 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Image Generation via Human-in-the-loop Bayesian Optimization
Feb 02, 2026Imagine Alice has a specific image $x^\ast$ in her mind, say, the view of the street in which she grew up during her childhood. To generate that exact image, she guides a generative model with multiple rounds of prompting and arrives at an image $x^{p*}$. Although $x^{p*}$ is reasonably close to $x^\ast$, Alice finds it difficult to close that gap using language prompts. This paper aims to narrow this gap by observing that even after language has reached its limits, humans can still tell when a new image $x^+$ is closer to $x^\ast$ than $x^{p*}$. Leveraging this observation, we develop MultiBO (Multi-Choice Preferential Bayesian Optimization) that carefully generates $K$ new images as a function of $x^{p*}$, gets preferential feedback from the user, uses the feedback to guide the diffusion model, and ultimately generates a new set of $K$ images. We show that within $B$ rounds of user feedback, it is possible to arrive much closer to $x^\ast$, even though the generative model has no information about $x^\ast$. Qualitative scores from $30$ users, combined with quantitative metrics compared across $5$ baselines, show promising results, suggesting that multi-choice feedback from humans can be effectively harnessed for personalized image generation.
Kernel Learning for Sample Constrained Black-Box Optimization
Jul 28, 2025Black box optimization (BBO) focuses on optimizing unknown functions in high-dimensional spaces. In many applications, sampling the unknown function is expensive, imposing a tight sample budget. Ongoing work is making progress on reducing the sample budget by learning the shape/structure of the function, known as kernel learning. We propose a new method to learn the kernel of a Gaussian Process. Our idea is to create a continuous kernel space in the latent space of a variational autoencoder, and run an auxiliary optimization to identify the best kernel. Results show that the proposed method, Kernel Optimized Blackbox Optimization (KOBO), outperforms state of the art by estimating the optimal at considerably lower sample budgets. Results hold not only across synthetic benchmark functions but also in real applications. We show that a hearing aid may be personalized with fewer audio queries to the user, or a generative model could converge to desirable images from limited user ratings.
Can NeRFs See without Cameras?
May 28, 2025Neural Radiance Fields (NeRFs) have been remarkably successful at synthesizing novel views of 3D scenes by optimizing a volumetric scene function. This scene function models how optical rays bring color information from a 3D object to the camera pixels. Radio frequency (RF) or audio signals can also be viewed as a vehicle for delivering information about the environment to a sensor. However, unlike camera pixels, an RF/audio sensor receives a mixture of signals that contain many environmental reflections (also called "multipath"). Is it still possible to infer the environment using such multipath signals? We show that with redesign, NeRFs can be taught to learn from multipath signals, and thereby "see" the environment. As a grounding application, we aim to infer the indoor floorplan of a home from sparse WiFi measurements made at multiple locations inside the home. Although a difficult inverse problem, our implicitly learnt floorplans look promising, and enables forward applications, such as indoor signal prediction and basic ray tracing.
Estimating Multi-chirp Parameters using Curvature-guided Langevin Monte Carlo
Jan 30, 2025



This paper considers the problem of estimating chirp parameters from a noisy mixture of chirps. While a rich body of work exists in this area, challenges remain when extending these techniques to chirps of higher order polynomials. We formulate this as a non-convex optimization problem and propose a modified Langevin Monte Carlo (LMC) sampler that exploits the average curvature of the objective function to reliably find the minimizer. Results show that our Curvature-guided LMC (CG-LMC) algorithm is robust and succeeds even in low SNR regimes, making it viable for practical applications.
Multi-Source Music Generation with Latent Diffusion
Sep 10, 2024
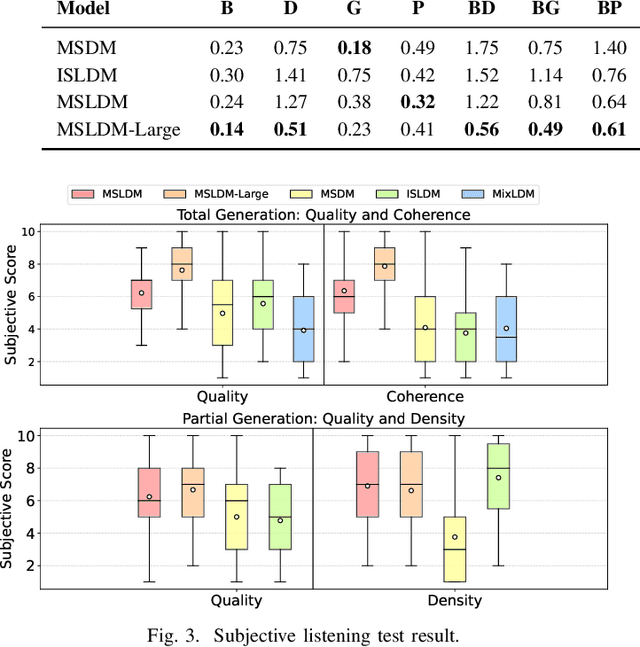


Most music generation models directly generate a single music mixture. To allow for more flexible and controllable generation, the Multi-Source Diffusion Model (MSDM) has been proposed to model music as a mixture of multiple instrumental sources (e.g., piano, drums, bass, and guitar). Its goal is to use one single diffusion model to generate consistent music sources, which are further mixed to form the music. Despite its capabilities, MSDM is unable to generate songs with rich melodies and often generates empty sounds. Also, its waveform diffusion introduces significant Gaussian noise artifacts, which compromises audio quality. In response, we introduce a multi-source latent diffusion model (MSLDM) that employs Variational Autoencoders (VAEs) to encode each instrumental source into a distinct latent representation. By training a VAE on all music sources, we efficiently capture each source's unique characteristics in a source latent that our diffusion model models jointly. This approach significantly enhances the total and partial generation of music by leveraging the VAE's latent compression and noise-robustness. The compressed source latent also facilitates more efficient generation. Subjective listening tests and Frechet Audio Distance (FAD) scores confirm that our model outperforms MSDM, showcasing its practical and enhanced applicability in music generation systems. We also emphasize that modeling sources is more effective than direct music mixture modeling. Codes and models are available at https://github.com/XZWY/MSLDM. Demos are available at https://xzwy.github.io/MSLDMDemo.
Inferring Facing Direction from Voice Signals
Sep 29, 2021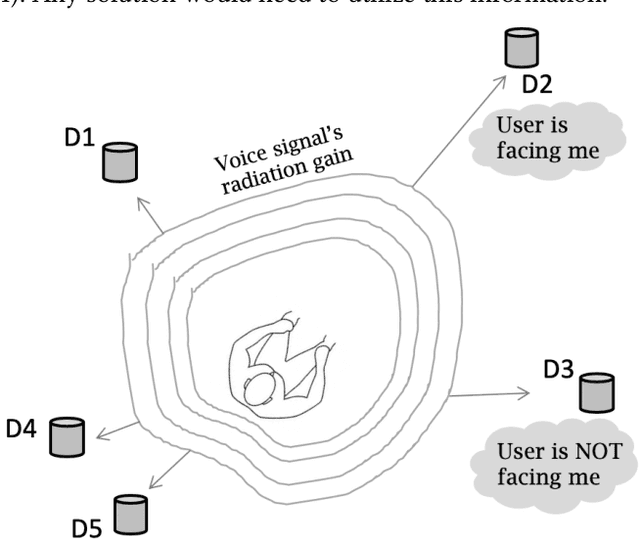
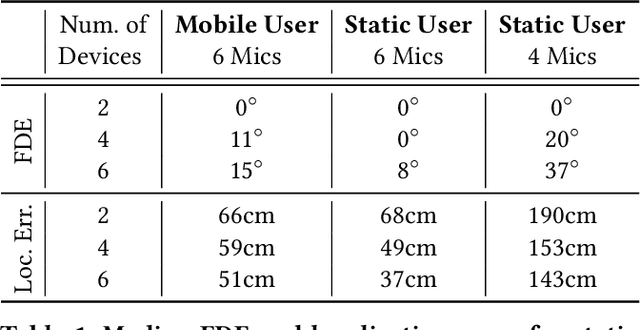
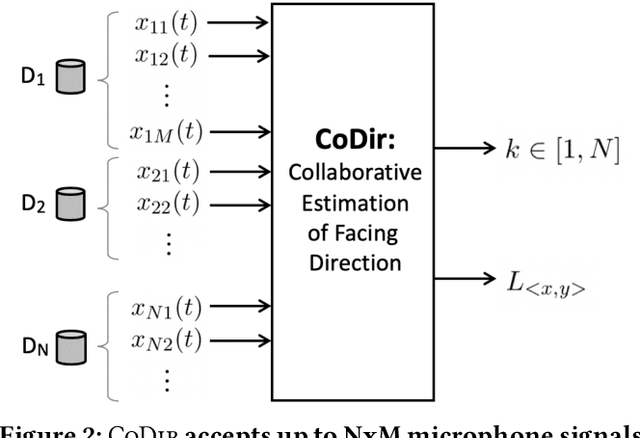
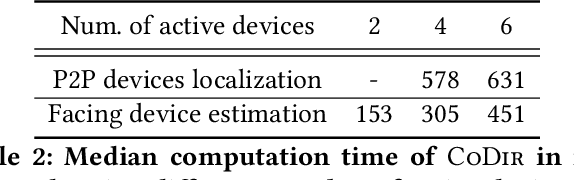
Consider a home or office where multiple devices are running voice assistants (e.g., TVs, lights, ovens, refrigerators, etc.). A human user turns to a particular device and gives a voice command, such as ``Alexa, can you ...''. This paper focuses on the problem of detecting which device the user was facing, and therefore, enabling only that device to respond to the command. Our core intuition emerges from the fact that human voice exhibits a directional radiation pattern, and the orientation of this pattern should influence the signal received at each device. Unfortunately, indoor multipath, unknown user location, and unknown voice signals pose as critical hurdles. Through a new algorithm that estimates the line-of-sight (LoS) power from a given signal, and combined with beamforming and triangulation, we design a functional solution called CoDIR. Results from $500+$ configurations, across $5$ rooms and $9$ different users, are encouraging. While improvements are necessary, we believe this is an important step forward in a challenging but urgent problem space.
Estimating Angle of Arrival (AoA) of multiple Echoes in a Steering Vector Space
Sep 27, 2021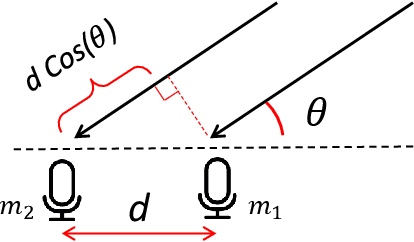

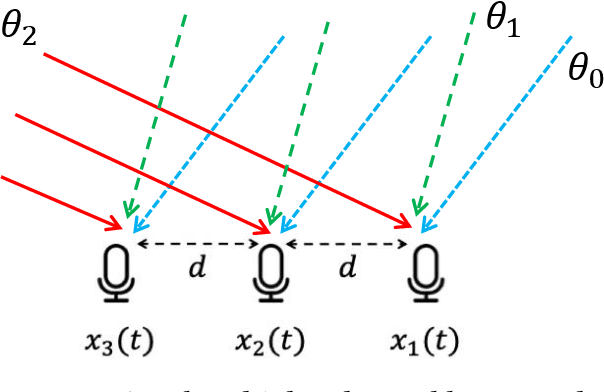

Consider a microphone array, such as those present in Amazon Echos, conference phones, or self-driving cars. One of the goals of these arrays is to decode the angles in which acoustic signals arrive at them. This paper considers the problem of estimating K angle of arrivals (AoA), i.e., the direct path's AoA and the AoA of subsequent echoes. Significant progress has been made on this problem, however, solutions remain elusive when the source signal is unknown (such as human voice) and the channel is strongly correlated (such as in multipath settings). Today's algorithms reliably estimate the direct-path-AoA, but the subsequent AoAs diverge in noisy real-world conditions. We design SubAoA, an algorithm that improves on the current body of work. Our core idea models signal in a new AoA sub-space, and employs a cancellation approach that successively cancels each AoA to decode the next. We explain the behavior and complexity of the algorithm from the first principles, simulate the performance across a range of parameters, and present results from real-world experiments. Comparison against multiple existing algorithms like GCC-PHAT, MUSIC, and VoLoc shows increasing gains for the latter AoAs, while our computation complexity allows real-time operation. We believe progress in multi-AoA estimation is a fundamental building block to various acoustic and RF applications, including human or vehicle localization, multi-user separation, and even (blind) channel estimation.
We Can "See" You via Wi-Fi - WiFi Action Recognition via Vision-based Methods
Apr 03, 2017
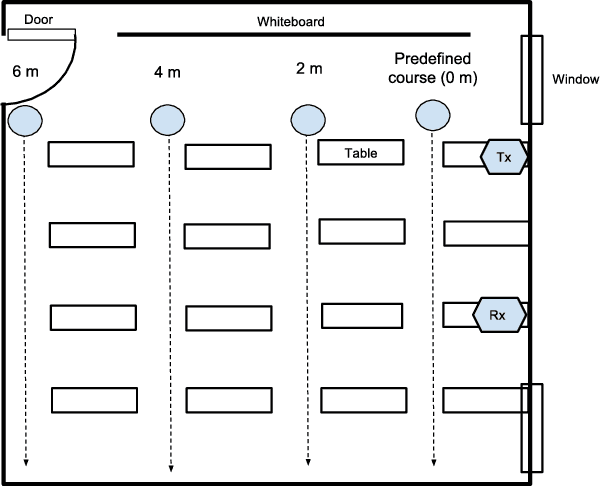

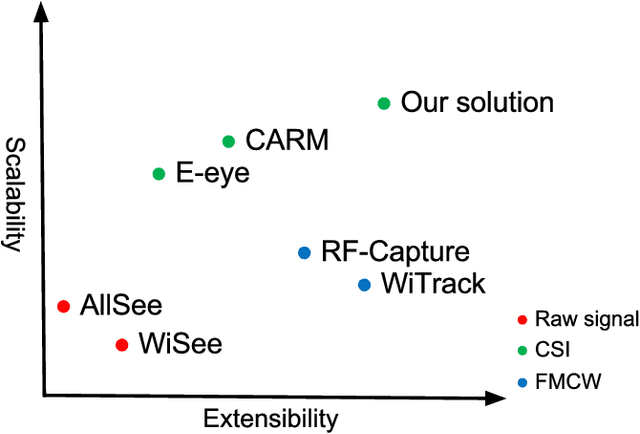
Recently, Wi-Fi has caught tremendous attention for its ubiquity, and, motivated by Wi-Fi's low cost and privacy preservation, researchers have been putting lots of investigation into its potential on action recognition and even person identification. In this paper, we offer an comprehensive overview on these two topics in Wi-Fi. Also, through looking at these two topics from an unprecedented perspective, we could achieve generality instead of designing specific ad-hoc features for each scenario. Observing the great resemblance of Channel State Information (CSI, a fine-grained information captured from the received Wi-Fi signal) to texture, we proposed a brand-new framework based on computer vision methods. To minimize the effect of location dependency embedded in CSI, we propose a novel de-noising method based on Singular Value Decomposition (SVD) to eliminate the background energy and effectively extract the channel information of signals reflected by human bodies. From the experiments conducted, we demonstrate the feasibility and efficacy of the proposed methods. Also, we conclude factors that would affect the performance and highlight a few promising issues that require further deliberation.