more with middle to late layers. These findings provide clear evidence for the role of task-specific instructions in improving the alignment between brain activity and MLLMs, and open new avenues for mapping joint information processing in both the systems. We make the code publicly available [https://github.com/subbareddy248/mllm_videos].
Multi-modal brain encoding models for multi-modal stimuli
May 26, 2025Despite participants engaging in unimodal stimuli, such as watching images or silent videos, recent work has demonstrated that multi-modal Transformer models can predict visual brain activity impressively well, even with incongruent modality representations. This raises the question of how accurately these multi-modal models can predict brain activity when participants are engaged in multi-modal stimuli. As these models grow increasingly popular, their use in studying neural activity provides insights into how our brains respond to such multi-modal naturalistic stimuli, i.e., where it separates and integrates information across modalities through a hierarchy of early sensory regions to higher cognition. We investigate this question by using multiple unimodal and two types of multi-modal models-cross-modal and jointly pretrained-to determine which type of model is more relevant to fMRI brain activity when participants are engaged in watching movies. We observe that both types of multi-modal models show improved alignment in several language and visual regions. This study also helps in identifying which brain regions process unimodal versus multi-modal information. We further investigate the contribution of each modality to multi-modal alignment by carefully removing unimodal features one by one from multi-modal representations, and find that there is additional information beyond the unimodal embeddings that is processed in the visual and language regions. Based on this investigation, we find that while for cross-modal models, their brain alignment is partially attributed to the video modality; for jointly pretrained models, it is partially attributed to both the video and audio modalities. This serves as a strong motivation for the neuroscience community to investigate the interpretability of these models for deepening our understanding of multi-modal information processing in brain.
* 26 pages, 15 figures, The Thirteenth International Conference on Learning Representations, ICLR-2025, Singapore. https://openreview.net/pdf?id=0dELcFHig2
Correlating instruction-tuning (in multimodal models) with vision-language processing (in the brain)
May 26, 2025Transformer-based language models, though not explicitly trained to mimic brain recordings, have demonstrated surprising alignment with brain activity. Progress in these models-through increased size, instruction-tuning, and multimodality-has led to better representational alignment with neural data. Recently, a new class of instruction-tuned multimodal LLMs (MLLMs) have emerged, showing remarkable zero-shot capabilities in open-ended multimodal vision tasks. However, it is unknown whether MLLMs, when prompted with natural instructions, lead to better brain alignment and effectively capture instruction-specific representations. To address this, we first investigate brain alignment, i.e., measuring the degree of predictivity of neural visual activity using text output response embeddings from MLLMs as participants engage in watching natural scenes. Experiments with 10 different instructions show that MLLMs exhibit significantly better brain alignment than vision-only models and perform comparably to non-instruction-tuned multimodal models like CLIP. We also find that while these MLLMs are effective at generating high-quality responses suitable to the task-specific instructions, not all instructions are relevant for brain alignment. Further, by varying instructions, we make the MLLMs encode instruction-specific visual concepts related to the input image. This analysis shows that MLLMs effectively capture count-related and recognition-related concepts, demonstrating strong alignment with brain activity. Notably, the majority of the explained variance of the brain encoding models is shared between MLLM embeddings of image captioning and other instructions. These results suggest that enhancing MLLMs' ability to capture task-specific information could lead to better differentiation between various types of instructions, and thereby improving their precision in predicting brain responses.
* 30 pages, 22 figures, The Thirteenth International Conference on Learning Representations, ICLR-2025, Singapore. https://openreview.net/pdf?id=xkgfLXZ4e0
MST-R: Multi-Stage Tuning for Retrieval Systems and Metric Evaluation
Dec 13, 2024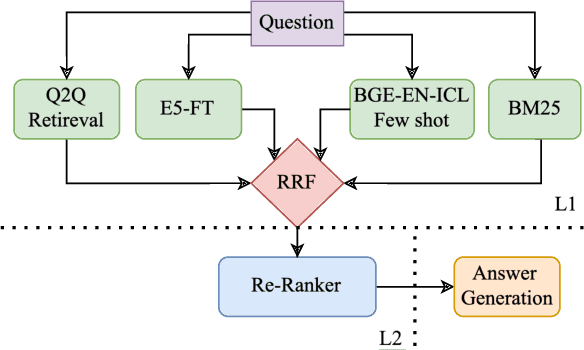
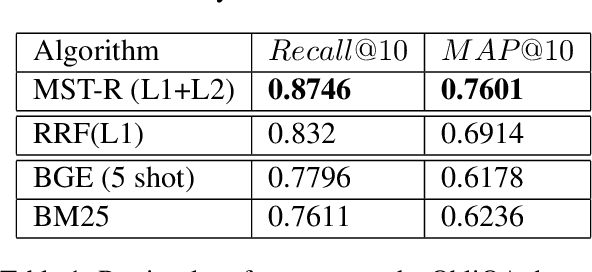

Regulatory documents are rich in nuanced terminology and specialized semantics. FRAG systems: Frozen retrieval-augmented generators utilizing pre-trained (or, frozen) components face consequent challenges with both retriever and answering performance. We present a system that adapts the retriever performance to the target domain using a multi-stage tuning (MST) strategy. Our retrieval approach, called MST-R (a) first fine-tunes encoders used in vector stores using hard negative mining, (b) then uses a hybrid retriever, combining sparse and dense retrievers using reciprocal rank fusion, and then (c) adapts the cross-attention encoder by fine-tuning only the top-k retrieved results. We benchmark the system performance on the dataset released for the RIRAG challenge (as part of the RegNLP workshop at COLING 2025). We achieve significant performance gains obtaining a top rank on the RegNLP challenge leaderboard. We also show that a trivial answering approach games the RePASs metric outscoring all baselines and a pre-trained Llama model. Analyzing this anomaly, we present important takeaways for future research.
Geometry-biased Transformers for Novel View Synthesis
Jan 11, 2023



We tackle the task of synthesizing novel views of an object given a few input images and associated camera viewpoints. Our work is inspired by recent 'geometry-free' approaches where multi-view images are encoded as a (global) set-latent representation, which is then used to predict the color for arbitrary query rays. While this representation yields (coarsely) accurate images corresponding to novel viewpoints, the lack of geometric reasoning limits the quality of these outputs. To overcome this limitation, we propose 'Geometry-biased Transformers' (GBTs) that incorporate geometric inductive biases in the set-latent representation-based inference to encourage multi-view geometric consistency. We induce the geometric bias by augmenting the dot-product attention mechanism to also incorporate 3D distances between rays associated with tokens as a learnable bias. We find that this, along with camera-aware embeddings as input, allows our models to generate significantly more accurate outputs. We validate our approach on the real-world CO3D dataset, where we train our system over 10 categories and evaluate its view-synthesis ability for novel objects as well as unseen categories. We empirically validate the benefits of the proposed geometric biases and show that our approach significantly improves over prior works.
Hierarchical Semantic Regularization of Latent Spaces in StyleGANs
Aug 07, 2022
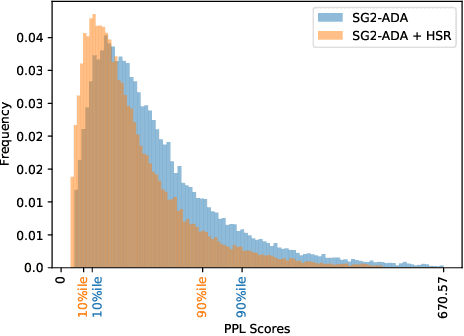
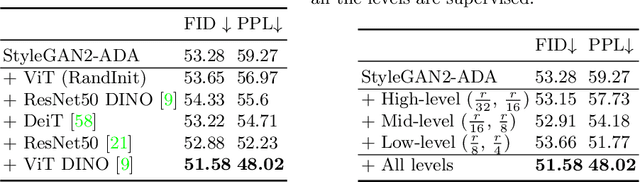
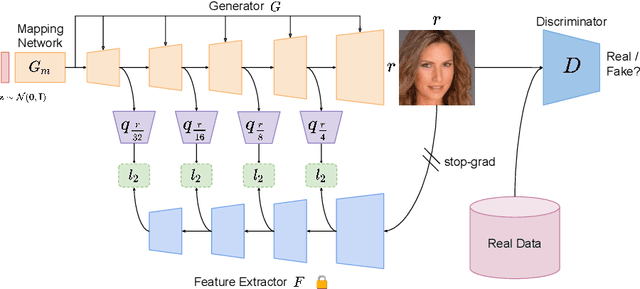
Progress in GANs has enabled the generation of high-resolution photorealistic images of astonishing quality. StyleGANs allow for compelling attribute modification on such images via mathematical operations on the latent style vectors in the W/W+ space that effectively modulate the rich hierarchical representations of the generator. Such operations have recently been generalized beyond mere attribute swapping in the original StyleGAN paper to include interpolations. In spite of many significant improvements in StyleGANs, they are still seen to generate unnatural images. The quality of the generated images is predicated on two assumptions; (a) The richness of the hierarchical representations learnt by the generator, and, (b) The linearity and smoothness of the style spaces. In this work, we propose a Hierarchical Semantic Regularizer (HSR) which aligns the hierarchical representations learnt by the generator to corresponding powerful features learnt by pretrained networks on large amounts of data. HSR is shown to not only improve generator representations but also the linearity and smoothness of the latent style spaces, leading to the generation of more natural-looking style-edited images. To demonstrate improved linearity, we propose a novel metric - Attribute Linearity Score (ALS). A significant reduction in the generation of unnatural images is corroborated by improvement in the Perceptual Path Length (PPL) metric by 16.19% averaged across different standard datasets while simultaneously improving the linearity of attribute-change in the attribute editing tasks.
Interpretable Acoustic Representation Learning on Breathing and Speech Signals for COVID-19 Detection
Jun 27, 2022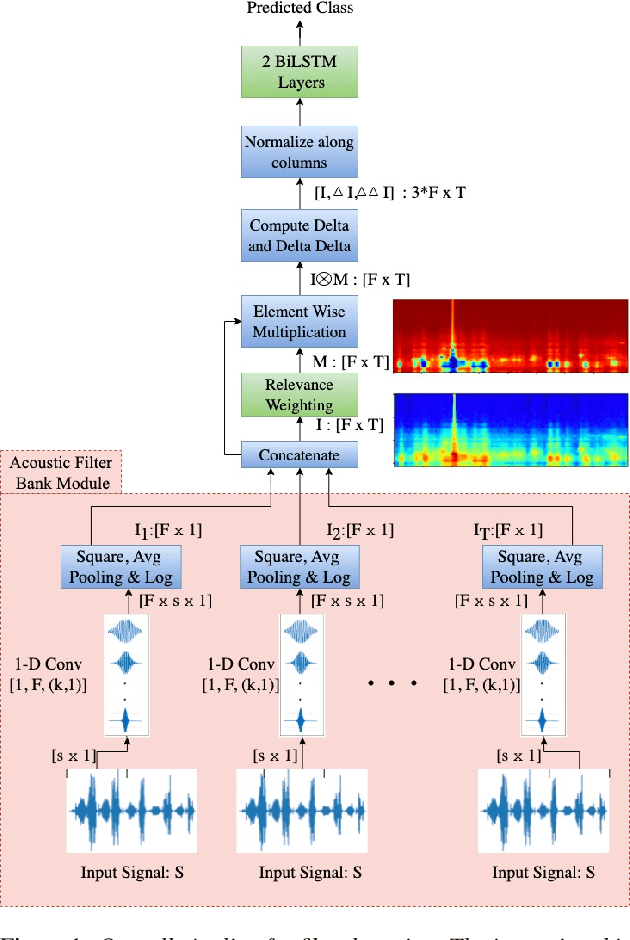
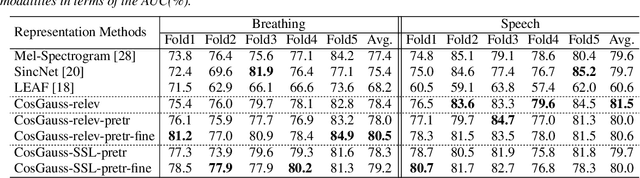
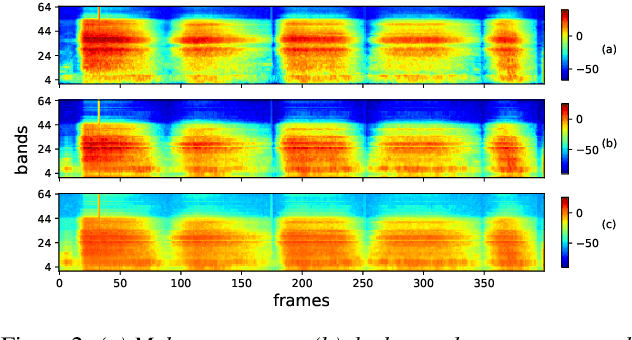
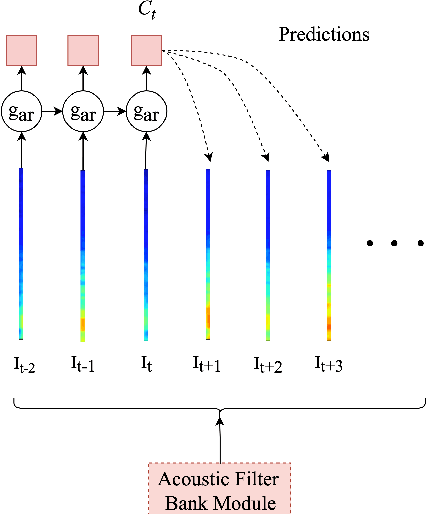
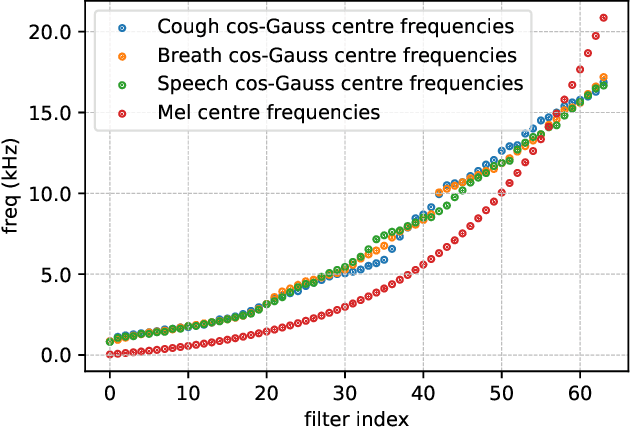
In this paper, we describe an approach for representation learning of audio signals for the task of COVID-19 detection. The raw audio samples are processed with a bank of 1-D convolutional filters that are parameterized as cosine modulated Gaussian functions. The choice of these kernels allows the interpretation of the filterbanks as smooth band-pass filters. The filtered outputs are pooled, log-compressed and used in a self-attention based relevance weighting mechanism. The relevance weighting emphasizes the key regions of the time-frequency decomposition that are important for the downstream task. The subsequent layers of the model consist of a recurrent architecture and the models are trained for a COVID-19 detection task. In our experiments on the Coswara data set, we show that the proposed model achieves significant performance improvements over the baseline system as well as other representation learning approaches. Further, the approach proposed is shown to be uniformly applicable for speech and breathing signals and for transfer learning from a larger data set.
Svadhyaya system for the Second Diagnosing COVID-19 using Acoustics Challenge 2021
Jun 11, 2022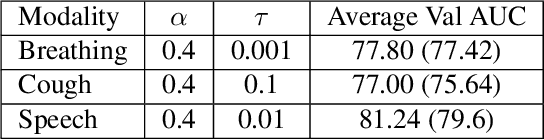

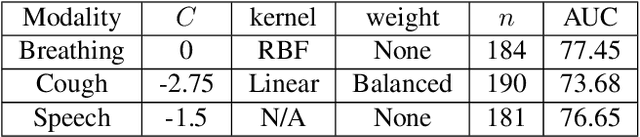
This report describes the system used for detecting COVID-19 positives using three different acoustic modalities, namely speech, breathing, and cough in the second DiCOVA challenge. The proposed system is based on the combination of 4 different approaches, each focusing more on one aspect of the problem, and reaches the blind test AUCs of 86.41, 77.60, and 84.55, in the breathing, cough, and speech tracks, respectively, and the AUC of 85.37 in the fusion of these three tracks.
Unveiling The Mask of Position-Information Pattern Through the Mist of Image Features
Jun 02, 2022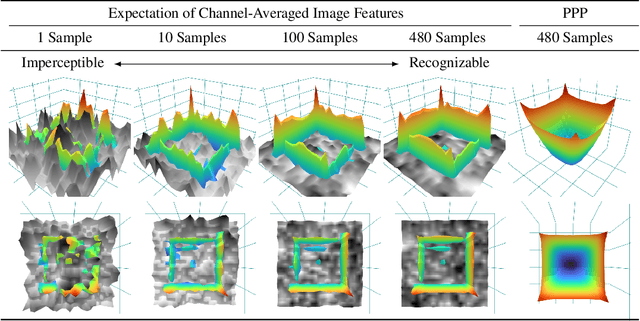
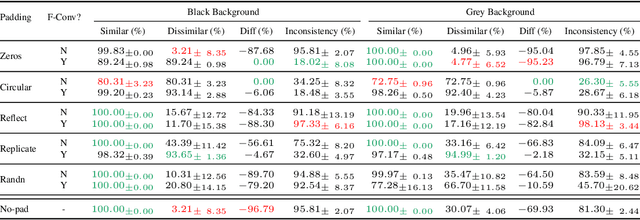
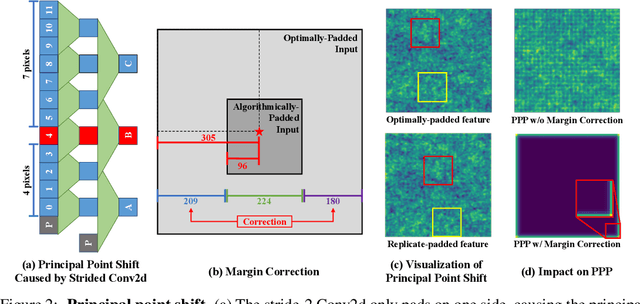
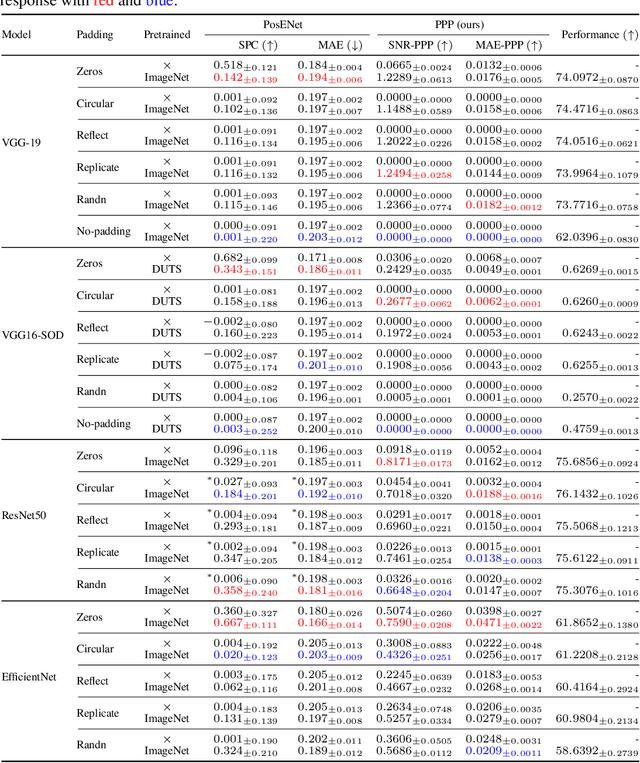
Recent studies show that paddings in convolutional neural networks encode absolute position information which can negatively affect the model performance for certain tasks. However, existing metrics for quantifying the strength of positional information remain unreliable and frequently lead to erroneous results. To address this issue, we propose novel metrics for measuring (and visualizing) the encoded positional information. We formally define the encoded information as PPP (Position-information Pattern from Padding) and conduct a series of experiments to study its properties as well as its formation. The proposed metrics measure the presence of positional information more reliably than the existing metrics based on PosENet and a test in F-Conv. We also demonstrate that for any extant (and proposed) padding schemes, PPP is primarily a learning artifact and is less dependent on the characteristics of the underlying padding schemes.
DeLoRes: Decorrelating Latent Spaces for Low-Resource Audio Representation Learning
Apr 13, 2022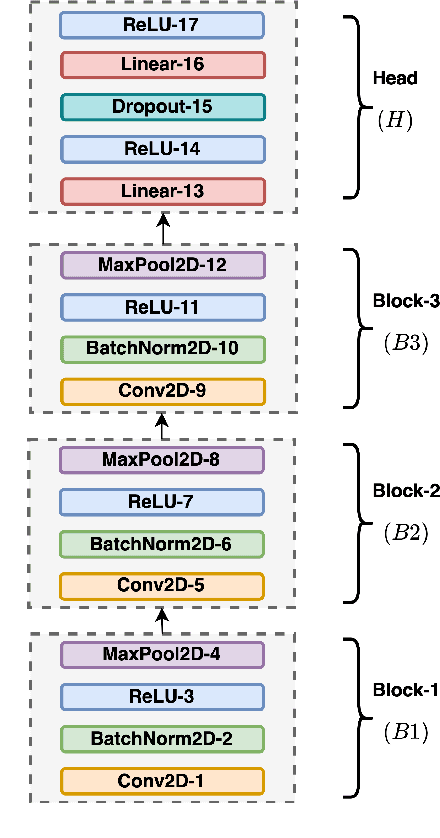
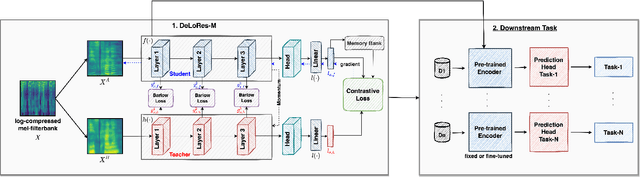
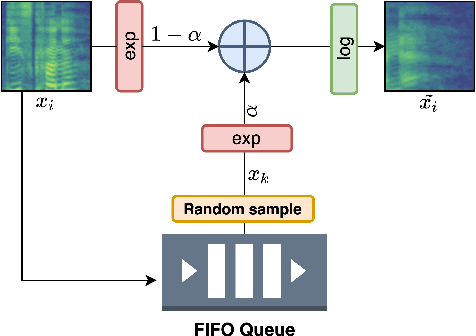
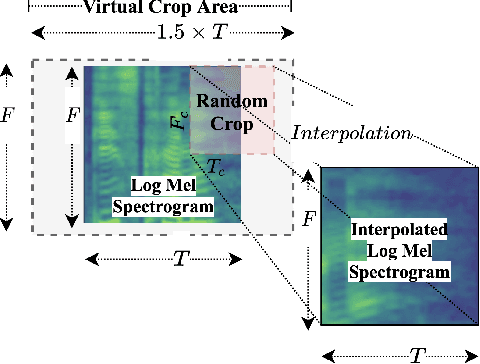
Inspired by the recent progress in self-supervised learning for computer vision, in this paper, through the DeLoRes learning framework, we introduce two new general-purpose audio representation learning approaches, the DeLoRes-S and DeLoRes-M. Our main objective is to make our network learn representations in a resource-constrained setting (both data and compute), that can generalize well across a diverse set of downstream tasks. Inspired from the Barlow Twins objective function, we propose to learn embeddings that are invariant to distortions of an input audio sample, while making sure that they contain non-redundant information about the sample. To achieve this, we measure the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of an audio segment sampled from an audio file and make it as close to the identity matrix as possible. We call this the DeLoRes learning framework, which we employ in different fashions with the DeLoRes-S and DeLoRes-M. We use a combination of a small subset of the large-scale AudioSet dataset and FSD50K for self-supervised learning and are able to learn with less than half the parameters compared to state-of-the-art algorithms. For evaluation, we transfer these learned representations to 11 downstream classification tasks, including speech, music, and animal sounds, and achieve state-of-the-art results on 7 out of 11 tasks on linear evaluation with DeLoRes-M and show competitive results with DeLoRes-S, even when pre-trained using only a fraction of the total data when compared to prior art. Our transfer learning evaluation setup also shows extremely competitive results for both DeLoRes-S and DeLoRes-M, with DeLoRes-M achieving state-of-the-art in 4 tasks.