 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo Dataset Generation for Out-of-Domain Multi-Camera View Recommendation
Oct 17, 2024



Multi-camera systems are indispensable in movies, TV shows, and other media. Selecting the appropriate camera at every timestamp has a decisive impact on production quality and audience preferences. Learning-based view recommendation frameworks can assist professionals in decision-making. However, they often struggle outside of their training domains. The scarcity of labeled multi-camera view recommendation datasets exacerbates the issue. Based on the insight that many videos are edited from the original multi-camera videos, we propose transforming regular videos into pseudo-labeled multi-camera view recommendation datasets. Promisingly, by training the model on pseudo-labeled datasets stemming from videos in the target domain, we achieve a 68% relative improvement in the model's accuracy in the target domain and bridge the accuracy gap between in-domain and never-before-seen domains.
Do Pre-trained Models Benefit Equally in Continual Learning?
Oct 27, 2022



Existing work on continual learning (CL) is primarily devoted to developing algorithms for models trained from scratch. Despite their encouraging performance on contrived benchmarks, these algorithms show dramatic performance drops in real-world scenarios. Therefore, this paper advocates the systematic introduction of pre-training to CL, which is a general recipe for transferring knowledge to downstream tasks but is substantially missing in the CL community. Our investigation reveals the multifaceted complexity of exploiting pre-trained models for CL, along three different axes, pre-trained models, CL algorithms, and CL scenarios. Perhaps most intriguingly, improvements in CL algorithms from pre-training are very inconsistent an underperforming algorithm could become competitive and even state-of-the-art when all algorithms start from a pre-trained model. This indicates that the current paradigm, where all CL methods are compared in from-scratch training, is not well reflective of the true CL objective and desired progress. In addition, we make several other important observations, including that CL algorithms that exert less regularization benefit more from a pre-trained model; and that a stronger pre-trained model such as CLIP does not guarantee a better improvement. Based on these findings, we introduce a simple yet effective baseline that employs minimum regularization and leverages the more beneficial pre-trained model, coupled with a two-stage training pipeline. We recommend including this strong baseline in the future development of CL algorithms, due to its demonstrated state-of-the-art performance.
E-commerce Query-based Generation based on User Review
Nov 11, 2020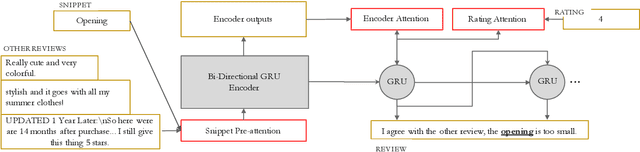
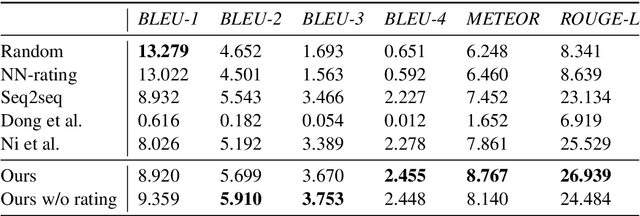
With the increasing number of merchandise on e-commerce platforms, users tend to refer to reviews of other shoppers to decide which product they should buy. However, with so many reviews of a product, users often have to spend lots of time browsing through reviews talking about product attributes they do not care about. We want to establish a system that can automatically summarize and answer user's product specific questions. In this study, we propose a novel seq2seq based text generation model to generate answers to user's question based on reviews posted by previous users. Given a user question and/or target sentiment polarity, we extract aspects of interest and generate an answer that summarizes previous relevant user reviews. Specifically, our model performs attention between input reviews and target aspects during encoding and is conditioned on both review rating and input context during decoding. We also incorporate a pre-trained auxiliary rating classifier to improve model performance and accelerate convergence during training. Experiments using real-world e-commerce dataset show that our model achieves improvement in performance compared to previously introduced models.
Learnable Gated Temporal Shift Module for Deep Video Inpainting
Jul 09, 2019
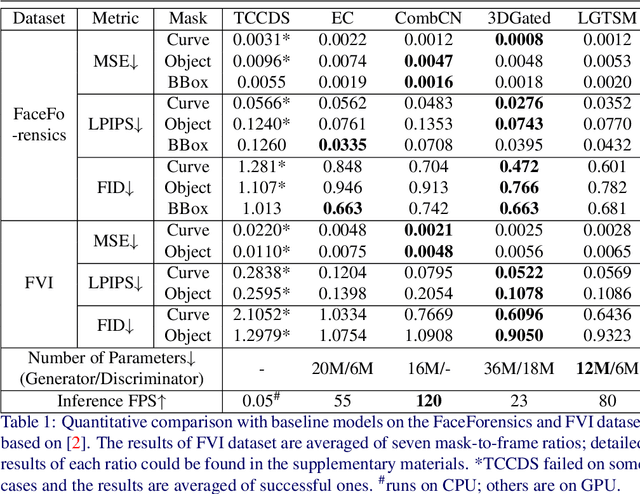
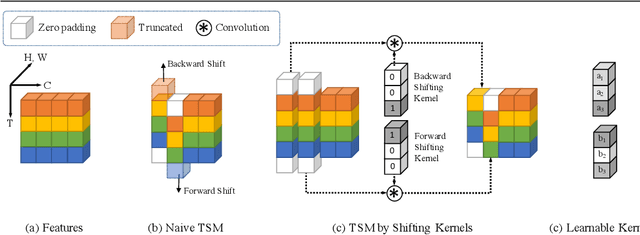
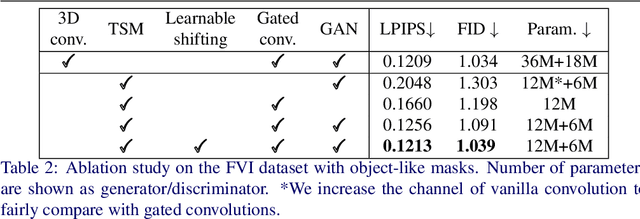
How to efficiently utilize temporal information to recover videos in a consistent way is the main issue for video inpainting problems. Conventional 2D CNNs have achieved good performance on image inpainting but often lead to temporally inconsistent results where frames will flicker when applied to videos (see https://www.youtube.com/watch?v=87Vh1HDBjD0&list=PLPoVtv-xp_dL5uckIzz1PKwNjg1yI0I94&index=1); 3D CNNs can capture temporal information but are computationally intensive and hard to train. In this paper, we present a novel component termed Learnable Gated Temporal Shift Module (LGTSM) for video inpainting models that could effectively tackle arbitrary video masks without additional parameters from 3D convolutions. LGTSM is designed to let 2D convolutions make use of neighboring frames more efficiently, which is crucial for video inpainting. Specifically, in each layer, LGTSM learns to shift some channels to its temporal neighbors so that 2D convolutions could be enhanced to handle temporal information. Meanwhile, a gated convolution is applied to the layer to identify the masked areas that are poisoning for conventional convolutions. On the FaceForensics and Free-form Video Inpainting (FVI) dataset, our model achieves state-of-the-art results with simply 33% of parameters and inference time.
Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN
Apr 28, 2019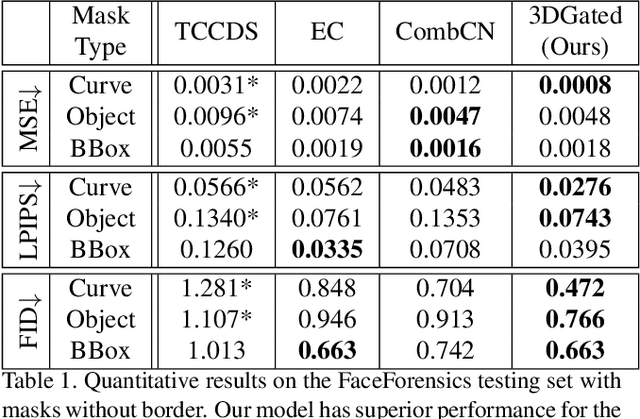
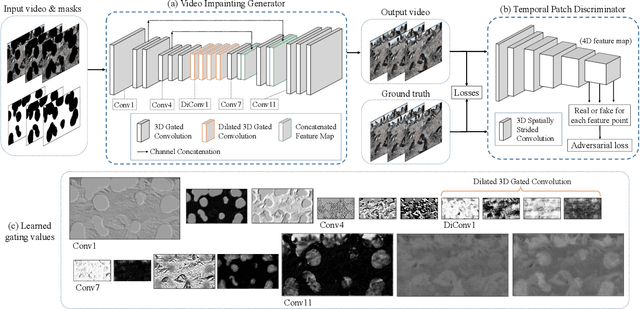
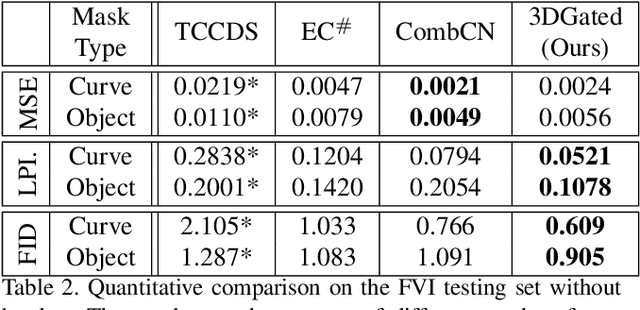
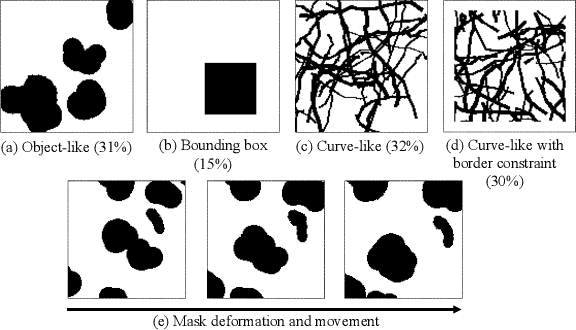
Free-form video inpainting is a very challenging task that could be widely used for video editing such as text removal. Existing patch-based methods could not handle non-repetitive structures such as faces, while directly applying image-based inpainting models to videos will result in temporal inconsistency (see http://bit.ly/2Fu1n6b). In this paper, we introduce a deep learn-ing based free-form video inpainting model, with proposed 3D gated convolutions to tackle the uncertainty of free-form masks and a novel Temporal PatchGAN loss to enhance temporal consistency. In addition, we collect videos and design a free-form mask generation algorithm to build the free-form video inpainting (FVI) dataset for training and evaluation of video inpainting models. We demonstrate the benefits of these components and experiments on both the FaceForensics and our FVI dataset suggest that our method is superior to existing ones.
We Can "See" You via Wi-Fi - WiFi Action Recognition via Vision-based Methods
Apr 03, 2017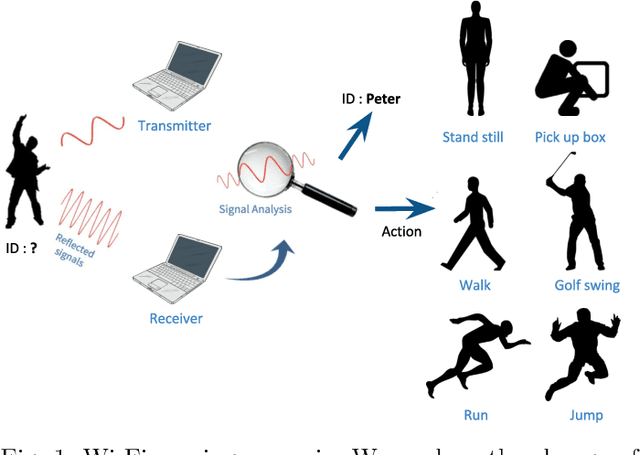
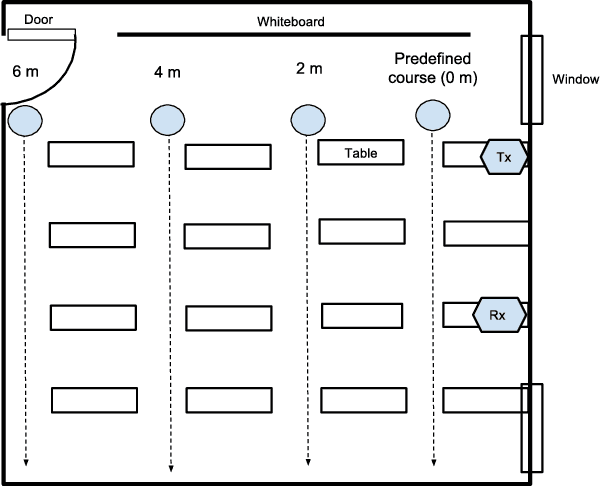

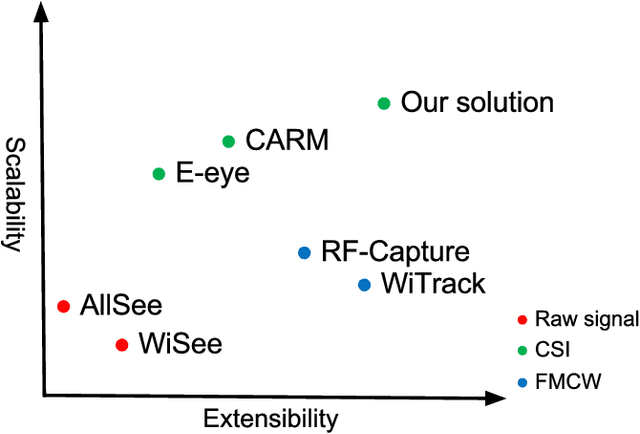
Recently, Wi-Fi has caught tremendous attention for its ubiquity, and, motivated by Wi-Fi's low cost and privacy preservation, researchers have been putting lots of investigation into its potential on action recognition and even person identification. In this paper, we offer an comprehensive overview on these two topics in Wi-Fi. Also, through looking at these two topics from an unprecedented perspective, we could achieve generality instead of designing specific ad-hoc features for each scenario. Observing the great resemblance of Channel State Information (CSI, a fine-grained information captured from the received Wi-Fi signal) to texture, we proposed a brand-new framework based on computer vision methods. To minimize the effect of location dependency embedded in CSI, we propose a novel de-noising method based on Singular Value Decomposition (SVD) to eliminate the background energy and effectively extract the channel information of signals reflected by human bodies. From the experiments conducted, we demonstrate the feasibility and efficacy of the proposed methods. Also, we conclude factors that would affect the performance and highlight a few promising issues that require further deliberation.