 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Image Generation via Human-in-the-loop Bayesian Optimization
Feb 02, 2026Imagine Alice has a specific image $x^\ast$ in her mind, say, the view of the street in which she grew up during her childhood. To generate that exact image, she guides a generative model with multiple rounds of prompting and arrives at an image $x^{p*}$. Although $x^{p*}$ is reasonably close to $x^\ast$, Alice finds it difficult to close that gap using language prompts. This paper aims to narrow this gap by observing that even after language has reached its limits, humans can still tell when a new image $x^+$ is closer to $x^\ast$ than $x^{p*}$. Leveraging this observation, we develop MultiBO (Multi-Choice Preferential Bayesian Optimization) that carefully generates $K$ new images as a function of $x^{p*}$, gets preferential feedback from the user, uses the feedback to guide the diffusion model, and ultimately generates a new set of $K$ images. We show that within $B$ rounds of user feedback, it is possible to arrive much closer to $x^\ast$, even though the generative model has no information about $x^\ast$. Qualitative scores from $30$ users, combined with quantitative metrics compared across $5$ baselines, show promising results, suggesting that multi-choice feedback from humans can be effectively harnessed for personalized image generation.
Estimating Multi-chirp Parameters using Curvature-guided Langevin Monte Carlo
Jan 30, 2025



This paper considers the problem of estimating chirp parameters from a noisy mixture of chirps. While a rich body of work exists in this area, challenges remain when extending these techniques to chirps of higher order polynomials. We formulate this as a non-convex optimization problem and propose a modified Langevin Monte Carlo (LMC) sampler that exploits the average curvature of the objective function to reliably find the minimizer. Results show that our Curvature-guided LMC (CG-LMC) algorithm is robust and succeeds even in low SNR regimes, making it viable for practical applications.
Multi-Source Music Generation with Latent Diffusion
Sep 10, 2024
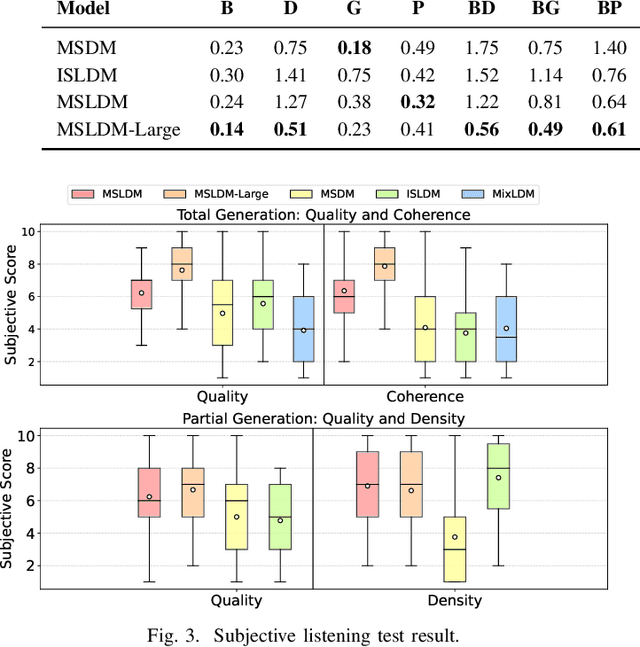


Most music generation models directly generate a single music mixture. To allow for more flexible and controllable generation, the Multi-Source Diffusion Model (MSDM) has been proposed to model music as a mixture of multiple instrumental sources (e.g., piano, drums, bass, and guitar). Its goal is to use one single diffusion model to generate consistent music sources, which are further mixed to form the music. Despite its capabilities, MSDM is unable to generate songs with rich melodies and often generates empty sounds. Also, its waveform diffusion introduces significant Gaussian noise artifacts, which compromises audio quality. In response, we introduce a multi-source latent diffusion model (MSLDM) that employs Variational Autoencoders (VAEs) to encode each instrumental source into a distinct latent representation. By training a VAE on all music sources, we efficiently capture each source's unique characteristics in a source latent that our diffusion model models jointly. This approach significantly enhances the total and partial generation of music by leveraging the VAE's latent compression and noise-robustness. The compressed source latent also facilitates more efficient generation. Subjective listening tests and Frechet Audio Distance (FAD) scores confirm that our model outperforms MSDM, showcasing its practical and enhanced applicability in music generation systems. We also emphasize that modeling sources is more effective than direct music mixture modeling. Codes and models are available at https://github.com/XZWY/MSLDM. Demos are available at https://xzwy.github.io/MSLDMDemo.
Speech enhancement with frequency domain auto-regressive modeling
Sep 24, 2023Speech applications in far-field real world settings often deal with signals that are corrupted by reverberation. The task of dereverberation constitutes an important step to improve the audible quality and to reduce the error rates in applications like automatic speech recognition (ASR). We propose a unified framework of speech dereverberation for improving the speech quality and the ASR performance using the approach of envelope-carrier decomposition provided by an autoregressive (AR) model. The AR model is applied in the frequency domain of the sub-band speech signals to separate the envelope and carrier parts. A novel neural architecture based on dual path long short term memory (DPLSTM) model is proposed, which jointly enhances the sub-band envelope and carrier components. The dereverberated envelope-carrier signals are modulated and the sub-band signals are synthesized to reconstruct the audio signal back. The DPLSTM model for dereverberation of envelope and carrier components also allows the joint learning of the network weights for the down stream ASR task. In the ASR tasks on the REVERB challenge dataset as well as on the VOiCES dataset, we illustrate that the joint learning of speech dereverberation network and the E2E ASR model yields significant performance improvements over the baseline ASR system trained on log-mel spectrogram as well as other benchmarks for dereverberation (average relative improvements of 10-24% over the baseline system). The speech quality improvements, evaluated using subjective listening tests, further highlight the improved quality of the reconstructed audio.
* 10 pages
Coswara: A respiratory sounds and symptoms dataset for remote screening of SARS-CoV-2 infection
May 22, 2023This paper presents the Coswara dataset, a dataset containing diverse set of respiratory sounds and rich meta-data, recorded between April-2020 and February-2022 from 2635 individuals (1819 SARS-CoV-2 negative, 674 positive, and 142 recovered subjects). The respiratory sounds contained nine sound categories associated with variants of breathing, cough and speech. The rich metadata contained demographic information associated with age, gender and geographic location, as well as the health information relating to the symptoms, pre-existing respiratory ailments, comorbidity and SARS-CoV-2 test status. Our study is the first of its kind to manually annotate the audio quality of the entire dataset (amounting to 65~hours) through manual listening. The paper summarizes the data collection procedure, demographic, symptoms and audio data information. A COVID-19 classifier based on bi-directional long short-term (BLSTM) architecture, is trained and evaluated on the different population sub-groups contained in the dataset to understand the bias/fairness of the model. This enabled the analysis of the impact of gender, geographic location, date of recording, and language proficiency on the COVID-19 detection performance.
Interpretable Acoustic Representation Learning on Breathing and Speech Signals for COVID-19 Detection
Jun 27, 2022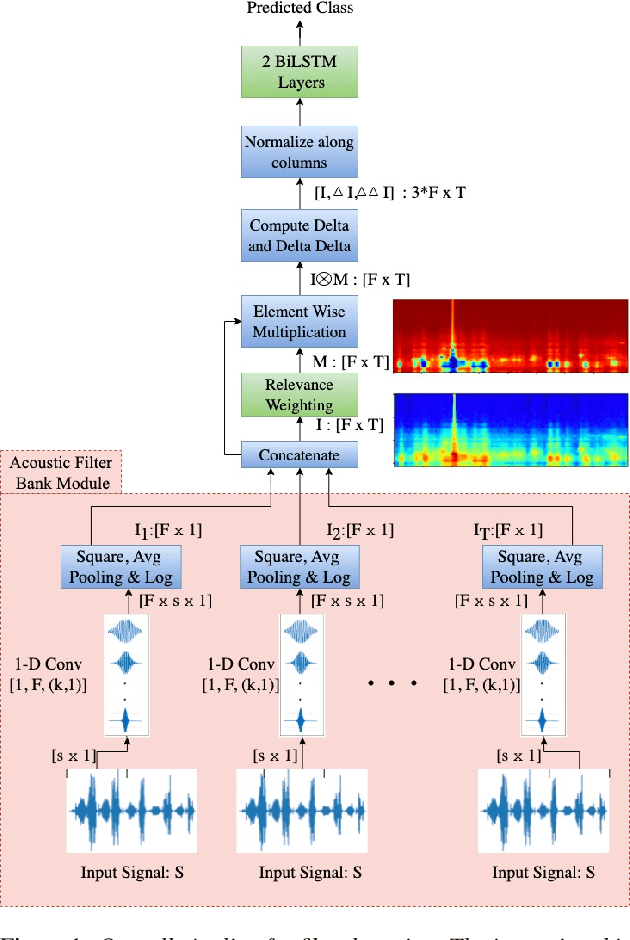
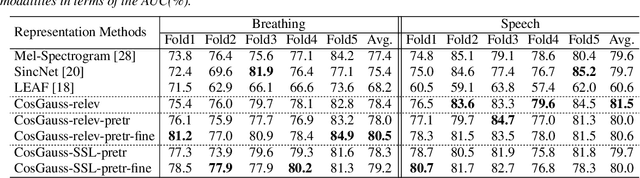
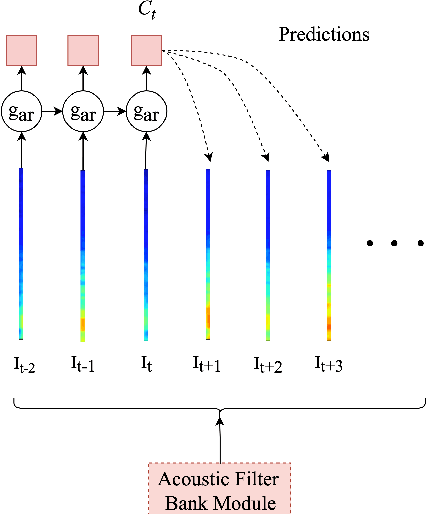
In this paper, we describe an approach for representation learning of audio signals for the task of COVID-19 detection. The raw audio samples are processed with a bank of 1-D convolutional filters that are parameterized as cosine modulated Gaussian functions. The choice of these kernels allows the interpretation of the filterbanks as smooth band-pass filters. The filtered outputs are pooled, log-compressed and used in a self-attention based relevance weighting mechanism. The relevance weighting emphasizes the key regions of the time-frequency decomposition that are important for the downstream task. The subsequent layers of the model consist of a recurrent architecture and the models are trained for a COVID-19 detection task. In our experiments on the Coswara data set, we show that the proposed model achieves significant performance improvements over the baseline system as well as other representation learning approaches. Further, the approach proposed is shown to be uniformly applicable for speech and breathing signals and for transfer learning from a larger data set.
Analyzing the impact of SARS-CoV-2 variants on respiratory sound signals
Jun 24, 2022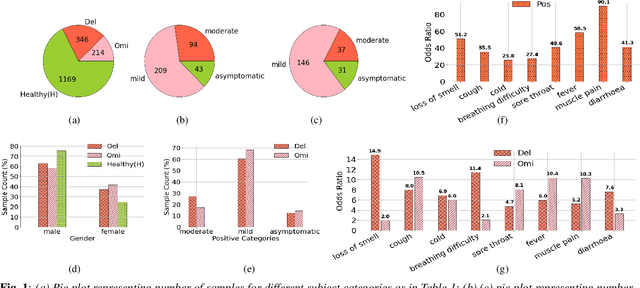
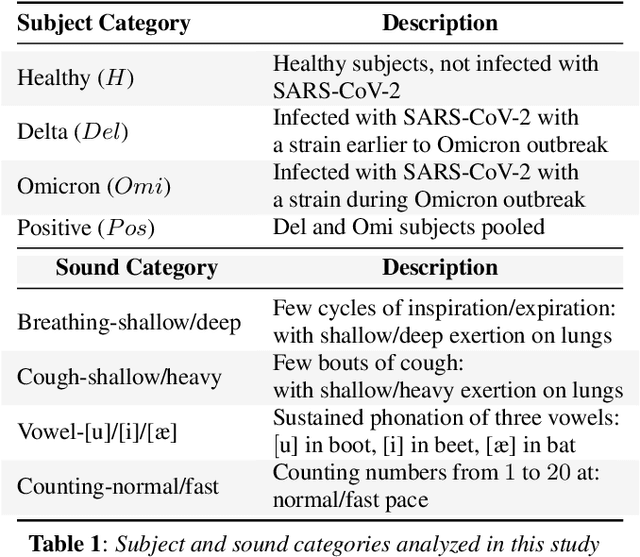
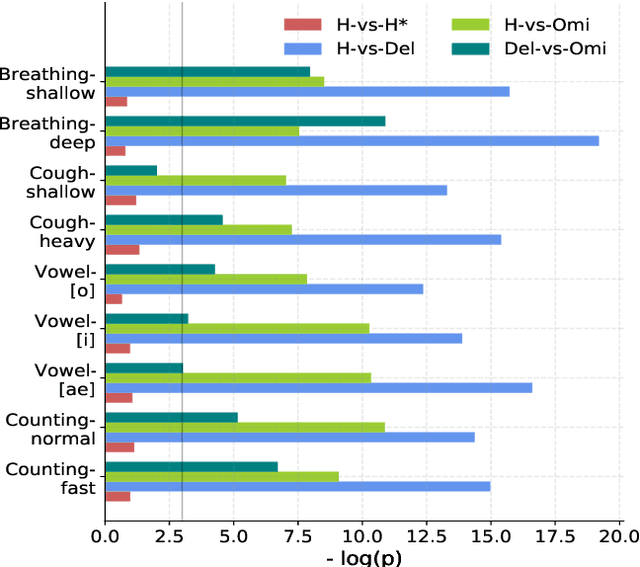
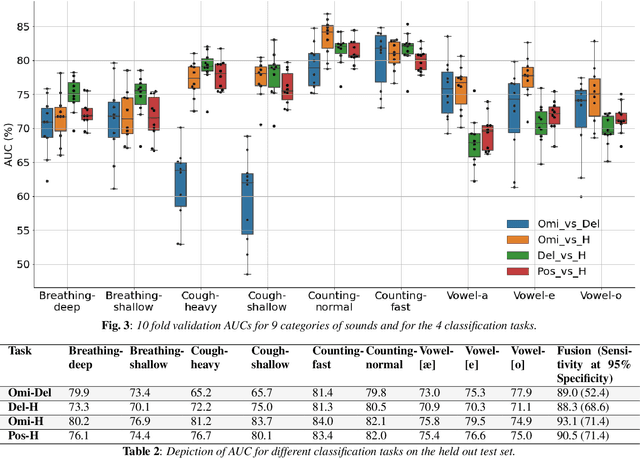
The COVID-19 outbreak resulted in multiple waves of infections that have been associated with different SARS-CoV-2 variants. Studies have reported differential impact of the variants on respiratory health of patients. We explore whether acoustic signals, collected from COVID-19 subjects, show computationally distinguishable acoustic patterns suggesting a possibility to predict the underlying virus variant. We analyze the Coswara dataset which is collected from three subject pools, namely, i) healthy, ii) COVID-19 subjects recorded during the delta variant dominant period, and iii) data from COVID-19 subjects recorded during the omicron surge. Our findings suggest that multiple sound categories, such as cough, breathing, and speech, indicate significant acoustic feature differences when comparing COVID-19 subjects with omicron and delta variants. The classification areas-under-the-curve are significantly above chance for differentiating subjects infected by omicron from those infected by delta. Using a score fusion from multiple sound categories, we obtained an area-under-the-curve of 89% and 52.4% sensitivity at 95% specificity. Additionally, a hierarchical three class approach was used to classify the acoustic data into healthy and COVID-19 positive, and further COVID-19 subjects into delta and omicron variants providing high level of 3-class classification accuracy. These results suggest new ways for designing sound based COVID-19 diagnosis approaches.
Svadhyaya system for the Second Diagnosing COVID-19 using Acoustics Challenge 2021
Jun 11, 2022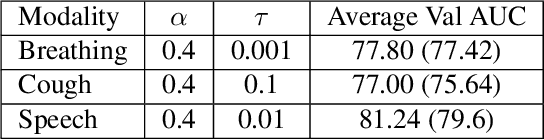
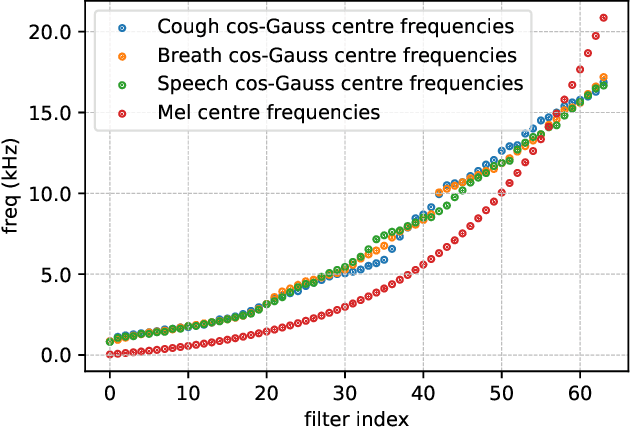

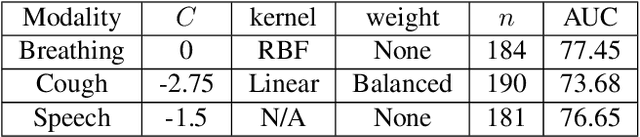
This report describes the system used for detecting COVID-19 positives using three different acoustic modalities, namely speech, breathing, and cough in the second DiCOVA challenge. The proposed system is based on the combination of 4 different approaches, each focusing more on one aspect of the problem, and reaches the blind test AUCs of 86.41, 77.60, and 84.55, in the breathing, cough, and speech tracks, respectively, and the AUC of 85.37 in the fusion of these three tracks.
Coswara: A website application enabling COVID-19 screening by analysing respiratory sound samples and health symptoms
Jun 09, 2022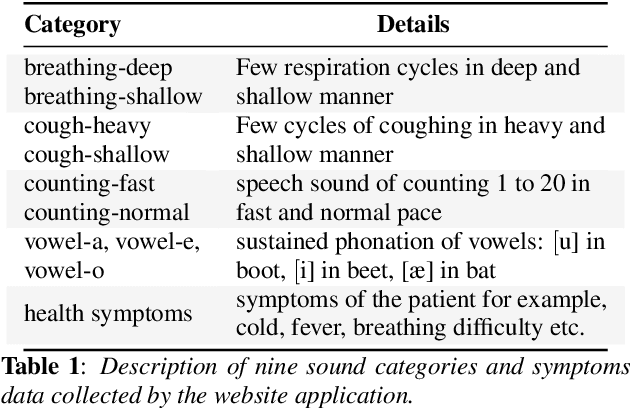


The COVID-19 pandemic has accelerated research on design of alternative, quick and effective COVID-19 diagnosis approaches. In this paper, we describe the Coswara tool, a website application designed to enable COVID-19 detection by analysing respiratory sound samples and health symptoms. A user using this service can log into a website using any device connected to the internet, provide there current health symptom information and record few sound sampled corresponding to breathing, cough, and speech. Within a minute of analysis of this information on a cloud server the website tool will output a COVID-19 probability score to the user. As the COVID-19 pandemic continues to demand massive and scalable population level testing, we hypothesize that the proposed tool provides a potential solution towards this.
The Second DiCOVA Challenge: Dataset and performance analysis for COVID-19 diagnosis using acoustics
Oct 11, 2021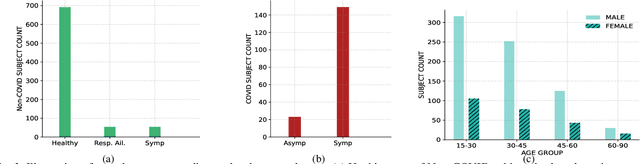
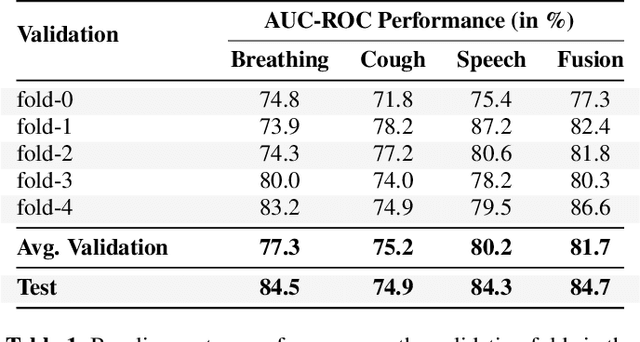
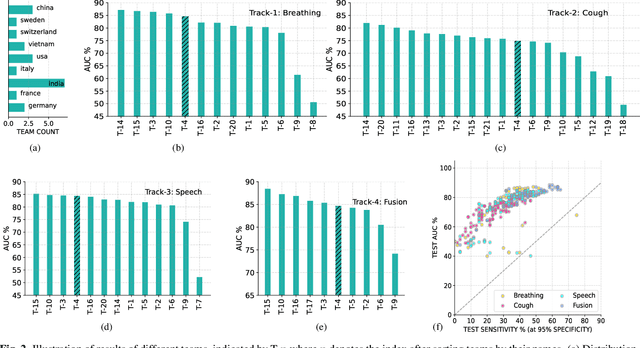
The Second Diagnosis of COVID-19 using Acoustics (DiCOVA) Challenge aimed at accelerating the research in acoustics based detection of COVID-19, a topic at the intersection of acoustics, signal processing, machine learning, and healthcare. This paper presents the details of the challenge, which was an open call for researchers to analyze a dataset of audio recordings consisting of breathing, cough and speech signals. This data was collected from individuals with and without COVID-19 infection, and the task in the challenge was a two-class classification. The development set audio recordings were collected from 965 (172 COVID-19 positive) individuals, while the evaluation set contained data from 471 individuals (71 COVID-19 positive). The challenge featured four tracks, one associated with each sound category of cough, speech and breathing, and a fourth fusion track. A baseline system was also released to benchmark the participants. In this paper, we present an overview of the challenge, the rationale for the data collection and the baseline system. Further, a performance analysis for the systems submitted by the $16$ participating teams in the leaderboard is also presented.